 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Transparency in Distributed Machine Learning with Explainable Data Collaboration
Dec 06, 2022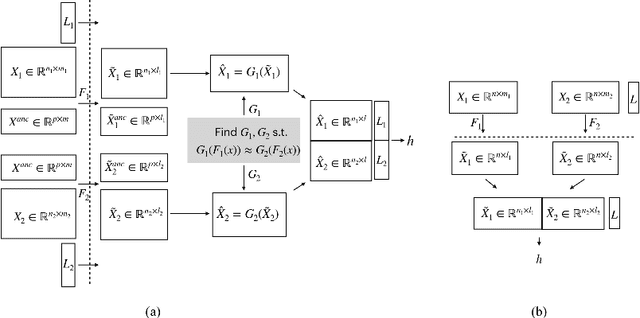
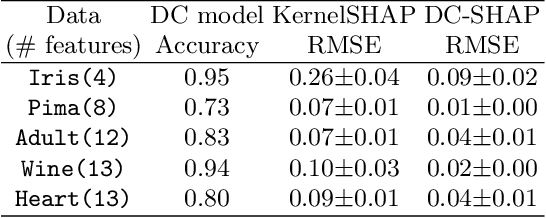
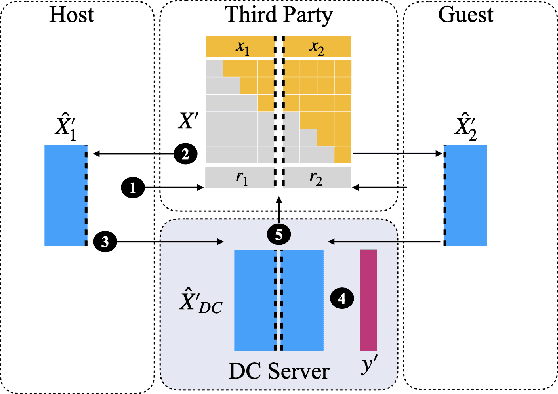
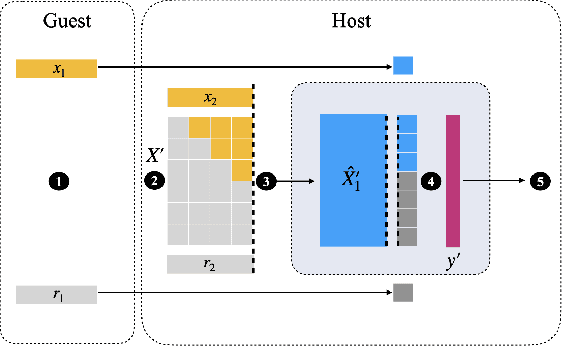
Transparency of Machine Learning models used for decision support in various industries becomes essential for ensuring their ethical use. To that end, feature attribution methods such as SHAP (SHapley Additive exPlanations) are widely used to explain the predictions of black-box machine learning models to customers and developers. However, a parallel trend has been to train machine learning models in collaboration with other data holders without accessing their data. Such models, trained over horizontally or vertically partitioned data, present a challenge for explainable AI because the explaining party may have a biased view of background data or a partial view of the feature space. As a result, explanations obtained from different participants of distributed machine learning might not be consistent with one another, undermining trust in the product. This paper presents an Explainable Data Collaboration Framework based on a model-agnostic additive feature attribution algorithm (KernelSHAP) and Data Collaboration method of privacy-preserving distributed machine learning. In particular, we present three algorithms for different scenarios of explainability in Data Collaboration and verify their consistency with experiments on open-access datasets. Our results demonstrated a significant (by at least a factor of 1.75) decrease in feature attribution discrepancies among the users of distributed machine learning.
Non-readily identifiable data collaboration analysis for multiple datasets including personal information
Aug 31, 2022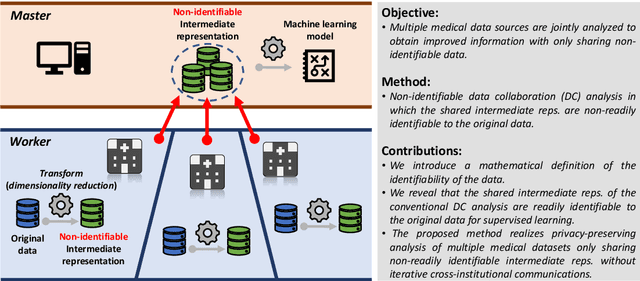
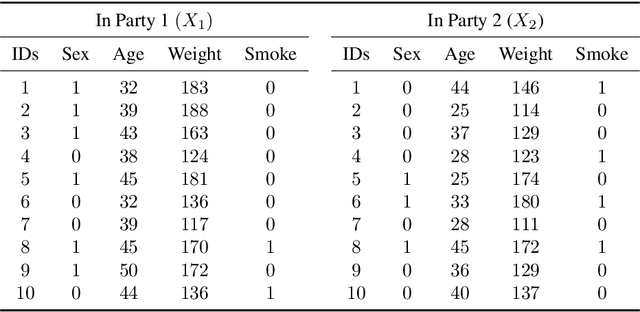
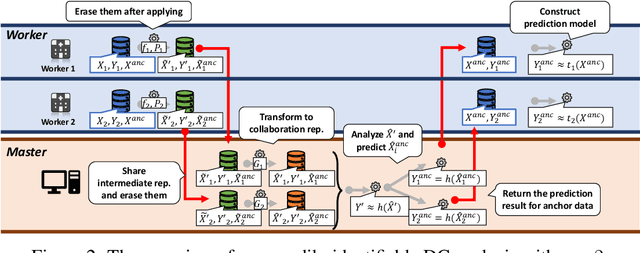
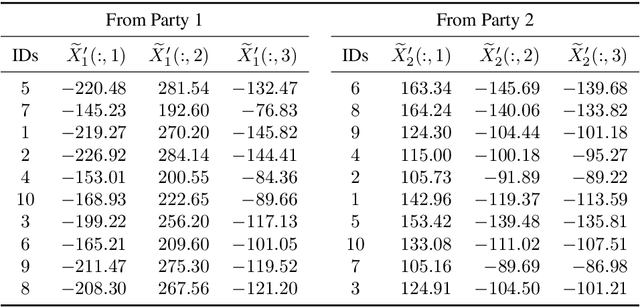
Multi-source data fusion, in which multiple data sources are jointly analyzed to obtain improved information, has considerable research attention. For the datasets of multiple medical institutions, data confidentiality and cross-institutional communication are critical. In such cases, data collaboration (DC) analysis by sharing dimensionality-reduced intermediate representations without iterative cross-institutional communications may be appropriate. Identifiability of the shared data is essential when analyzing data including personal information. In this study, the identifiability of the DC analysis is investigated. The results reveals that the shared intermediate representations are readily identifiable to the original data for supervised learning. This study then proposes a non-readily identifiable DC analysis only sharing non-readily identifiable data for multiple medical datasets including personal information. The proposed method solves identifiability concerns based on a random sample permutation, the concept of interpretable DC analysis, and usage of functions that cannot be reconstructed. In numerical experiments on medical datasets, the proposed method exhibits a non-readily identifiability while maintaining a high recognition performance of the conventional DC analysis. For a hospital dataset, the proposed method exhibits a nine percentage point improvement regarding the recognition performance over the local analysis that uses only local dataset.