 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Less Latent Leads to Better Relay: Information-Preserving Compression for Latent Multi-Agent LLM Collaboration
Apr 14, 2026Communication in Large Language Model (LLM)-based multi-agent systems is moving beyond discrete tokens to preserve richer context. Recent work such as LatentMAS enables agents to exchange latent messages through full key-value (KV) caches. However, full KV relay incurs high memory and communication cost. We adapt eviction-style KV compression to this setting and introduce Orthogonal Backfill (OBF) to mitigate information loss from hard eviction. OBF injects a low-rank orthogonal residual from discarded KV states into the retained KV states. We evaluate proposed method against full KV relay on nine standard benchmarks spanning mathematical reasoning, coding, and knowledge-intensive QA. It achieves performance comparable to full KV relay while reducing communication cost by 79.8%--89.4%. OBF further improves the performance and achieves the best results on 7 of the 9 benchmarks. This suggests that more information does not necessarily lead to better communication; preserving the most useful information matters more. Our codebase is publicly available on https://github.com/markli404/When-Less-Latent-Leads-to-Better-Relay.
SAM-Fed: SAM-Guided Federated Semi-Supervised Learning for Medical Image Segmentation
Nov 18, 2025Medical image segmentation is clinically important, yet data privacy and the cost of expert annotation limit the availability of labeled data. Federated semi-supervised learning (FSSL) offers a solution but faces two challenges: pseudo-label reliability depends on the strength of local models, and client devices often require compact or heterogeneous architectures due to limited computational resources. These constraints reduce the quality and stability of pseudo-labels, while large models, though more accurate, cannot be trained or used for routine inference on client devices. We propose SAM-Fed, a federated semi-supervised framework that leverages a high-capacity segmentation foundation model to guide lightweight clients during training. SAM-Fed combines dual knowledge distillation with an adaptive agreement mechanism to refine pixel-level supervision. Experiments on skin lesion and polyp segmentation across homogeneous and heterogeneous settings show that SAM-Fed consistently outperforms state-of-the-art FSSL methods.
Comparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
Scaling up self-supervised learning for improved surgical foundation models
Jan 16, 2025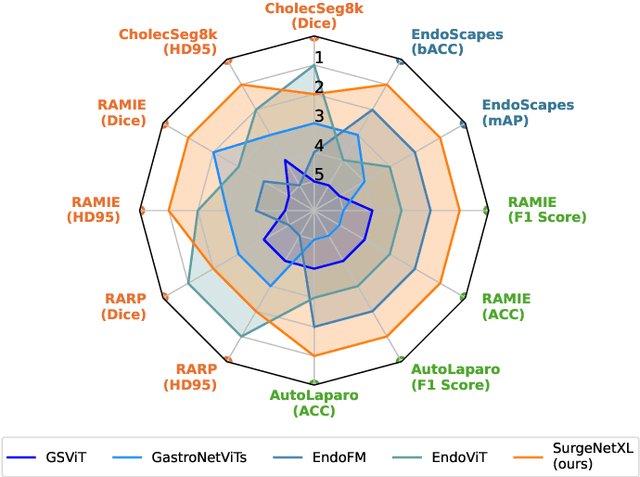
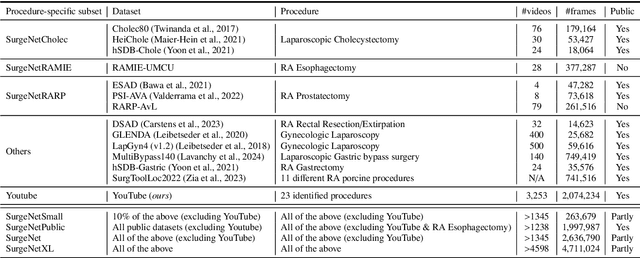
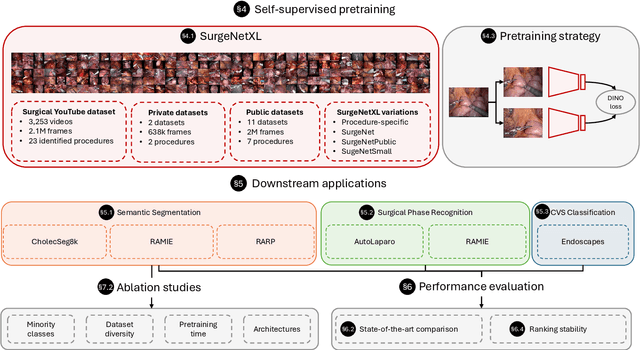
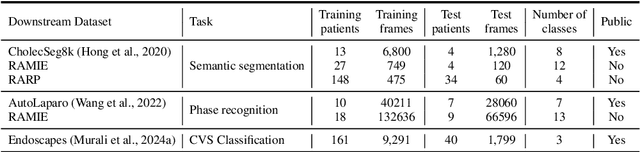
Foundation models have revolutionized computer vision by achieving vastly superior performance across diverse tasks through large-scale pretraining on extensive datasets. However, their application in surgical computer vision has been limited. This study addresses this gap by introducing SurgeNetXL, a novel surgical foundation model that sets a new benchmark in surgical computer vision. Trained on the largest reported surgical dataset to date, comprising over 4.7 million video frames, SurgeNetXL achieves consistent top-tier performance across six datasets spanning four surgical procedures and three tasks, including semantic segmentation, phase recognition, and critical view of safety (CVS) classification. Compared with the best-performing surgical foundation models, SurgeNetXL shows mean improvements of 2.4, 9.0, and 12.6 percent for semantic segmentation, phase recognition, and CVS classification, respectively. Additionally, SurgeNetXL outperforms the best-performing ImageNet-based variants by 14.4, 4.0, and 1.6 percent in the respective tasks. In addition to advancing model performance, this study provides key insights into scaling pretraining datasets, extending training durations, and optimizing model architectures specifically for surgical computer vision. These findings pave the way for improved generalizability and robustness in data-scarce scenarios, offering a comprehensive framework for future research in this domain. All models and a subset of the SurgeNetXL dataset, including over 2 million video frames, are publicly available at: https://github.com/TimJaspers0801/SurgeNet.
SurgRIPE challenge: Benchmark of Surgical Robot Instrument Pose Estimation
Jan 06, 2025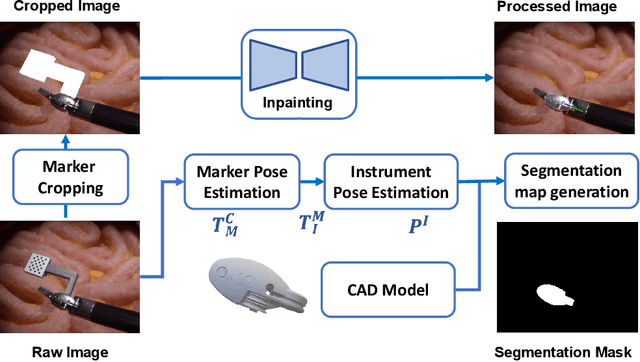


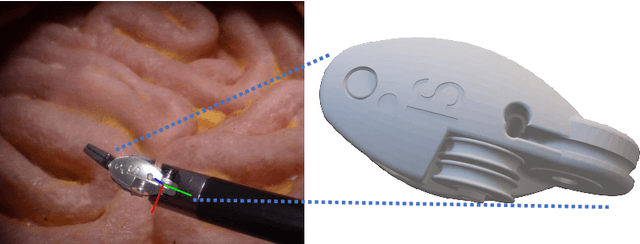
Accurate instrument pose estimation is a crucial step towards the future of robotic surgery, enabling applications such as autonomous surgical task execution. Vision-based methods for surgical instrument pose estimation provide a practical approach to tool tracking, but they often require markers to be attached to the instruments. Recently, more research has focused on the development of marker-less methods based on deep learning. However, acquiring realistic surgical data, with ground truth instrument poses, required for deep learning training, is challenging. To address the issues in surgical instrument pose estimation, we introduce the Surgical Robot Instrument Pose Estimation (SurgRIPE) challenge, hosted at the 26th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2023. The objectives of this challenge are: (1) to provide the surgical vision community with realistic surgical video data paired with ground truth instrument poses, and (2) to establish a benchmark for evaluating markerless pose estimation methods. The challenge led to the development of several novel algorithms that showcased improved accuracy and robustness over existing methods. The performance evaluation study on the SurgRIPE dataset highlights the potential of these advanced algorithms to be integrated into robotic surgery systems, paving the way for more precise and autonomous surgical procedures. The SurgRIPE challenge has successfully established a new benchmark for the field, encouraging further research and development in surgical robot instrument pose estimation.
Unconstrained Salient and Camouflaged Object Detection
Dec 14, 2024



Visual Salient Object Detection (SOD) and Camouflaged Object Detection (COD) are two interrelated yet distinct tasks. Both tasks model the human visual system's ability to perceive the presence of objects. The traditional SOD datasets and methods are designed for scenes where only salient objects are present, similarly, COD datasets and methods are designed for scenes where only camouflaged objects are present. However, scenes where both salient and camouflaged objects coexist, or where neither is present, are not considered. This simplifies the existing research on SOD and COD. In this paper, to explore a more generalized approach to SOD and COD, we introduce a benchmark called Unconstrained Salient and Camouflaged Object Detection (USCOD), which supports the simultaneous detection of salient and camouflaged objects in unconstrained scenes, regardless of their presence. Towards this, we construct a large-scale dataset, CS12K, that encompasses a variety of scenes, including four distinct types: only salient objects, only camouflaged objects, both, and neither. In our benchmark experiments, we identify a major challenge in USCOD: distinguishing between salient and camouflaged objects within the same scene. To address this challenge, we propose USCNet, a baseline model for USCOD that decouples the learning of attribute distinction from mask reconstruction. The model incorporates an APG module, which learns both sample-generic and sample-specific features to enhance the attribute differentiation between salient and camouflaged objects. Furthermore, to evaluate models' ability to distinguish between salient and camouflaged objects, we design a metric called Camouflage-Saliency Confusion Score (CSCS). The proposed method achieves state-of-the-art performance on the newly introduced USCOD task. The code and dataset will be publicly available.
Benchmarking and Enhancing Surgical Phase Recognition Models for Robotic-Assisted Esophagectomy
Dec 05, 2024



Robotic-assisted minimally invasive esophagectomy (RAMIE) is a recognized treatment for esophageal cancer, offering better patient outcomes compared to open surgery and traditional minimally invasive surgery. RAMIE is highly complex, spanning multiple anatomical areas and involving repetitive phases and non-sequential phase transitions. Our goal is to leverage deep learning for surgical phase recognition in RAMIE to provide intraoperative support to surgeons. To achieve this, we have developed a new surgical phase recognition dataset comprising 27 videos. Using this dataset, we conducted a comparative analysis of state-of-the-art surgical phase recognition models. To more effectively capture the temporal dynamics of this complex procedure, we developed a novel deep learning model featuring an encoder-decoder structure with causal hierarchical attention, which demonstrates superior performance compared to existing models.
Benchmarking Pretrained Attention-based Models for Real-Time Recognition in Robot-Assisted Esophagectomy
Dec 04, 2024Esophageal cancer is among the most common types of cancer worldwide. It is traditionally treated using open esophagectomy, but in recent years, robot-assisted minimally invasive esophagectomy (RAMIE) has emerged as a promising alternative. However, robot-assisted surgery can be challenging for novice surgeons, as they often suffer from a loss of spatial orientation. Computer-aided anatomy recognition holds promise for improving surgical navigation, but research in this area remains limited. In this study, we developed a comprehensive dataset for semantic segmentation in RAMIE, featuring the largest collection of vital anatomical structures and surgical instruments to date. Handling this diverse set of classes presents challenges, including class imbalance and the recognition of complex structures such as nerves. This study aims to understand the challenges and limitations of current state-of-the-art algorithms on this novel dataset and problem. Therefore, we benchmarked eight real-time deep learning models using two pretraining datasets. We assessed both traditional and attention-based networks, hypothesizing that attention-based networks better capture global patterns and address challenges such as occlusion caused by blood or other tissues. The benchmark includes our RAMIE dataset and the publicly available CholecSeg8k dataset, enabling a thorough assessment of surgical segmentation tasks. Our findings indicate that pretraining on ADE20k, a dataset for semantic segmentation, is more effective than pretraining on ImageNet. Furthermore, attention-based models outperform traditional convolutional neural networks, with SegNeXt and Mask2Former achieving higher Dice scores, and Mask2Former additionally excelling in average symmetric surface distance.
Exploring the Effect of Dataset Diversity in Self-Supervised Learning for Surgical Computer Vision
Jul 26, 2024Over the past decade, computer vision applications in minimally invasive surgery have rapidly increased. Despite this growth, the impact of surgical computer vision remains limited compared to other medical fields like pathology and radiology, primarily due to the scarcity of representative annotated data. Whereas transfer learning from large annotated datasets such as ImageNet has been conventionally the norm to achieve high-performing models, recent advancements in self-supervised learning (SSL) have demonstrated superior performance. In medical image analysis, in-domain SSL pretraining has already been shown to outperform ImageNet-based initialization. Although unlabeled data in the field of surgical computer vision is abundant, the diversity within this data is limited. This study investigates the role of dataset diversity in SSL for surgical computer vision, comparing procedure-specific datasets against a more heterogeneous general surgical dataset across three different downstream surgical applications. The obtained results show that using solely procedure-specific data can lead to substantial improvements of 13.8%, 9.5%, and 36.8% compared to ImageNet pretraining. However, extending this data with more heterogeneous surgical data further increases performance by an additional 5.0%, 5.2%, and 2.5%, suggesting that increasing diversity within SSL data is beneficial for model performance. The code and pretrained model weights are made publicly available at https://github.com/TimJaspers0801/SurgeNet.
HMAMP: Hypervolume-Driven Multi-Objective Antimicrobial Peptides Design
May 01, 2024Antimicrobial peptides (AMPs) have exhibited unprecedented potential as biomaterials in combating multidrug-resistant bacteria. Despite the increasing adoption of artificial intelligence for novel AMP design, challenges pertaining to conflicting attributes such as activity, hemolysis, and toxicity have significantly impeded the progress of researchers. This paper introduces a paradigm shift by considering multiple attributes in AMP design. Presented herein is a novel approach termed Hypervolume-driven Multi-objective Antimicrobial Peptide Design (HMAMP), which prioritizes the simultaneous optimization of multiple attributes of AMPs. By synergizing reinforcement learning and a gradient descent algorithm rooted in the hypervolume maximization concept, HMAMP effectively expands exploration space and mitigates the issue of pattern collapse. This method generates a wide array of prospective AMP candidates that strike a balance among diverse attributes. Furthermore, we pinpoint knee points along the Pareto front of these candidate AMPs. Empirical results across five benchmark models substantiate that HMAMP-designed AMPs exhibit competitive performance and heightened diversity. A detailed analysis of the helical structures and molecular dynamics simulations for ten potential candidate AMPs validates the superiority of HMAMP in the realm of multi-objective AMP design. The ability of HMAMP to systematically craft AMPs considering multiple attributes marks a pioneering milestone, establishing a universal computational framework for the multi-objective design of AMPs.