 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOwlCap: Harmonizing Motion-Detail for Video Captioning via HMD-270K and Caption Set Equivalence Reward
Aug 27, 2025
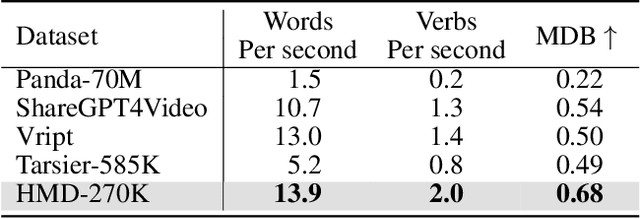
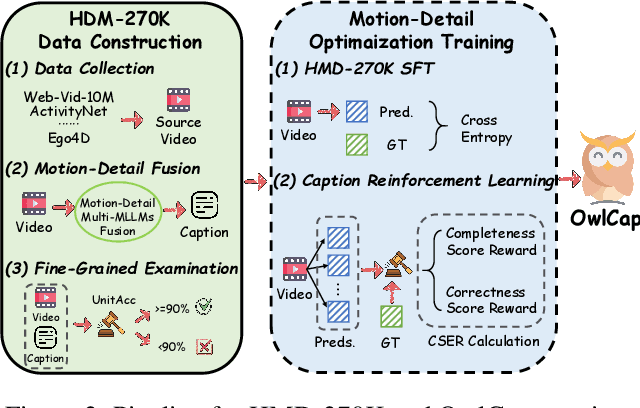
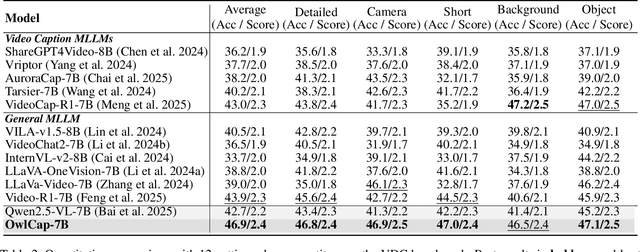
Video captioning aims to generate comprehensive and coherent descriptions of the video content, contributing to the advancement of both video understanding and generation. However, existing methods often suffer from motion-detail imbalance, as models tend to overemphasize one aspect while neglecting the other. This imbalance results in incomplete captions, which in turn leads to a lack of consistency in video understanding and generation. To address this issue, we propose solutions from two aspects: 1) Data aspect: We constructed the Harmonizing Motion-Detail 270K (HMD-270K) dataset through a two-stage pipeline: Motion-Detail Fusion (MDF) and Fine-Grained Examination (FGE). 2) Optimization aspect: We introduce the Caption Set Equivalence Reward (CSER) based on Group Relative Policy Optimization (GRPO). CSER enhances completeness and accuracy in capturing both motion and details through unit-to-set matching and bidirectional validation. Based on the HMD-270K supervised fine-tuning and GRPO post-training with CSER, we developed OwlCap, a powerful video captioning multi-modal large language model (MLLM) with motion-detail balance. Experimental results demonstrate that OwlCap achieves significant improvements compared to baseline models on two benchmarks: the detail-focused VDC (+4.2 Acc) and the motion-focused DREAM-1K (+4.6 F1). The HMD-270K dataset and OwlCap model will be publicly released to facilitate video captioning research community advancements.
Synergistic Bleeding Region and Point Detection in Surgical Videos
Mar 28, 2025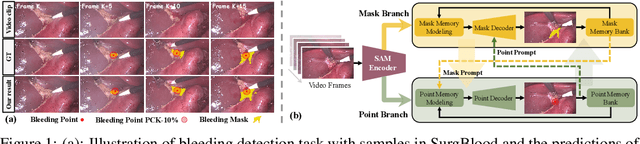
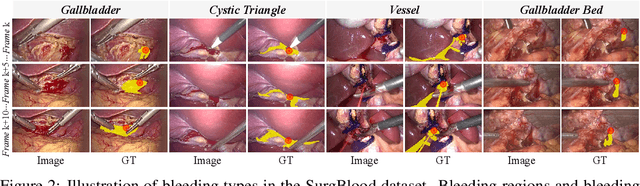
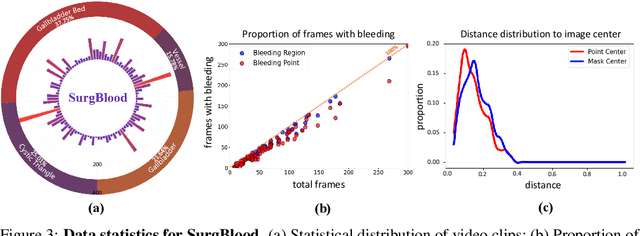
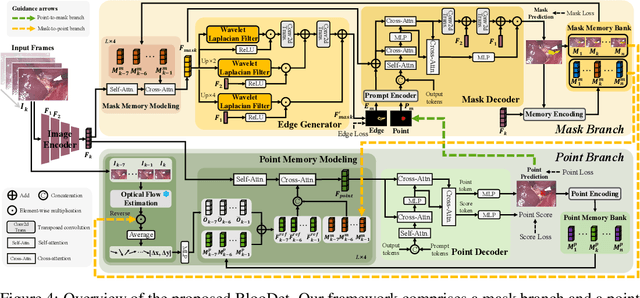
Intraoperative bleeding in laparoscopic surgery causes rapid obscuration of the operative field to hinder the surgical process. Intelligent detection of bleeding regions can quantify the blood loss to assist decision-making, while locating the bleeding point helps surgeons quickly identify the source of bleeding and achieve hemostasis in time. In this study, we first construct a real-world surgical bleeding detection dataset, named SurgBlood, comprising 5,330 frames from 95 surgical video clips with bleeding region and point annotations. Accordingly, we develop a dual-task synergistic online detector called BlooDet, designed to perform simultaneous detection of bleeding regions and points in surgical videos. Our framework embraces a dual-branch bidirectional guidance design based on Segment Anything Model 2 (SAM 2). The mask branch detects bleeding regions through adaptive edge and point prompt embeddings, while the point branch leverages mask memory to induce bleeding point memory modeling and captures the direction of bleed point movement through inter-frame optical flow. By interactive guidance and prompts, the two branches explore potential spatial-temporal relationships while leveraging memory modeling from previous frames to infer the current bleeding condition. Extensive experiments demonstrate that our approach outperforms other counterparts on SurgBlood in both bleeding region and point detection tasks, e.g., achieving 64.88% IoU for bleeding region detection and 83.69% PCK-10% for bleeding point detection.
Unconstrained Salient and Camouflaged Object Detection
Dec 14, 2024



Visual Salient Object Detection (SOD) and Camouflaged Object Detection (COD) are two interrelated yet distinct tasks. Both tasks model the human visual system's ability to perceive the presence of objects. The traditional SOD datasets and methods are designed for scenes where only salient objects are present, similarly, COD datasets and methods are designed for scenes where only camouflaged objects are present. However, scenes where both salient and camouflaged objects coexist, or where neither is present, are not considered. This simplifies the existing research on SOD and COD. In this paper, to explore a more generalized approach to SOD and COD, we introduce a benchmark called Unconstrained Salient and Camouflaged Object Detection (USCOD), which supports the simultaneous detection of salient and camouflaged objects in unconstrained scenes, regardless of their presence. Towards this, we construct a large-scale dataset, CS12K, that encompasses a variety of scenes, including four distinct types: only salient objects, only camouflaged objects, both, and neither. In our benchmark experiments, we identify a major challenge in USCOD: distinguishing between salient and camouflaged objects within the same scene. To address this challenge, we propose USCNet, a baseline model for USCOD that decouples the learning of attribute distinction from mask reconstruction. The model incorporates an APG module, which learns both sample-generic and sample-specific features to enhance the attribute differentiation between salient and camouflaged objects. Furthermore, to evaluate models' ability to distinguish between salient and camouflaged objects, we design a metric called Camouflage-Saliency Confusion Score (CSCS). The proposed method achieves state-of-the-art performance on the newly introduced USCOD task. The code and dataset will be publicly available.
Evaluation Study on SAM 2 for Class-agnostic Instance-level Segmentation
Sep 04, 2024



Segment Anything Model (SAM) has demonstrated powerful zero-shot segmentation performance in natural scenes. The recently released Segment Anything Model 2 (SAM2) has further heightened researchers' expectations towards image segmentation capabilities. To evaluate the performance of SAM2 on class-agnostic instance-level segmentation tasks, we adopt different prompt strategies for SAM2 to cope with instance-level tasks for three relevant scenarios: Salient Instance Segmentation (SIS), Camouflaged Instance Segmentation (CIS), and Shadow Instance Detection (SID). In addition, to further explore the effectiveness of SAM2 in segmenting granular object structures, we also conduct detailed tests on the high-resolution Dichotomous Image Segmentation (DIS) benchmark to assess the fine-grained segmentation capability. Qualitative and quantitative experimental results indicate that the performance of SAM2 varies significantly across different scenarios. Besides, SAM2 is not particularly sensitive to segmenting high-resolution fine details. We hope this technique report can drive the emergence of SAM2-based adapters, aiming to enhance the performance ceiling of large vision models on class-agnostic instance segmentation tasks.
Synthetic Data in AI: Challenges, Applications, and Ethical Implications
Jan 03, 2024In the rapidly evolving field of artificial intelligence, the creation and utilization of synthetic datasets have become increasingly significant. This report delves into the multifaceted aspects of synthetic data, particularly emphasizing the challenges and potential biases these datasets may harbor. It explores the methodologies behind synthetic data generation, spanning traditional statistical models to advanced deep learning techniques, and examines their applications across diverse domains. The report also critically addresses the ethical considerations and legal implications associated with synthetic datasets, highlighting the urgent need for mechanisms to ensure fairness, mitigate biases, and uphold ethical standards in AI development.
Unite-Divide-Unite: Joint Boosting Trunk and Structure for High-accuracy Dichotomous Image Segmentation
Jul 26, 2023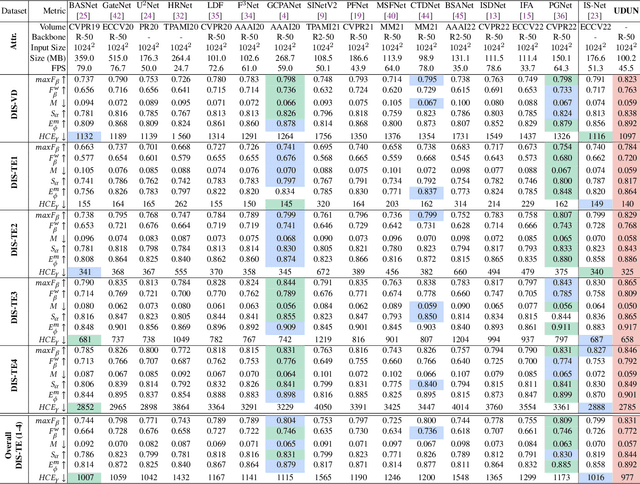



High-accuracy Dichotomous Image Segmentation (DIS) aims to pinpoint category-agnostic foreground objects from natural scenes. The main challenge for DIS involves identifying the highly accurate dominant area while rendering detailed object structure. However, directly using a general encoder-decoder architecture may result in an oversupply of high-level features and neglect the shallow spatial information necessary for partitioning meticulous structures. To fill this gap, we introduce a novel Unite-Divide-Unite Network (UDUN} that restructures and bipartitely arranges complementary features to simultaneously boost the effectiveness of trunk and structure identification. The proposed UDUN proceeds from several strengths. First, a dual-size input feeds into the shared backbone to produce more holistic and detailed features while keeping the model lightweight. Second, a simple Divide-and-Conquer Module (DCM) is proposed to decouple multiscale low- and high-level features into our structure decoder and trunk decoder to obtain structure and trunk information respectively. Moreover, we design a Trunk-Structure Aggregation module (TSA) in our union decoder that performs cascade integration for uniform high-accuracy segmentation. As a result, UDUN performs favorably against state-of-the-art competitors in all six evaluation metrics on overall DIS-TE, i.e., achieving 0.772 weighted F-measure and 977 HCE. Using 1024*1024 input, our model enables real-time inference at 65.3 fps with ResNet-18.