 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-depth Analysis on Caching and Pre-fetching in Mixture of Experts Offloading
Nov 08, 2025In today's landscape, Mixture of Experts (MoE) is a crucial architecture that has been used by many of the most advanced models. One of the major challenges of MoE models is that they usually require much more memory than their dense counterparts due to their unique architecture, and hence are harder to deploy in environments with limited GPU memory, such as edge devices. MoE offloading is a promising technique proposed to overcome this challenge, especially if it is enhanced with caching and pre-fetching, but prior work stopped at suboptimal caching algorithm and offered limited insights. In this work, we study MoE offloading in depth and make the following contributions: 1. We analyze the expert activation and LRU caching behavior in detail and provide traces. 2. We propose LFU caching optimization based on our analysis and obtain strong improvements from LRU. 3. We implement and experiment speculative expert pre-fetching, providing detailed trace showing its huge potential . 4. In addition, our study extensively covers the behavior of the MoE architecture itself, offering information on the characteristic of the gating network and experts. This can inspire future work on the interpretation of MoE models and the development of pruning techniques for MoE architecture with minimal performance loss.
GTR-CoT: Graph Traversal as Visual Chain of Thought for Molecular Structure Recognition
Jun 09, 2025



Optical Chemical Structure Recognition (OCSR) is crucial for digitizing chemical knowledge by converting molecular images into machine-readable formats. While recent vision-language models (VLMs) have shown potential in this task, their image-captioning approach often struggles with complex molecular structures and inconsistent annotations. To overcome these challenges, we introduce GTR-Mol-VLM, a novel framework featuring two key innovations: (1) the \textit{Graph Traversal as Visual Chain of Thought} mechanism that emulates human reasoning by incrementally parsing molecular graphs through sequential atom-bond predictions, and (2) the data-centric principle of \textit{Faithfully Recognize What You've Seen}, which addresses the mismatch between abbreviated structures in images and their expanded annotations. To support model development, we constructed GTR-CoT-1.3M, a large-scale instruction-tuning dataset with meticulously corrected annotations, and introduced MolRec-Bench, the first benchmark designed for a fine-grained evaluation of graph-parsing accuracy in OCSR. Comprehensive experiments demonstrate that GTR-Mol-VLM achieves superior results compared to specialist models, chemistry-domain VLMs, and commercial general-purpose VLMs. Notably, in scenarios involving molecular images with functional group abbreviations, GTR-Mol-VLM outperforms the second-best baseline by approximately 14 percentage points, both in SMILES-based and graph-based metrics. We hope that this work will drive OCSR technology to more effectively meet real-world needs, thereby advancing the fields of cheminformatics and AI for Science. We will release GTR-CoT at https://github.com/opendatalab/GTR-CoT.
Evaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025



We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .
Tip of the Tongue Query Elicitation for Simulated Evaluation
Feb 25, 2025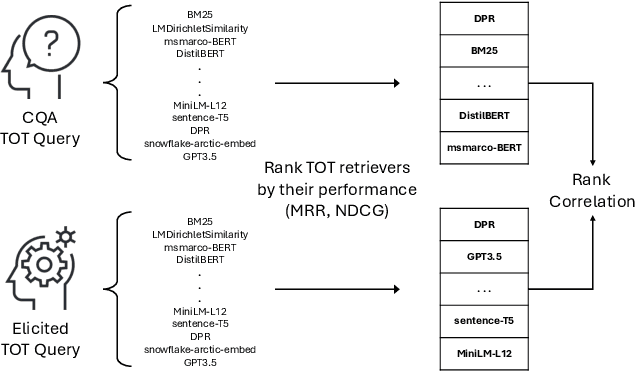
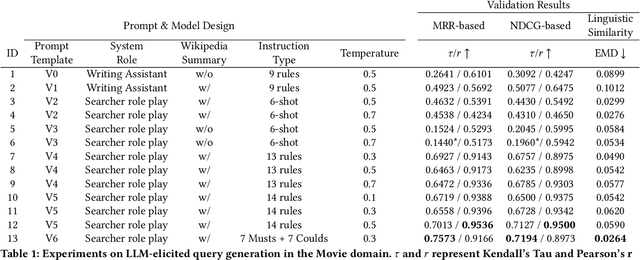
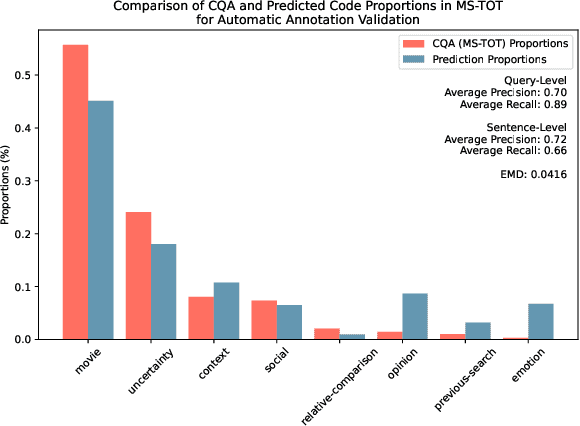

Tip-of-the-tongue (TOT) search occurs when a user struggles to recall a specific identifier, such as a document title. While common, existing search systems often fail to effectively support TOT scenarios. Research on TOT retrieval is further constrained by the challenge of collecting queries, as current approaches rely heavily on community question-answering (CQA) websites, leading to labor-intensive evaluation and domain bias. To overcome these limitations, we introduce two methods for eliciting TOT queries - leveraging large language models (LLMs) and human participants - to facilitate simulated evaluations of TOT retrieval systems. Our LLM-based TOT user simulator generates synthetic TOT queries at scale, achieving high correlations with how CQA-based TOT queries rank TOT retrieval systems when tested in the Movie domain. Additionally, these synthetic queries exhibit high linguistic similarity to CQA-derived queries. For human-elicited queries, we developed an interface that uses visual stimuli to place participants in a TOT state, enabling the collection of natural queries. In the Movie domain, system rank correlation and linguistic similarity analyses confirm that human-elicited queries are both effective and closely resemble CQA-based queries. These approaches reduce reliance on CQA-based data collection while expanding coverage to underrepresented domains, such as Landmark and Person. LLM-elicited queries for the Movie, Landmark, and Person domains have been released as test queries in the TREC 2024 TOT track, with human-elicited queries scheduled for inclusion in the TREC 2025 TOT track. Additionally, we provide source code for synthetic query generation and the human query collection interface, along with curated visual stimuli used for eliciting TOT queries.
Adaptive Activation Steering: A Tuning-Free LLM Truthfulness Improvement Method for Diverse Hallucinations Categories
May 26, 2024Recent studies have indicated that Large Language Models (LLMs) harbor an inherent understanding of truthfulness, yet often fail to express fully and generate false statements. This gap between "knowing" and "telling" poses a challenge for ensuring the truthfulness of generated content. To address this, we introduce Adaptive Activation Steering (ACT), a tuning-free method that adaptively shift LLM's activations in "truthful" direction during inference. ACT addresses diverse categories of hallucinations by utilizing diverse steering vectors and adjusting the steering intensity adaptively. Applied as an add-on across various models, ACT significantly improves truthfulness in LLaMA ($\uparrow$ 142\%), LLaMA2 ($\uparrow$ 24\%), Alpaca ($\uparrow$ 36\%), Vicuna ($\uparrow$ 28\%), and LLaMA2-Chat ($\uparrow$ 19\%). Furthermore, we verify ACT's scalability across larger models (13B, 33B, 65B), underscoring the adaptability of ACT to large-scale language models.
Evolving Benchmark Functions to Compare Evolutionary Algorithms via Genetic Programming
Mar 21, 2024



In this study, we use Genetic Programming (GP) to compose new optimization benchmark functions. Optimization benchmarks have the important role of showing the differences between evolutionary algorithms, making it possible for further analysis and comparisons. We show that the benchmarks generated by GP are able to differentiate algorithms better than human-made benchmark functions. The fitness measure of the GP is the Wasserstein distance of the solutions found by a pair of optimizers. Additionally, we use MAP-Elites to both enhance the search power of the GP and also illustrate how the difference between optimizers changes by various landscape features. Our approach provides a novel way to automate the design of benchmark functions and to compare evolutionary algorithms.
A Multilevel Guidance-Exploration Network and Behavior-Scene Matching Method for Human Behavior Anomaly Detection
Dec 07, 2023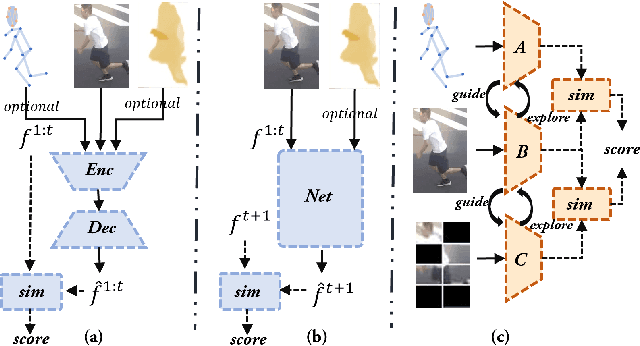
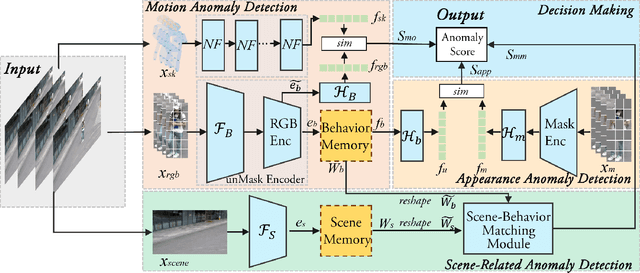
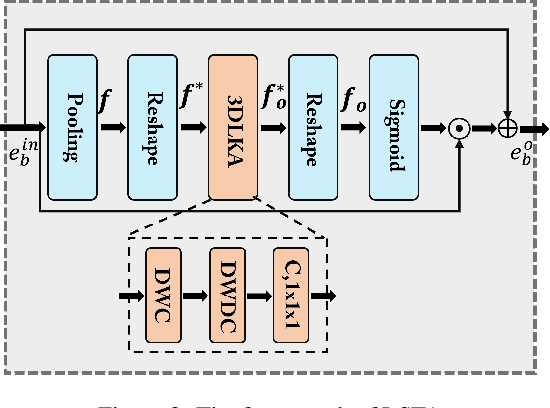
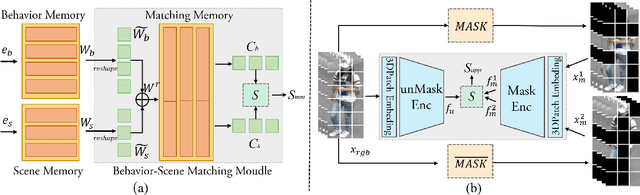
Human behavior anomaly detection aims to identify unusual human actions, playing a crucial role in intelligent surveillance and other areas. The current mainstream methods still adopt reconstruction or future frame prediction techniques. However, reconstructing or predicting low-level pixel features easily enables the network to achieve overly strong generalization ability, allowing anomalies to be reconstructed or predicted as effectively as normal data. Different from their methods, inspired by the Student-Teacher Network, we propose a novel framework called the Multilevel Guidance-Exploration Network(MGENet), which detects anomalies through the difference in high-level representation between the Guidance and Exploration network. Specifically, we first utilize the pre-trained Normalizing Flow that takes skeletal keypoints as input to guide an RGB encoder, which takes unmasked RGB frames as input, to explore motion latent features. Then, the RGB encoder guides the mask encoder, which takes masked RGB frames as input, to explore the latent appearance feature. Additionally, we design a Behavior-Scene Matching Module(BSMM) to detect scene-related behavioral anomalies. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performance on ShanghaiTech and UBnormal datasets, with AUC of 86.9 % and 73.5 %, respectively. The code will be available on https://github.com/molu-ggg/GENet.
Noisy Label Detection for Speaker Recognition
Dec 01, 2022The success of deep neural networks requires both high annotation quality and massive data. However, the size and the quality of a dataset are usually a trade-off in practice, as data collection and cleaning are expensive and time-consuming. Therefore, automatic noisy label detection (NLD) techniques are critical to real-world applications, especially those using crowdsourcing datasets. As this is an under-explored topic in automatic speaker verification (ASV), we present a simple but effective solution to the task. First, we compare the effectiveness of various commonly used metric learning loss functions under different noise settings. Then, we propose two ranking-based NLD methods, inter-class inconsistency and intra-class inconsistency ranking. They leverage the inconsistent nature of noisy labels and show high detection precision even under a high level of noise. Our solution gives rise to both efficient and effective cleaning of large-scale speaker recognition datasets.
Text-Aware Dual Routing Network for Visual Question Answering
Nov 17, 2022



Visual question answering (VQA) is a challenging task to provide an accurate natural language answer given an image and a natural language question about the image. It involves multi-modal learning, i.e., computer vision (CV) and natural language processing (NLP), as well as flexible answer prediction for free-form and open-ended answers. Existing approaches often fail in cases that require reading and understanding text in images to answer questions. In practice, they cannot effectively handle the answer sequence derived from text tokens because the visual features are not text-oriented. To address the above issues, we propose a Text-Aware Dual Routing Network (TDR) which simultaneously handles the VQA cases with and without understanding text information in the input images. Specifically, we build a two-branch answer prediction network that contains a specific branch for each case and further develop a dual routing scheme to dynamically determine which branch should be chosen. In the branch that involves text understanding, we incorporate the Optical Character Recognition (OCR) features into the model to help understand the text in the images. Extensive experiments on the VQA v2.0 dataset demonstrate that our proposed TDR outperforms existing methods, especially on the ''number'' related VQA questions.
Knowledge-Driven Program Synthesis via Adaptive Replacement Mutation and Auto-constructed Subprogram Archives
Sep 08, 2022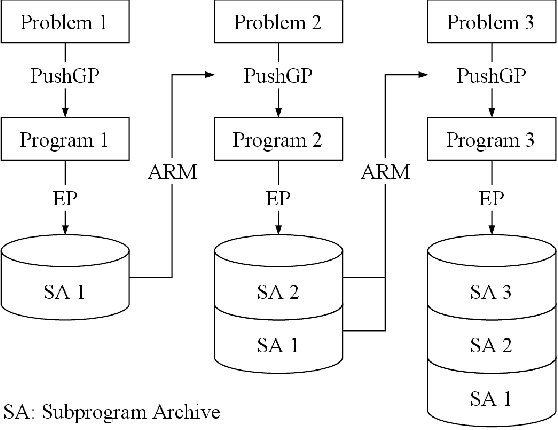



We introduce Knowledge-Driven Program Synthesis (KDPS) as a variant of the program synthesis task that requires the agent to solve a sequence of program synthesis problems. In KDPS, the agent should use knowledge from the earlier problems to solve the later ones. We propose a novel method based on PushGP to solve the KDPS problem, which takes subprograms as knowledge. The proposed method extracts subprograms from the solution of previously solved problems by the Even Partitioning (EP) method and uses these subprograms to solve the upcoming programming task using Adaptive Replacement Mutation (ARM). We call this method PushGP+EP+ARM. With PushGP+EP+ARM, no human effort is required in the knowledge extraction and utilization processes. We compare the proposed method with PushGP, as well as a method using subprograms manually extracted by a human. Our PushGP+EP+ARM achieves better train error, success count, and faster convergence than PushGP. Additionally, we demonstrate the superiority of PushGP+EP+ARM when consecutively solving a sequence of six program synthesis problems.