 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of conditional average treatment effects on distributed data: A privacy-preserving approach
Feb 05, 2024Estimation of conditional average treatment effects (CATEs) is an important topic in various fields such as medical and social sciences. CATEs can be estimated with high accuracy if distributed data across multiple parties can be centralized. However, it is difficult to aggregate such data if they contain privacy information. To address this issue, we proposed data collaboration double machine learning (DC-DML), a method that can estimate CATE models with privacy preservation of distributed data, and evaluated the method through numerical experiments. Our contributions are summarized in the following three points. First, our method enables estimation and testing of semi-parametric CATE models without iterative communication on distributed data. Semi-parametric or non-parametric CATE models enable estimation and testing that is more robust to model mis-specification than parametric models. However, to our knowledge, no communication-efficient method has been proposed for estimating and testing semi-parametric or non-parametric CATE models on distributed data. Second, our method enables collaborative estimation between different parties as well as multiple time points because the dimensionality-reduced intermediate representations can be accumulated. Third, our method performed as well or better than other methods in evaluation experiments using synthetic, semi-synthetic and real-world datasets.
Collaborative causal inference on distributed data
Aug 16, 2022
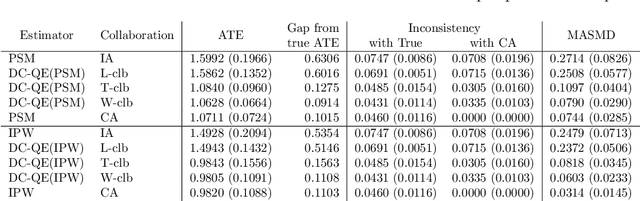
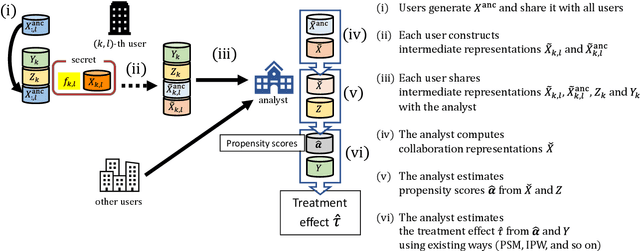
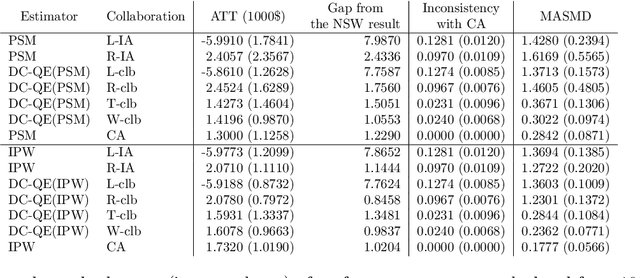
The development of technologies for causal inference with the privacy preservation of distributed data has attracted considerable attention in recent years. To address this issue, we propose a quasi-experiment based on data collaboration (DC-QE) that enables causal inference from distributed data with privacy preservation. Our method preserves the privacy of private data by sharing only dimensionality-reduced intermediate representations, which are individually constructed by each party. Moreover, our method can reduce both random errors and biases, whereas existing methods can only reduce random errors in the estimation of treatment effects. Through numerical experiments on both artificial and real-world data, we confirmed that our method can lead to better estimation results than individual analyses. With the spread of our method, intermediate representations can be published as open data to help researchers find causalities and accumulated as a knowledge base.