 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePan-infection Foundation Framework Enables Multiple Pathogen Prediction
Dec 31, 2024


Host-response-based diagnostics can improve the accuracy of diagnosing bacterial and viral infections, thereby reducing inappropriate antibiotic prescriptions. However, the existing cohorts with limited sample size and coarse infections types are unable to support the exploration of an accurate and generalizable diagnostic model. Here, we curate the largest infection host-response transcriptome data, including 11,247 samples across 89 blood transcriptome datasets from 13 countries and 21 platforms. We build a diagnostic model for pathogen prediction starting from a pan-infection model as foundation (AUC = 0.97) based on the pan-infection dataset. Then, we utilize knowledge distillation to efficiently transfer the insights from this "teacher" model to four lightweight pathogen "student" models, i.e., staphylococcal infection (AUC = 0.99), streptococcal infection (AUC = 0.94), HIV infection (AUC = 0.93), and RSV infection (AUC = 0.94), as well as a sepsis "student" model (AUC = 0.99). The proposed knowledge distillation framework not only facilitates the diagnosis of pathogens using pan-infection data, but also enables an across-disease study from pan-infection to sepsis. Moreover, the framework enables high-degree lightweight design of diagnostic models, which is expected to be adaptively deployed in clinical settings.
Synthetic Data in AI: Challenges, Applications, and Ethical Implications
Jan 03, 2024In the rapidly evolving field of artificial intelligence, the creation and utilization of synthetic datasets have become increasingly significant. This report delves into the multifaceted aspects of synthetic data, particularly emphasizing the challenges and potential biases these datasets may harbor. It explores the methodologies behind synthetic data generation, spanning traditional statistical models to advanced deep learning techniques, and examines their applications across diverse domains. The report also critically addresses the ethical considerations and legal implications associated with synthetic datasets, highlighting the urgent need for mechanisms to ensure fairness, mitigate biases, and uphold ethical standards in AI development.
Impact of Interventional Policies Including Vaccine on Covid-19 Propagation and Socio-Economic Factors
Jan 11, 2021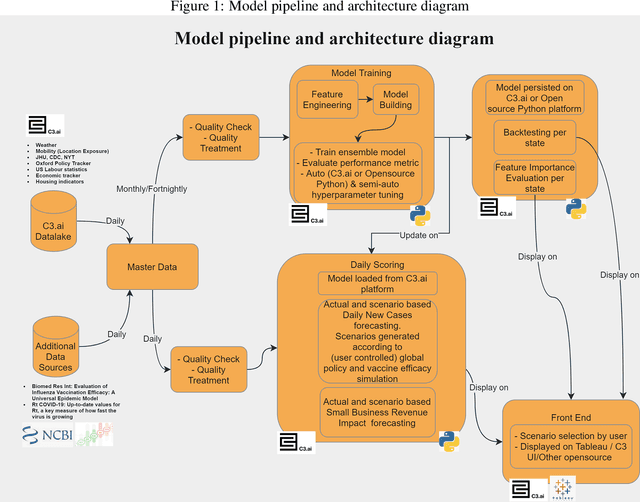
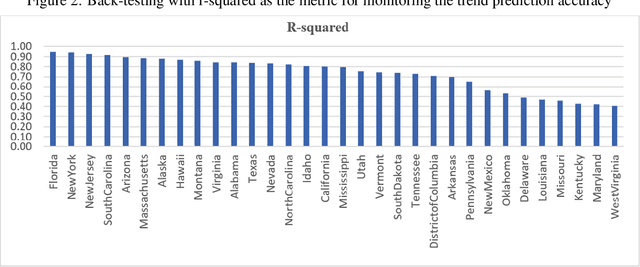
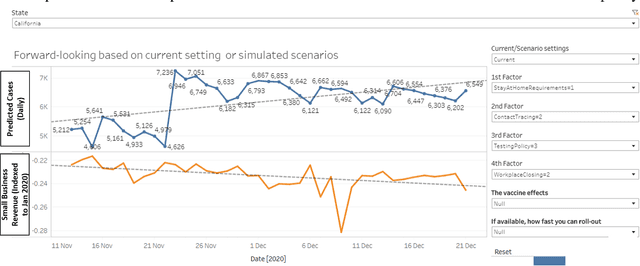
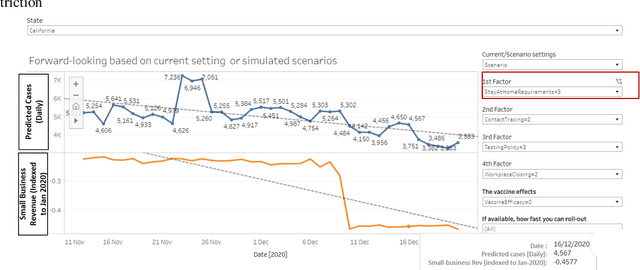
A novel coronavirus disease has emerged (later named COVID-19) and caused the world to enter a new reality, with many direct and indirect factors influencing it. Some are human-controllable (e.g. interventional policies, mobility and the vaccine); some are not (e.g. the weather). We have sought to test how a change in these human-controllable factors might influence two measures: the number of daily cases against economic impact. If applied at the right level and with up-to-date data to measure, policymakers would be able to make targeted interventions and measure their cost. This study aims to provide a predictive analytics framework to model, predict and simulate COVID-19 propagation and the socio-economic impact of interventions intended to reduce the spread of the disease such as policy and/or vaccine. It allows policymakers, government representatives and business leaders to make better-informed decisions about the potential effect of various interventions with forward-looking views via scenario planning. We have leveraged a recently launched open-source COVID-19 big data platform and used published research to find potentially relevant variables (features) and leveraged in-depth data quality checks and analytics for feature selection and predictions. An advanced machine learning pipeline has been developed armed with a self-evolving model, deployed on a modern machine learning architecture. It has high accuracy for trend prediction (back-tested with r-squared) and is augmented with interpretability for deeper insights.