 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Round Clustered Federated Learning via Data Collaboration Analysis for Non-IID Data
Jan 14, 2026Federated Learning (FL) enables distributed learning across multiple clients without sharing raw data. When statistical heterogeneity across clients is severe, Clustered Federated Learning (CFL) can improve performance by grouping similar clients and training cluster-wise models. However, most CFL approaches rely on multiple communication rounds for cluster estimation and model updates, which limits their practicality under tight constraints on communication rounds. We propose Data Collaboration-based Clustered Federated Learning (DC-CFL), a single-round framework that completes both client clustering and cluster-wise learning, using only the information shared in DC analysis. DC-CFL quantifies inter-client similarity via total variation distance between label distributions, estimates clusters using hierarchical clustering, and performs cluster-wise learning via DC analysis. Experiments on multiple open datasets under representative non-IID conditions show that DC-CFL achieves accuracy comparable to multi-round baselines while requiring only one communication round. These results indicate that DC-CFL is a practical alternative for collaborative AI model development when multiple communication rounds are impractical.
A new type of federated clustering: A non-model-sharing approach
Jun 11, 2025In recent years, the growing need to leverage sensitive data across institutions has led to increased attention on federated learning (FL), a decentralized machine learning paradigm that enables model training without sharing raw data. However, existing FL-based clustering methods, known as federated clustering, typically assume simple data partitioning scenarios such as horizontal or vertical splits, and cannot handle more complex distributed structures. This study proposes data collaboration clustering (DC-Clustering), a novel federated clustering method that supports clustering over complex data partitioning scenarios where horizontal and vertical splits coexist. In DC-Clustering, each institution shares only intermediate representations instead of raw data, ensuring privacy preservation while enabling collaborative clustering. The method allows flexible selection between k-means and spectral clustering, and achieves final results with a single round of communication with the central server. We conducted extensive experiments using synthetic and open benchmark datasets. The results show that our method achieves clustering performance comparable to centralized clustering where all data are pooled. DC-Clustering addresses an important gap in current FL research by enabling effective knowledge discovery from distributed heterogeneous data. Its practical properties -- privacy preservation, communication efficiency, and flexibility -- make it a promising tool for privacy-sensitive domains such as healthcare and finance.
Auto Tensor Singular Value Thresholding: A Non-Iterative and Rank-Free Framework for Tensor Denoising
May 09, 2025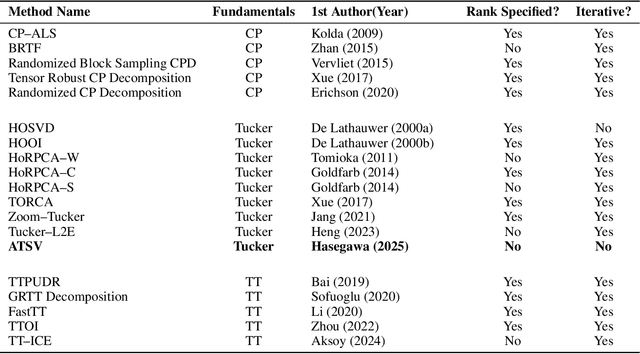
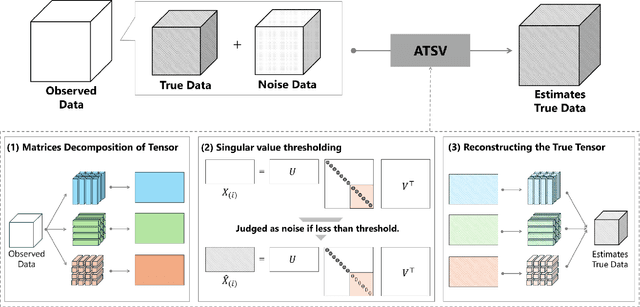
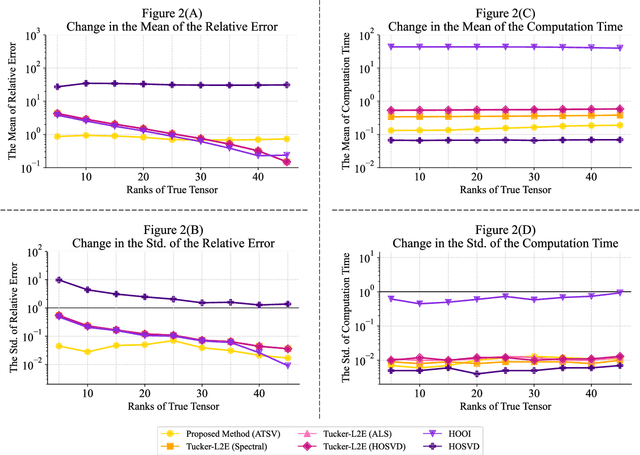
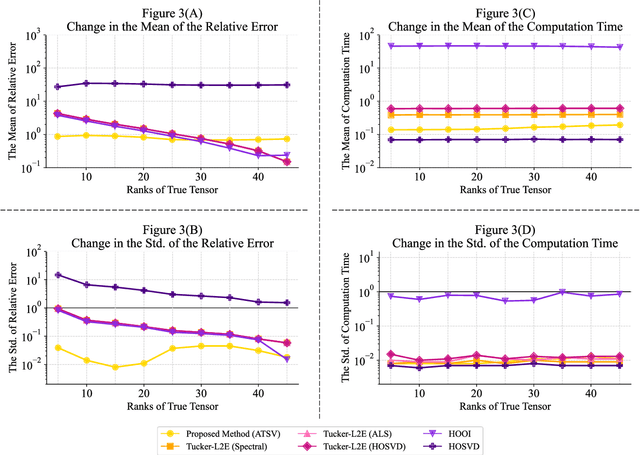
In modern data-driven tasks such as classification, optimization, and forecasting, mitigating the effects of intrinsic noise is crucial for improving predictive accuracy. While numerous denoising techniques have been developed, the rising dimensionality of real-world datasets limits conventional matrix-based methods in preserving data structure and accuracy. This challenge has led to increasing interest in tensor-based approaches, which naturally capture multi-way data relationships. However, classical tensor decomposition methods (e.g., HOSVD, HOOI) typically require pre-specified ranks and iterative optimization, making them computationally expensive and less practical. In this work, we propose a novel low-rank approximation method for tensor data that avoids these limitations. Our approach applies statistically grounded singular value thresholding to mode-wise matricizations, enabling automatic extraction of significant components without requiring prior rank specification or iterative refinement. Experiments on synthetic and real-world tensors show that our method consistently outperforms existing techniques in terms of estimation accuracy and computational efficiency, especially in noisy high-dimensional settings.
Estimation of conditional average treatment effects on distributed data: A privacy-preserving approach
Feb 05, 2024Estimation of conditional average treatment effects (CATEs) is an important topic in various fields such as medical and social sciences. CATEs can be estimated with high accuracy if distributed data across multiple parties can be centralized. However, it is difficult to aggregate such data if they contain privacy information. To address this issue, we proposed data collaboration double machine learning (DC-DML), a method that can estimate CATE models with privacy preservation of distributed data, and evaluated the method through numerical experiments. Our contributions are summarized in the following three points. First, our method enables estimation and testing of semi-parametric CATE models without iterative communication on distributed data. Semi-parametric or non-parametric CATE models enable estimation and testing that is more robust to model mis-specification than parametric models. However, to our knowledge, no communication-efficient method has been proposed for estimating and testing semi-parametric or non-parametric CATE models on distributed data. Second, our method enables collaborative estimation between different parties as well as multiple time points because the dimensionality-reduced intermediate representations can be accumulated. Third, our method performed as well or better than other methods in evaluation experiments using synthetic, semi-synthetic and real-world datasets.
Non-readily identifiable data collaboration analysis for multiple datasets including personal information
Aug 31, 2022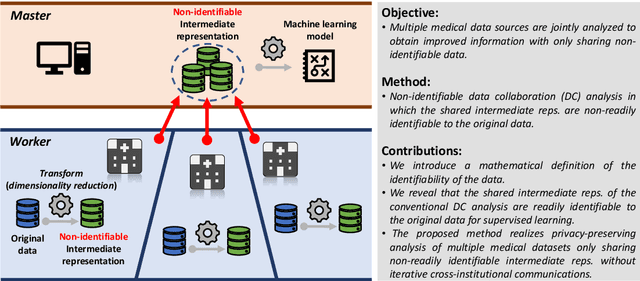
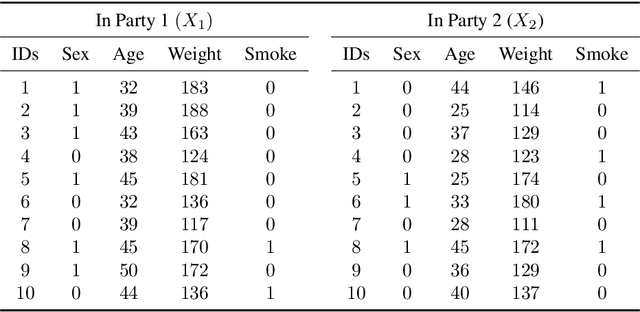
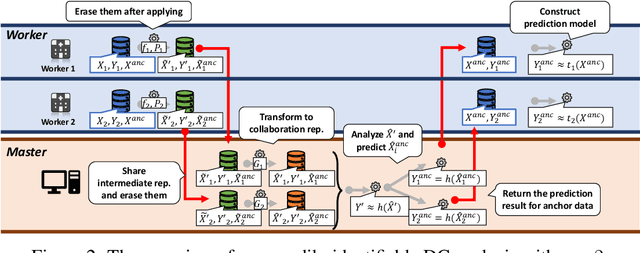
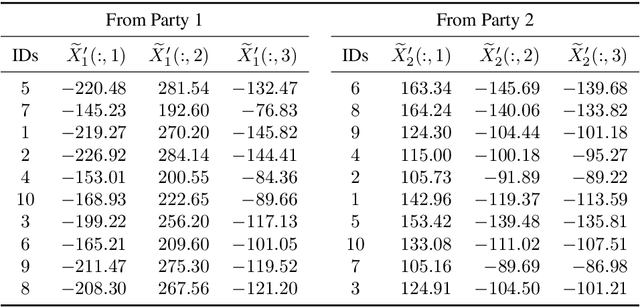
Multi-source data fusion, in which multiple data sources are jointly analyzed to obtain improved information, has considerable research attention. For the datasets of multiple medical institutions, data confidentiality and cross-institutional communication are critical. In such cases, data collaboration (DC) analysis by sharing dimensionality-reduced intermediate representations without iterative cross-institutional communications may be appropriate. Identifiability of the shared data is essential when analyzing data including personal information. In this study, the identifiability of the DC analysis is investigated. The results reveals that the shared intermediate representations are readily identifiable to the original data for supervised learning. This study then proposes a non-readily identifiable DC analysis only sharing non-readily identifiable data for multiple medical datasets including personal information. The proposed method solves identifiability concerns based on a random sample permutation, the concept of interpretable DC analysis, and usage of functions that cannot be reconstructed. In numerical experiments on medical datasets, the proposed method exhibits a non-readily identifiability while maintaining a high recognition performance of the conventional DC analysis. For a hospital dataset, the proposed method exhibits a nine percentage point improvement regarding the recognition performance over the local analysis that uses only local dataset.
Another Use of SMOTE for Interpretable Data Collaboration Analysis
Aug 26, 2022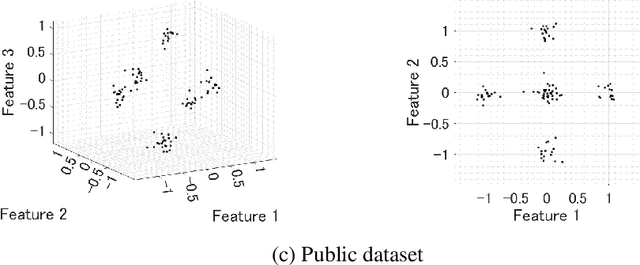
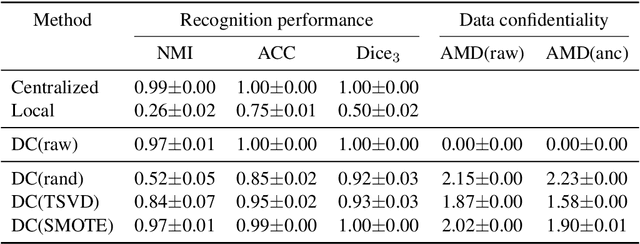
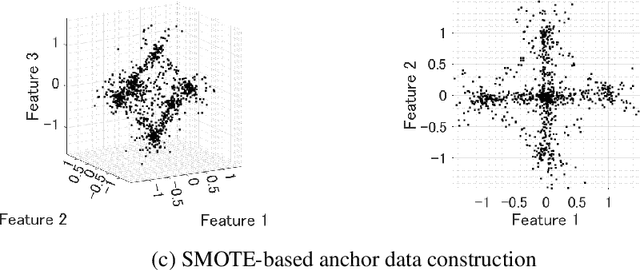
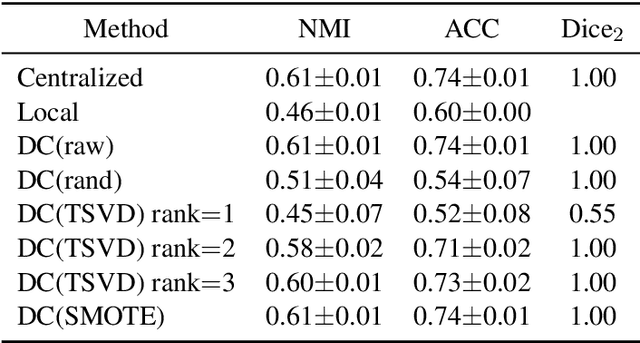
Recently, data collaboration (DC) analysis has been developed for privacy-preserving integrated analysis across multiple institutions. DC analysis centralizes individually constructed dimensionality-reduced intermediate representations and realizes integrated analysis via collaboration representations without sharing the original data. To construct the collaboration representations, each institution generates and shares a shareable anchor dataset and centralizes its intermediate representation. Although, random anchor dataset functions well for DC analysis in general, using an anchor dataset whose distribution is close to that of the raw dataset is expected to improve the recognition performance, particularly for the interpretable DC analysis. Based on an extension of the synthetic minority over-sampling technique (SMOTE), this study proposes an anchor data construction technique to improve the recognition performance without increasing the risk of data leakage. Numerical results demonstrate the efficiency of the proposed SMOTE-based method over the existing anchor data constructions for artificial and real-world datasets. Specifically, the proposed method achieves 9 percentage point and 38 percentage point performance improvements regarding accuracy and essential feature selection, respectively, over existing methods for an income dataset. The proposed method provides another use of SMOTE not for imbalanced data classifications but for a key technology of privacy-preserving integrated analysis.
Collaborative causal inference on distributed data
Aug 16, 2022
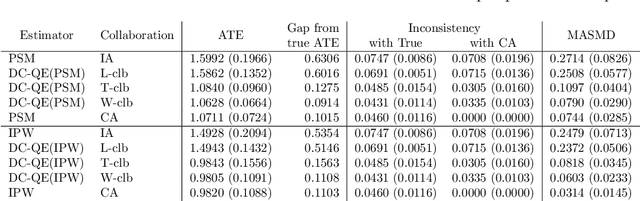
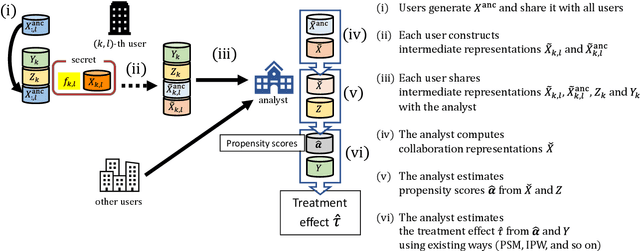
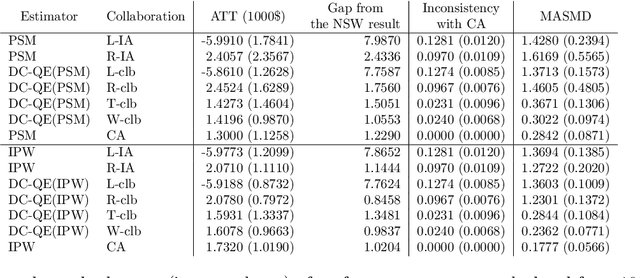
The development of technologies for causal inference with the privacy preservation of distributed data has attracted considerable attention in recent years. To address this issue, we propose a quasi-experiment based on data collaboration (DC-QE) that enables causal inference from distributed data with privacy preservation. Our method preserves the privacy of private data by sharing only dimensionality-reduced intermediate representations, which are individually constructed by each party. Moreover, our method can reduce both random errors and biases, whereas existing methods can only reduce random errors in the estimation of treatment effects. Through numerical experiments on both artificial and real-world data, we confirmed that our method can lead to better estimation results than individual analyses. With the spread of our method, intermediate representations can be published as open data to help researchers find causalities and accumulated as a knowledge base.
Application of Particle Swarm Optimization method to On-going Monitoring for estimating vehicle-bridge interaction system
Jan 20, 2022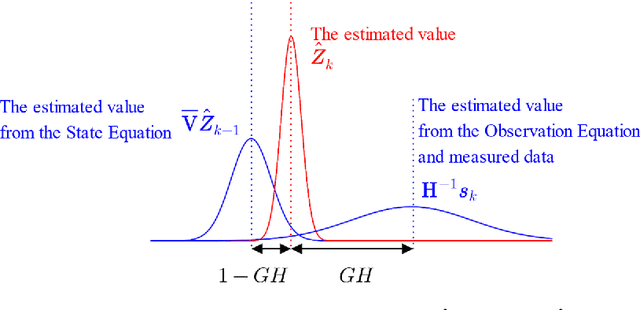
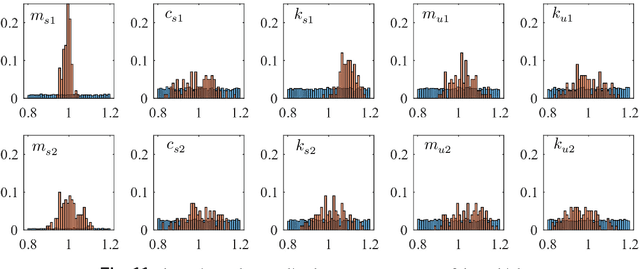
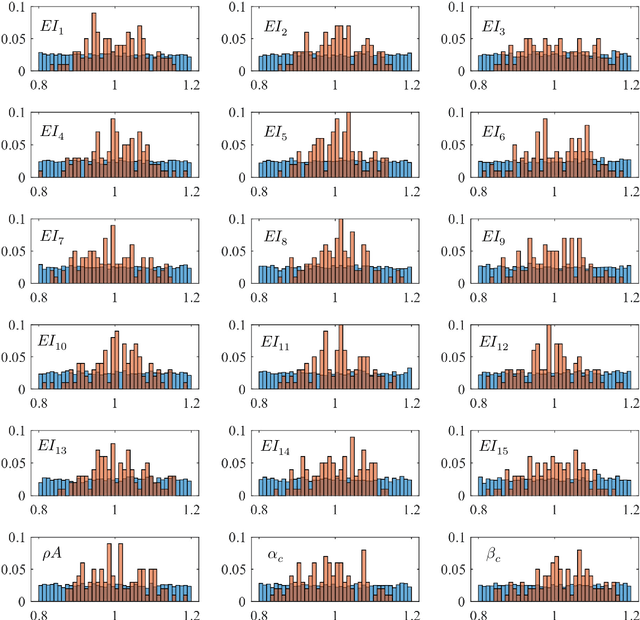
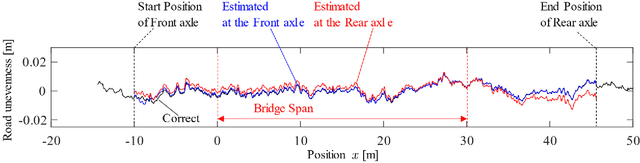
This study proposes a method for estimating the mechanical parameters of vehicles and bridges and the road unevenness, using only vehicle vibration and position data. In the proposed method, vehicle input and bridge vibration are estimated using randomly assumed vehicle and bridge parameters. Then, the road profiles at the front and rear wheels can be determined from the vehicle input and bridge vibration. The difference between the two road profiles is used as the objective function because they are expected to coincide when synchronized. Using the particle swarm optimization (PSO) method, the vehicle and bridge parameters and the road unevenness can be estimated by updating the parameters to minimize the objective function. Numerical experiments also verify the applicability of this method. In the numerical experiments, it is confirmed that the proposed method can estimate the vehicle weight with reasonable accuracy, but the accuracy of other parameters is not sufficient. It is necessary to improve the accuracy of the proposed method in the future.
Federated Learning System without Model Sharing through Integration of Dimensional Reduced Data Representations
Nov 13, 2020
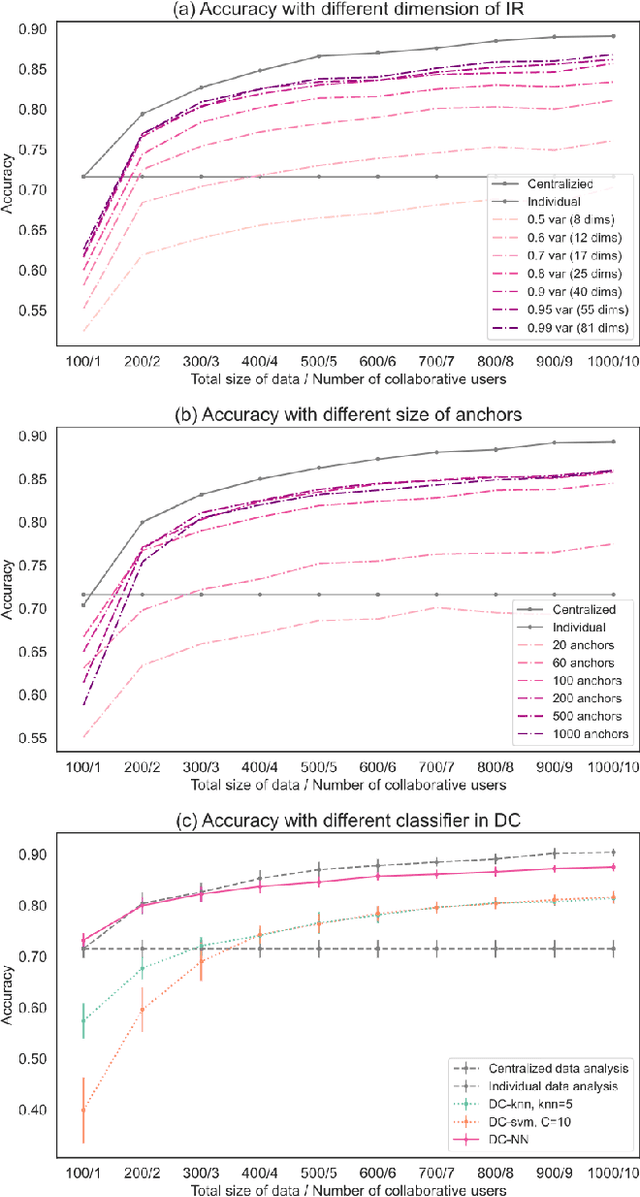
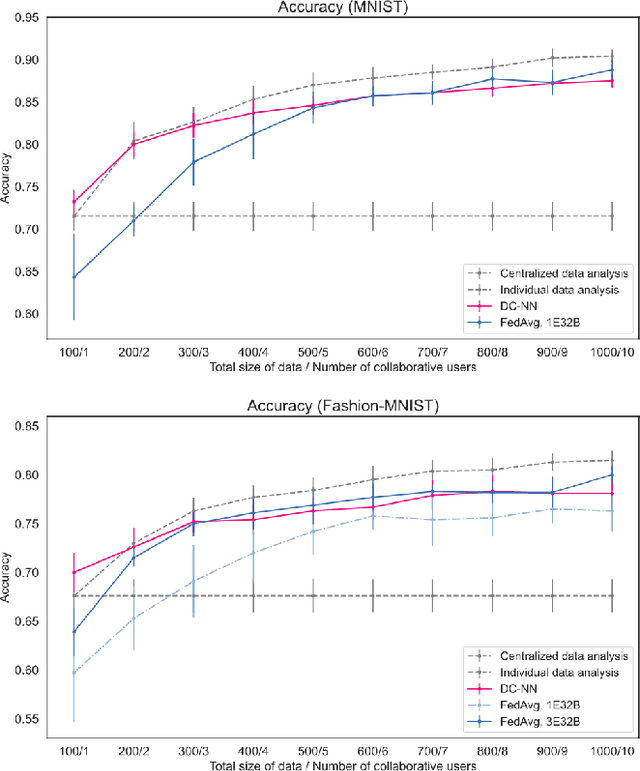
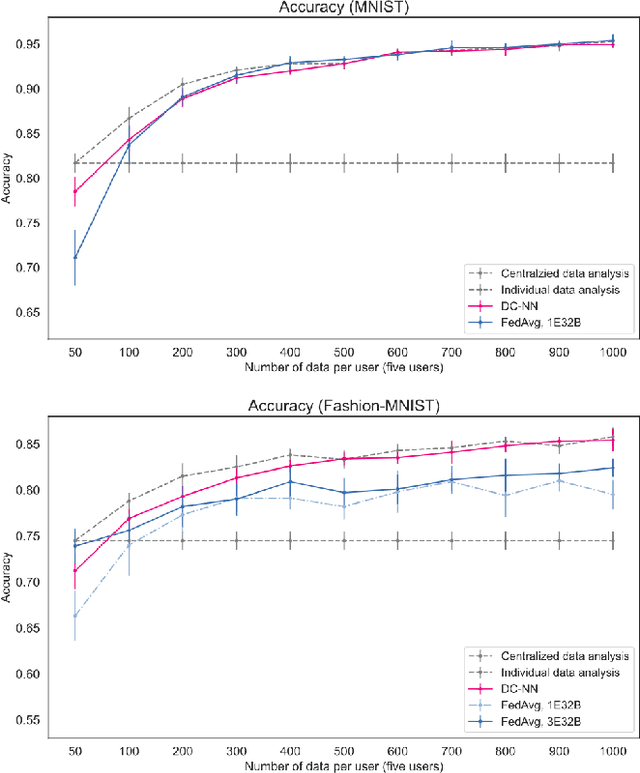
Dimensionality Reduction is a commonly used element in a machine learning pipeline that helps to extract important features from high-dimensional data. In this work, we explore an alternative federated learning system that enables integration of dimensionality reduced representations of distributed data prior to a supervised learning task, thus avoiding model sharing among the parties. We compare the performance of this approach on image classification tasks to three alternative frameworks: centralized machine learning, individual machine learning, and Federated Averaging, and analyze potential use cases for a federated learning system without model sharing. Our results show that our approach can achieve similar accuracy as Federated Averaging and performs better than Federated Averaging in a small-user setting.
Interpretable collaborative data analysis on distributed data
Nov 09, 2020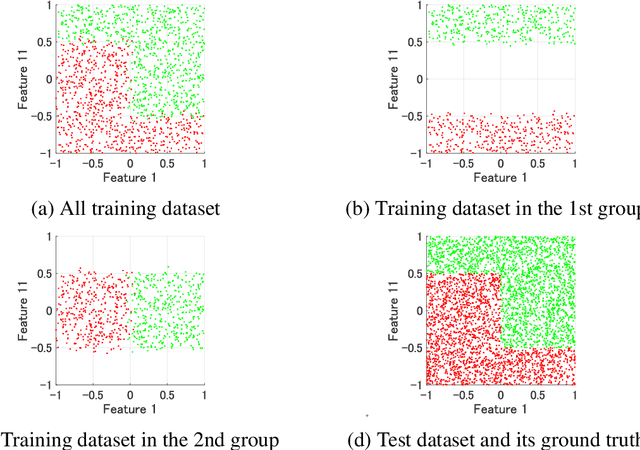

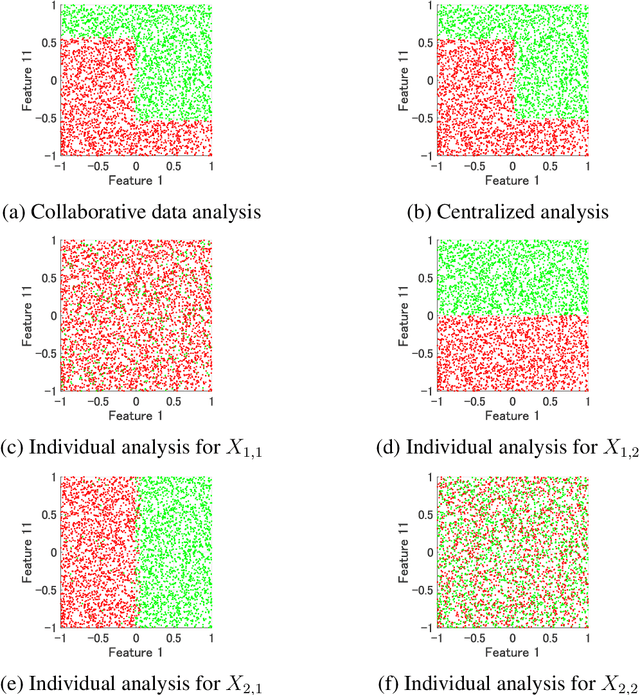

This paper proposes an interpretable non-model sharing collaborative data analysis method as one of the federated learning systems, which is an emerging technology to analyze distributed data. Analyzing distributed data is essential in many applications such as medical, financial, and manufacturing data analyses due to privacy, and confidentiality concerns. In addition, interpretability of the obtained model has an important role for practical applications of the federated learning systems. By centralizing intermediate representations, which are individually constructed in each party, the proposed method obtains an interpretable model, achieving a collaborative analysis without revealing the individual data and learning model distributed over local parties. Numerical experiments indicate that the proposed method achieves better recognition performance for artificial and real-world problems than individual analysis.