 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoFormer: Multi-objective Antimicrobial Peptide Generation Based on Conditional Transformer Joint Multi-modal Fusion Descriptor
Jun 03, 2024



Deep learning holds a big promise for optimizing existing peptides with more desirable properties, a critical step towards accelerating new drug discovery. Despite the recent emergence of several optimized Antimicrobial peptides(AMP) generation methods, multi-objective optimizations remain still quite challenging for the idealism-realism tradeoff. Here, we establish a multi-objective AMP synthesis pipeline (MoFormer) for the simultaneous optimization of multi-attributes of AMPs. MoFormer improves the desired attributes of AMP sequences in a highly structured latent space, guided by conditional constraints and fine-grained multi-descriptor.We show that MoFormer outperforms existing methods in the generation task of enhanced antimicrobial activity and minimal hemolysis. We also utilize a Pareto-based non-dominated sorting algorithm and proxies based on large model fine-tuning to hierarchically rank the candidates. We demonstrate substantial property improvement using MoFormer from two perspectives: (1) employing molecular simulations and scoring interactions among amino acids to decipher the structure and functionality of AMPs; (2) visualizing latent space to examine the qualities and distribution features, verifying an effective means to facilitate multi-objective optimization AMPs with design constraints
HMAMP: Hypervolume-Driven Multi-Objective Antimicrobial Peptides Design
May 01, 2024Antimicrobial peptides (AMPs) have exhibited unprecedented potential as biomaterials in combating multidrug-resistant bacteria. Despite the increasing adoption of artificial intelligence for novel AMP design, challenges pertaining to conflicting attributes such as activity, hemolysis, and toxicity have significantly impeded the progress of researchers. This paper introduces a paradigm shift by considering multiple attributes in AMP design. Presented herein is a novel approach termed Hypervolume-driven Multi-objective Antimicrobial Peptide Design (HMAMP), which prioritizes the simultaneous optimization of multiple attributes of AMPs. By synergizing reinforcement learning and a gradient descent algorithm rooted in the hypervolume maximization concept, HMAMP effectively expands exploration space and mitigates the issue of pattern collapse. This method generates a wide array of prospective AMP candidates that strike a balance among diverse attributes. Furthermore, we pinpoint knee points along the Pareto front of these candidate AMPs. Empirical results across five benchmark models substantiate that HMAMP-designed AMPs exhibit competitive performance and heightened diversity. A detailed analysis of the helical structures and molecular dynamics simulations for ten potential candidate AMPs validates the superiority of HMAMP in the realm of multi-objective AMP design. The ability of HMAMP to systematically craft AMPs considering multiple attributes marks a pioneering milestone, establishing a universal computational framework for the multi-objective design of AMPs.
LSEC: Large-scale spectral ensemble clustering
Jun 18, 2021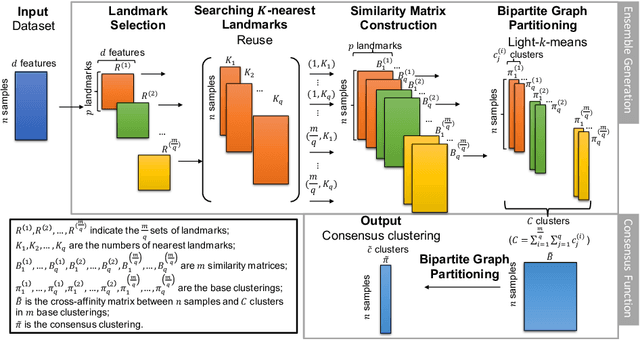


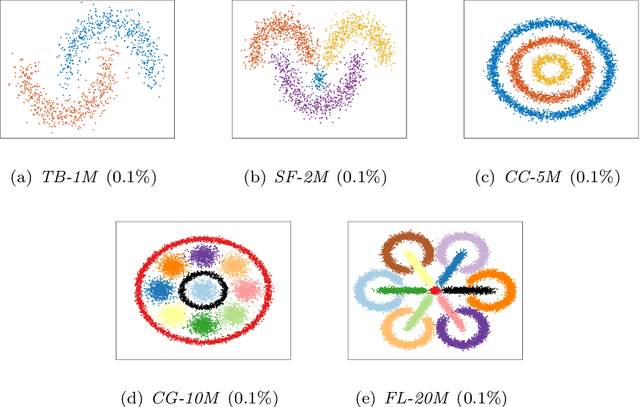
Ensemble clustering is a fundamental problem in the machine learning field, combining multiple base clusterings into a better clustering result. However, most of the existing methods are unsuitable for large-scale ensemble clustering tasks due to the efficiency bottleneck. In this paper, we propose a large-scale spectral ensemble clustering (LSEC) method to strike a good balance between efficiency and effectiveness. In LSEC, a large-scale spectral clustering based efficient ensemble generation framework is designed to generate various base clusterings within a low computational complexity. Then all based clustering are combined through a bipartite graph partition based consensus function into a better consensus clustering result. The LSEC method achieves a lower computational complexity than most existing ensemble clustering methods. Experiments conducted on ten large-scale datasets show the efficiency and effectiveness of the LSEC method. The MATLAB code of the proposed method and experimental datasets are available at https://github.com/Li- Hongmin/MyPaperWithCode.
Divide-and-conquer based Large-Scale Spectral Clustering
Apr 30, 2021

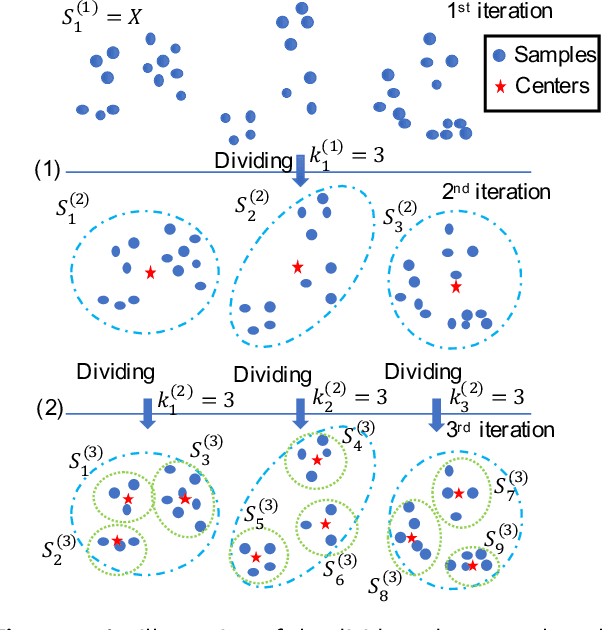
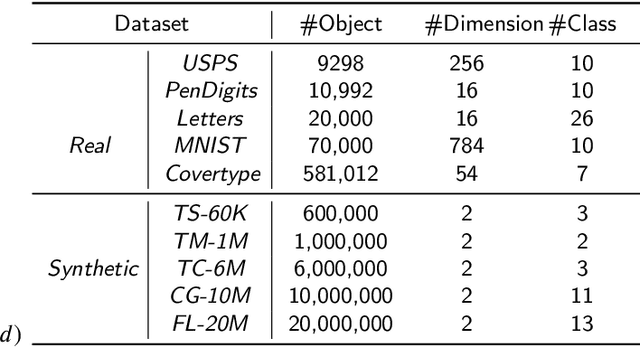
Spectral clustering is one of the most popular clustering methods. However, how to balance the efficiency and effectiveness of the large-scale spectral clustering with limited computing resources has not been properly solved for a long time. In this paper, we propose a divide-and-conquer based large-scale spectral clustering method to strike a good balance between efficiency and effectiveness. In the proposed method, a divide-and-conquer based landmark selection algorithm and a novel approximate similarity matrix approach are designed to construct a sparse similarity matrix within extremely low cost. Then clustering results can be computed quickly through a bipartite graph partition process. The proposed method achieves the lower computational complexity than most existing large-scale spectral clustering. Experimental results on ten large-scale datasets have demonstrated the efficiency and effectiveness of the proposed methods. The MATLAB code of the proposed method and experimental datasets are available at https://github.com/Li-Hongmin/MyPaperWithCode.
Multiclass spectral feature scaling method for dimensionality reduction
Oct 16, 2019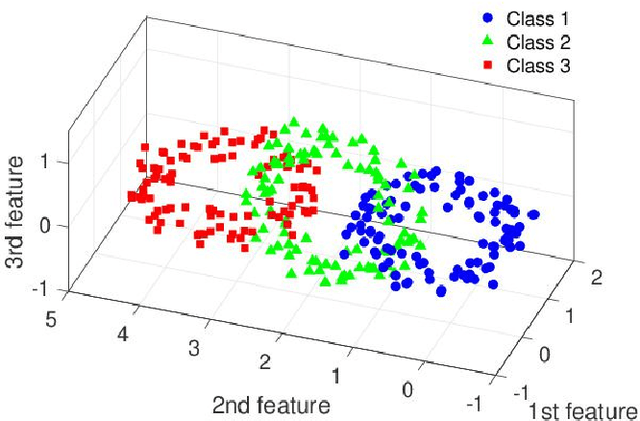


Irregular features disrupt the desired classification. In this paper, we consider aggressively modifying scales of features in the original space according to the label information to form well-separated clusters in low-dimensional space. The proposed method exploits spectral clustering to derive scaling factors that are used to modify the features. Specifically, we reformulate the Laplacian eigenproblem of the spectral clustering as an eigenproblem of a linear matrix pencil whose eigenvector has the scaling factors. Numerical experiments show that the proposed method outperforms well-established supervised dimensionality reduction methods for toy problems with more samples than features and real-world problems with more features than samples.