 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new type of federated clustering: A non-model-sharing approach
Jun 11, 2025In recent years, the growing need to leverage sensitive data across institutions has led to increased attention on federated learning (FL), a decentralized machine learning paradigm that enables model training without sharing raw data. However, existing FL-based clustering methods, known as federated clustering, typically assume simple data partitioning scenarios such as horizontal or vertical splits, and cannot handle more complex distributed structures. This study proposes data collaboration clustering (DC-Clustering), a novel federated clustering method that supports clustering over complex data partitioning scenarios where horizontal and vertical splits coexist. In DC-Clustering, each institution shares only intermediate representations instead of raw data, ensuring privacy preservation while enabling collaborative clustering. The method allows flexible selection between k-means and spectral clustering, and achieves final results with a single round of communication with the central server. We conducted extensive experiments using synthetic and open benchmark datasets. The results show that our method achieves clustering performance comparable to centralized clustering where all data are pooled. DC-Clustering addresses an important gap in current FL research by enabling effective knowledge discovery from distributed heterogeneous data. Its practical properties -- privacy preservation, communication efficiency, and flexibility -- make it a promising tool for privacy-sensitive domains such as healthcare and finance.
FedDCL: a federated data collaboration learning as a hybrid-type privacy-preserving framework based on federated learning and data collaboration
Sep 27, 2024Recently, federated learning has attracted much attention as a privacy-preserving integrated analysis that enables integrated analysis of data held by multiple institutions without sharing raw data. On the other hand, federated learning requires iterative communication across institutions and has a big challenge for implementation in situations where continuous communication with the outside world is extremely difficult. In this study, we propose a federated data collaboration learning (FedDCL), which solves such communication issues by combining federated learning with recently proposed non-model share-type federated learning named as data collaboration analysis. In the proposed FedDCL framework, each user institution independently constructs dimensionality-reduced intermediate representations and shares them with neighboring institutions on intra-group DC servers. On each intra-group DC server, intermediate representations are transformed to incorporable forms called collaboration representations. Federated learning is then conducted between intra-group DC servers. The proposed FedDCL framework does not require iterative communication by user institutions and can be implemented in situations where continuous communication with the outside world is extremely difficult. The experimental results show that the performance of the proposed FedDCL is comparable to that of existing federated learning.
MoFormer: Multi-objective Antimicrobial Peptide Generation Based on Conditional Transformer Joint Multi-modal Fusion Descriptor
Jun 03, 2024



Deep learning holds a big promise for optimizing existing peptides with more desirable properties, a critical step towards accelerating new drug discovery. Despite the recent emergence of several optimized Antimicrobial peptides(AMP) generation methods, multi-objective optimizations remain still quite challenging for the idealism-realism tradeoff. Here, we establish a multi-objective AMP synthesis pipeline (MoFormer) for the simultaneous optimization of multi-attributes of AMPs. MoFormer improves the desired attributes of AMP sequences in a highly structured latent space, guided by conditional constraints and fine-grained multi-descriptor.We show that MoFormer outperforms existing methods in the generation task of enhanced antimicrobial activity and minimal hemolysis. We also utilize a Pareto-based non-dominated sorting algorithm and proxies based on large model fine-tuning to hierarchically rank the candidates. We demonstrate substantial property improvement using MoFormer from two perspectives: (1) employing molecular simulations and scoring interactions among amino acids to decipher the structure and functionality of AMPs; (2) visualizing latent space to examine the qualities and distribution features, verifying an effective means to facilitate multi-objective optimization AMPs with design constraints
Estimation of conditional average treatment effects on distributed data: A privacy-preserving approach
Feb 05, 2024Estimation of conditional average treatment effects (CATEs) is an important topic in various fields such as medical and social sciences. CATEs can be estimated with high accuracy if distributed data across multiple parties can be centralized. However, it is difficult to aggregate such data if they contain privacy information. To address this issue, we proposed data collaboration double machine learning (DC-DML), a method that can estimate CATE models with privacy preservation of distributed data, and evaluated the method through numerical experiments. Our contributions are summarized in the following three points. First, our method enables estimation and testing of semi-parametric CATE models without iterative communication on distributed data. Semi-parametric or non-parametric CATE models enable estimation and testing that is more robust to model mis-specification than parametric models. However, to our knowledge, no communication-efficient method has been proposed for estimating and testing semi-parametric or non-parametric CATE models on distributed data. Second, our method enables collaborative estimation between different parties as well as multiple time points because the dimensionality-reduced intermediate representations can be accumulated. Third, our method performed as well or better than other methods in evaluation experiments using synthetic, semi-synthetic and real-world datasets.
Wasserstein Gradient Flow over Variational Parameter Space for Variational Inference
Oct 25, 2023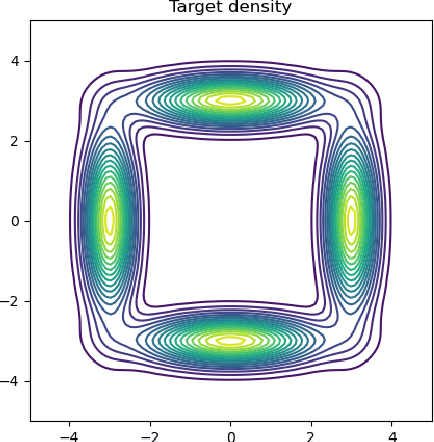
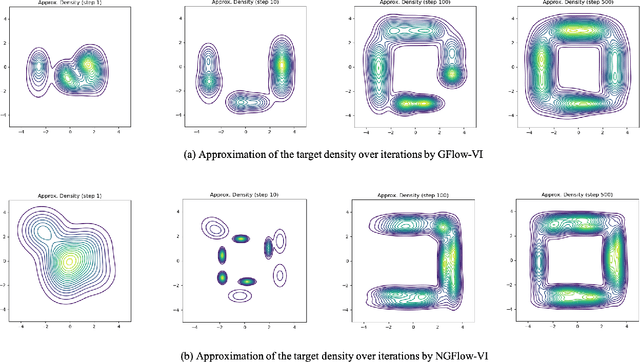
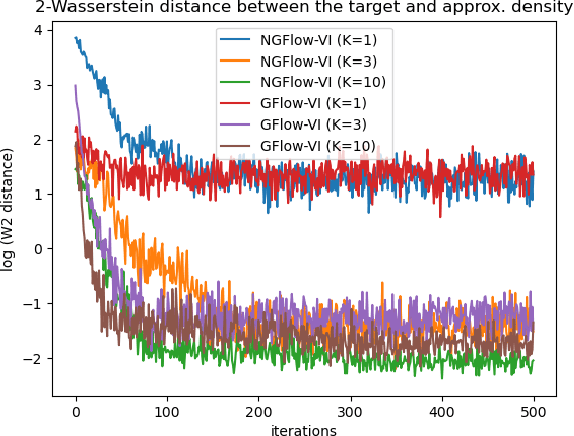
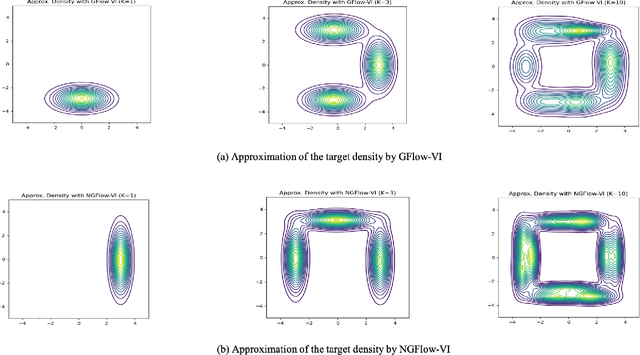
Variational inference (VI) can be cast as an optimization problem in which the variational parameters are tuned to closely align a variational distribution with the true posterior. The optimization task can be approached through vanilla gradient descent in black-box VI or natural-gradient descent in natural-gradient VI. In this work, we reframe VI as the optimization of an objective that concerns probability distributions defined over a \textit{variational parameter space}. Subsequently, we propose Wasserstein gradient descent for tackling this optimization problem. Notably, the optimization techniques, namely black-box VI and natural-gradient VI, can be reinterpreted as specific instances of the proposed Wasserstein gradient descent. To enhance the efficiency of optimization, we develop practical methods for numerically solving the discrete gradient flows. We validate the effectiveness of the proposed methods through empirical experiments on a synthetic dataset, supplemented by theoretical analyses.
Data Collaboration Analysis applied to Compound Datasets and the Introduction of Projection data to Non-IID settings
Aug 01, 2023Given the time and expense associated with bringing a drug to market, numerous studies have been conducted to predict the properties of compounds based on their structure using machine learning. Federated learning has been applied to compound datasets to increase their prediction accuracy while safeguarding potentially proprietary information. However, federated learning is encumbered by low accuracy in not identically and independently distributed (non-IID) settings, i.e., data partitioning has a large label bias, and is considered unsuitable for compound datasets, which tend to have large label bias. To address this limitation, we utilized an alternative method of distributed machine learning to chemical compound data from open sources, called data collaboration analysis (DC). We also proposed data collaboration analysis using projection data (DCPd), which is an improved method that utilizes auxiliary PubChem data. This improves the quality of individual user-side data transformations for the projection data for the creation of intermediate representations. The classification accuracy, i.e., area under the curve in the receiver operating characteristic curve (ROC-AUC) and AUC in the precision-recall curve (PR-AUC), of federated averaging (FedAvg), DC, and DCPd was compared for five compound datasets. We determined that the machine learning performance for non-IID settings was in the order of DCPd, DC, and FedAvg, although they were almost the same in identically and independently distributed (IID) settings. Moreover, the results showed that compared to other methods, DCPd exhibited a negligible decline in classification accuracy in experiments with different degrees of label bias. Thus, DCPd can address the low performance in non-IID settings, which is one of the challenges of federated learning.
Moreau-Yoshida Variational Transport: A General Framework For Solving Regularized Distributional Optimization Problems
Jul 31, 2023We consider a general optimization problem of minimizing a composite objective functional defined over a class of probability distributions. The objective is composed of two functionals: one is assumed to possess the variational representation and the other is expressed in terms of the expectation operator of a possibly nonsmooth convex regularizer function. Such a regularized distributional optimization problem widely appears in machine learning and statistics, such as proximal Monte-Carlo sampling, Bayesian inference and generative modeling, for regularized estimation and generation. We propose a novel method, dubbed as Moreau-Yoshida Variational Transport (MYVT), for solving the regularized distributional optimization problem. First, as the name suggests, our method employs the Moreau-Yoshida envelope for a smooth approximation of the nonsmooth function in the objective. Second, we reformulate the approximate problem as a concave-convex saddle point problem by leveraging the variational representation, and then develope an efficient primal-dual algorithm to approximate the saddle point. Furthermore, we provide theoretical analyses and report experimental results to demonstrate the effectiveness of the proposed method.
Achieving Transparency in Distributed Machine Learning with Explainable Data Collaboration
Dec 06, 2022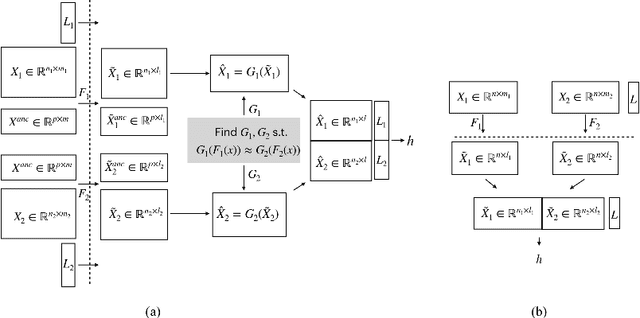
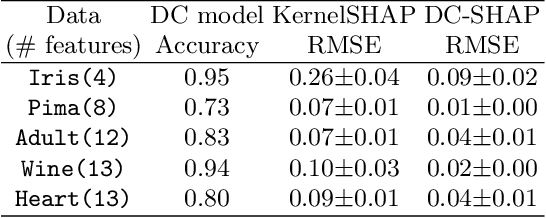
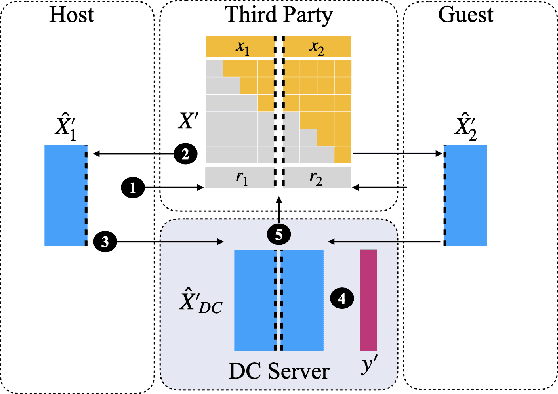
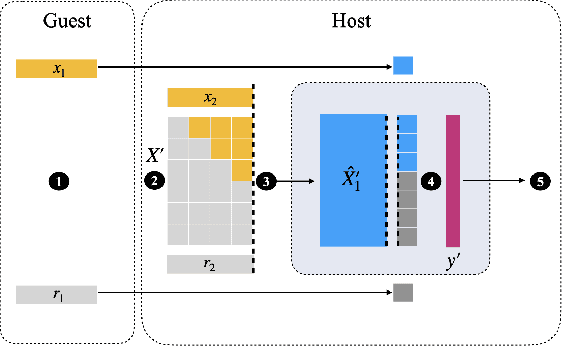
Transparency of Machine Learning models used for decision support in various industries becomes essential for ensuring their ethical use. To that end, feature attribution methods such as SHAP (SHapley Additive exPlanations) are widely used to explain the predictions of black-box machine learning models to customers and developers. However, a parallel trend has been to train machine learning models in collaboration with other data holders without accessing their data. Such models, trained over horizontally or vertically partitioned data, present a challenge for explainable AI because the explaining party may have a biased view of background data or a partial view of the feature space. As a result, explanations obtained from different participants of distributed machine learning might not be consistent with one another, undermining trust in the product. This paper presents an Explainable Data Collaboration Framework based on a model-agnostic additive feature attribution algorithm (KernelSHAP) and Data Collaboration method of privacy-preserving distributed machine learning. In particular, we present three algorithms for different scenarios of explainability in Data Collaboration and verify their consistency with experiments on open-access datasets. Our results demonstrated a significant (by at least a factor of 1.75) decrease in feature attribution discrepancies among the users of distributed machine learning.
Knowledge-Driven Program Synthesis via Adaptive Replacement Mutation and Auto-constructed Subprogram Archives
Sep 08, 2022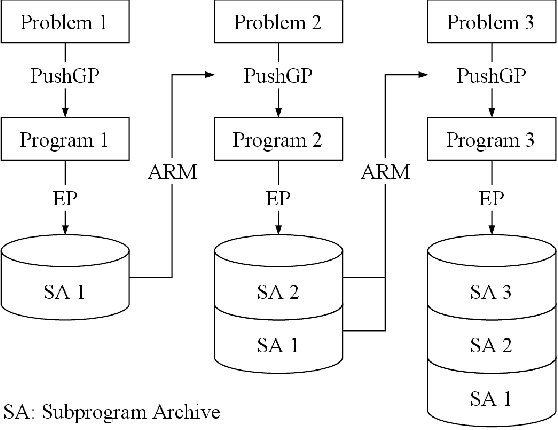



We introduce Knowledge-Driven Program Synthesis (KDPS) as a variant of the program synthesis task that requires the agent to solve a sequence of program synthesis problems. In KDPS, the agent should use knowledge from the earlier problems to solve the later ones. We propose a novel method based on PushGP to solve the KDPS problem, which takes subprograms as knowledge. The proposed method extracts subprograms from the solution of previously solved problems by the Even Partitioning (EP) method and uses these subprograms to solve the upcoming programming task using Adaptive Replacement Mutation (ARM). We call this method PushGP+EP+ARM. With PushGP+EP+ARM, no human effort is required in the knowledge extraction and utilization processes. We compare the proposed method with PushGP, as well as a method using subprograms manually extracted by a human. Our PushGP+EP+ARM achieves better train error, success count, and faster convergence than PushGP. Additionally, we demonstrate the superiority of PushGP+EP+ARM when consecutively solving a sequence of six program synthesis problems.
Non-readily identifiable data collaboration analysis for multiple datasets including personal information
Aug 31, 2022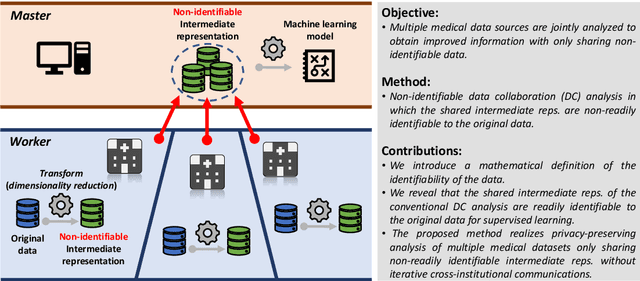
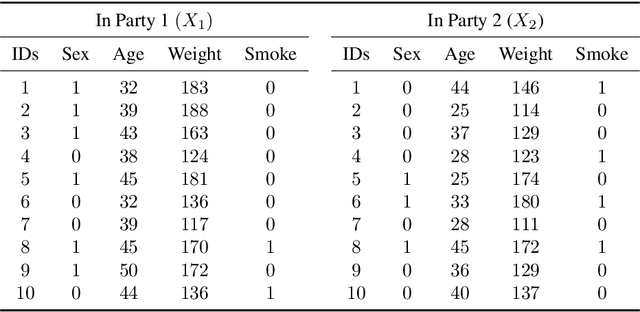
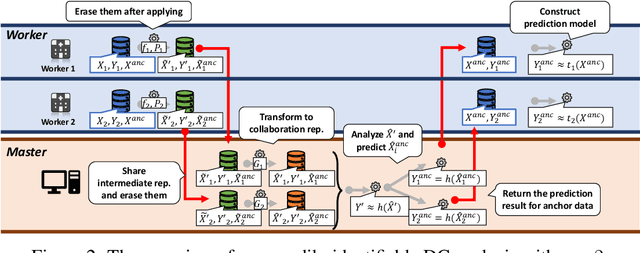
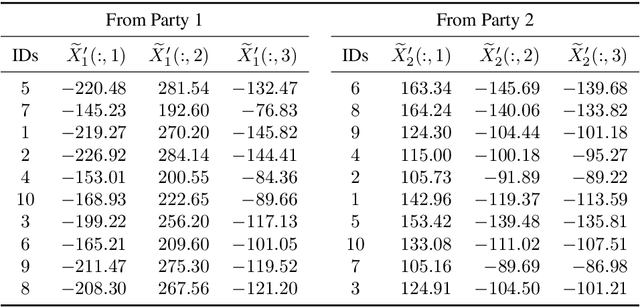
Multi-source data fusion, in which multiple data sources are jointly analyzed to obtain improved information, has considerable research attention. For the datasets of multiple medical institutions, data confidentiality and cross-institutional communication are critical. In such cases, data collaboration (DC) analysis by sharing dimensionality-reduced intermediate representations without iterative cross-institutional communications may be appropriate. Identifiability of the shared data is essential when analyzing data including personal information. In this study, the identifiability of the DC analysis is investigated. The results reveals that the shared intermediate representations are readily identifiable to the original data for supervised learning. This study then proposes a non-readily identifiable DC analysis only sharing non-readily identifiable data for multiple medical datasets including personal information. The proposed method solves identifiability concerns based on a random sample permutation, the concept of interpretable DC analysis, and usage of functions that cannot be reconstructed. In numerical experiments on medical datasets, the proposed method exhibits a non-readily identifiability while maintaining a high recognition performance of the conventional DC analysis. For a hospital dataset, the proposed method exhibits a nine percentage point improvement regarding the recognition performance over the local analysis that uses only local dataset.