 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Reinforcement Post-Training of Text-to-Image Models with Super-Linear Advantage Shaping
May 11, 2026Recently, post-training methods based on reinforcement learning, with a particular focus on Group Relative Policy Optimization (GRPO), have emerged as the robust paradigm for further advancement of text-to-image (T2I) models. However, these methods are often prone to reward hacking, wherein models exploit biases in imperfect reward functions rather than yielding genuine performance gains. In this work, we identify that normalization could lead to miscalibration and directly removing the prompt-level standard deviation term yields an optimal policy ascent direction that is linear in the advantage but still limits the separation of genuine signals from noise. To mitigate the above issues, we propose Super-Linear Advantage Shaping (SLAS) by revisiting the functional update from an information geometry perspective. By extending the Fisher-Rao information metric with advantage-dependent weighting, SLAS introduces a non-linear geometric structure that reshapes the local policy space. This design relaxes constraints along high-advantage directions to amplify informative updates, while tightening those in low-advantage regions to suppress illusory gradients. In addition, batch-level normalization is applied to stabilize training under varying reward scales. Extensive evaluations demonstrate that SLAS consistently surpasses the DanceGRPO baseline across multiple backbones and benchmarks. In particular, it yields faster training dynamics, improved out-of-domain performance on GenEval and UniGenBench++, and enhanced robustness to model scaling, while mitigating reward hacking and preserving semantic and compositional fidelity in generations.
DDO-RM for LLM Preference Optimization: A Minimal Held-Out Benchmark against DPO
Apr 13, 2026This paper reorganizes the current manuscript around the DPO versus DDO-RM preference-optimization project and focuses on two parts: the algorithmic view and the preliminary held-out benchmark. The benchmark asks a narrow question: even in a minimal pairwise chosen-versus-rejected setting, can a reward-guided decision-distribution update outperform a direct pairwise objective? We compare Direct Preference Optimization (DPO) against DDO-RM on EleutherAI/pythia-410m using HuggingFaceH4/ultrafeedback\_binarized, evaluate on the held-out test\_prefs split, and report results for seeds 42, 13, and 3407. Algorithmically, DDO-RM treats each prompt as a finite decision problem over candidate responses. Instead of optimizing only a binary chosen-rejected relation, it forms a policy distribution over candidates, centers reward-model scores under that distribution, and distills a reward-guided target distribution back into the policy. In the current public benchmark, DDO-RM improves mean pair accuracy from 0.5238 to 0.5602, AUC from 0.5315 to 0.5382, and mean margin from 0.1377 to 0.5353 relative to DPO. These are encouraging but still preliminary results: the study covers one model family, one dataset, one held-out evaluation split, and three seeds.
Few-for-Many Personalized Federated Learning
Mar 12, 2026Personalized Federated Learning (PFL) aims to train customized models for clients with highly heterogeneous data distributions while preserving data privacy. Existing approaches often rely on heuristics like clustering or model interpolation, which lack principled mechanisms for balancing heterogeneous client objectives. Serving $M$ clients with distinct data distributions is inherently a multi-objective optimization problem, where achieving optimal personalization ideally requires $M$ distinct models on the Pareto front. However, maintaining $M$ separate models poses significant scalability challenges in federated settings with hundreds or thousands of clients. To address this challenge, we reformulate PFL as a few-for-many optimization problem that maintains only $K$ shared server models ($K \ll M$) to collectively serve all $M$ clients. We prove that this framework achieves near-optimal personalization: the approximation error diminishes as $K$ increases and each client's model converges to each client's optimum as data grows. Building on this reformulation, we propose FedFew, a practical algorithm that jointly optimizes the $K$ server models through efficient gradient-based updates. Unlike clustering-based approaches that require manual client partitioning or interpolation-based methods that demand careful hyperparameter tuning, FedFew automatically discovers the optimal model diversity through its optimization process. Experiments across vision, NLP, and real-world medical imaging datasets demonstrate that FedFew, with just 3 models, consistently outperforms other state-of-the-art approaches. Code is available at https://github.com/pgg3/FedFew.
AirHunt: Bridging VLM Semantics and Continuous Planning for Efficient Aerial Object Navigation
Jan 19, 2026Recent advances in large Vision-Language Models (VLMs) have provided rich semantic understanding that empowers drones to search for open-set objects via natural language instructions. However, prior systems struggle to integrate VLMs into practical aerial systems due to orders-of-magnitude frequency mismatch between VLM inference and real-time planning, as well as VLMs' limited 3D scene understanding. They also lack a unified mechanism to balance semantic guidance with motion efficiency in large-scale environments. To address these challenges, we present AirHunt, an aerial object navigation system that efficiently locates open-set objects with zero-shot generalization in outdoor environments by seamlessly fusing VLM semantic reasoning with continuous path planning. AirHunt features a dual-pathway asynchronous architecture that establishes a synergistic interface between VLM reasoning and path planning, enabling continuous flight with adaptive semantic guidance that evolves through motion. Moreover, we propose an active dual-task reasoning module that exploits geometric and semantic redundancy to enable selective VLM querying, and a semantic-geometric coherent planning module that dynamically reconciles semantic priorities and motion efficiency in a unified framework, enabling seamless adaptation to environmental heterogeneity. We evaluate AirHunt across diverse object navigation tasks and environments, demonstrating a higher success rate with lower navigation error and reduced flight time compared to state-of-the-art methods. Real-world experiments further validate AirHunt's practical capability in complex and challenging environments. Code and dataset will be made publicly available before publication.
UACER: An Uncertainty-Aware Critic Ensemble Framework for Robust Adversarial Reinforcement Learning
Dec 11, 2025Robust adversarial reinforcement learning has emerged as an effective paradigm for training agents to handle uncertain disturbance in real environments, with critical applications in sequential decision-making domains such as autonomous driving and robotic control. Within this paradigm, agent training is typically formulated as a zero-sum Markov game between a protagonist and an adversary to enhance policy robustness. However, the trainable nature of the adversary inevitably induces non-stationarity in the learning dynamics, leading to exacerbated training instability and convergence difficulties, particularly in high-dimensional complex environments. In this paper, we propose a novel approach, Uncertainty-Aware Critic Ensemble for robust adversarial Reinforcement learning (UACER), which consists of two strategies: 1) Diversified critic ensemble: a diverse set of K critic networks is exploited in parallel to stabilize Q-value estimation rather than conventional single-critic architectures for both variance reduction and robustness enhancement. 2) Time-varying Decay Uncertainty (TDU) mechanism: advancing beyond simple linear combinations, we develop a variance-derived Q-value aggregation strategy that explicitly incorporates epistemic uncertainty to dynamically regulate the exploration-exploitation trade-off while simultaneously stabilizing the training process. Comprehensive experiments across several MuJoCo control problems validate the superior effectiveness of UACER, outperforming state-of-the-art methods in terms of overall performance, stability, and efficiency.
Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation
Oct 24, 2025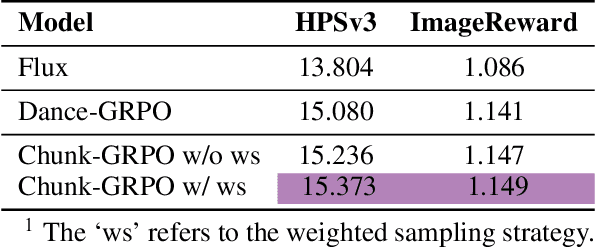
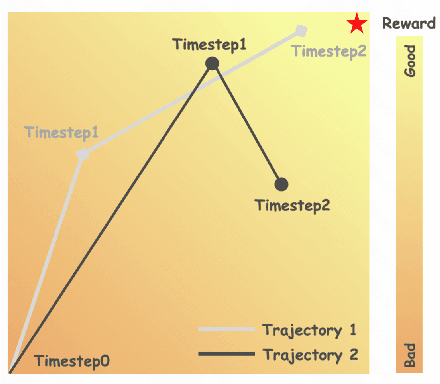
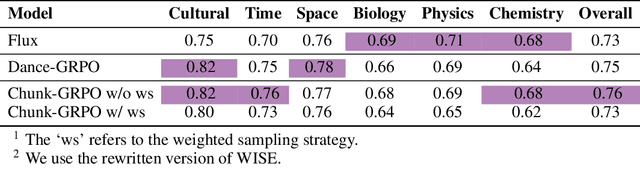
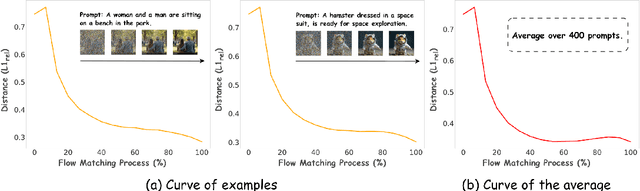
Group Relative Policy Optimization (GRPO) has shown strong potential for flow-matching-based text-to-image (T2I) generation, but it faces two key limitations: inaccurate advantage attribution, and the neglect of temporal dynamics of generation. In this work, we argue that shifting the optimization paradigm from the step level to the chunk level can effectively alleviate these issues. Building on this idea, we propose Chunk-GRPO, the first chunk-level GRPO-based approach for T2I generation. The insight is to group consecutive steps into coherent 'chunk's that capture the intrinsic temporal dynamics of flow matching, and to optimize policies at the chunk level. In addition, we introduce an optional weighted sampling strategy to further enhance performance. Extensive experiments show that ChunkGRPO achieves superior results in both preference alignment and image quality, highlighting the promise of chunk-level optimization for GRPO-based methods.
Distribution Preference Optimization: A Fine-grained Perspective for LLM Unlearning
Oct 06, 2025As Large Language Models (LLMs) demonstrate remarkable capabilities learned from vast corpora, concerns regarding data privacy and safety are receiving increasing attention. LLM unlearning, which aims to remove the influence of specific data while preserving overall model utility, is becoming an important research area. One of the mainstream unlearning classes is optimization-based methods, which achieve forgetting directly through fine-tuning, exemplified by Negative Preference Optimization (NPO). However, NPO's effectiveness is limited by its inherent lack of explicit positive preference signals. Attempts to introduce such signals by constructing preferred responses often necessitate domain-specific knowledge or well-designed prompts, fundamentally restricting their generalizability. In this paper, we shift the focus to the distribution-level, directly targeting the next-token probability distribution instead of entire responses, and derive a novel unlearning algorithm termed \textbf{Di}stribution \textbf{P}reference \textbf{O}ptimization (DiPO). We show that the requisite preference distribution pairs for DiPO, which are distributions over the model's output tokens, can be constructed by selectively amplifying or suppressing the model's high-confidence output logits, thereby effectively overcoming NPO's limitations. We theoretically prove the consistency of DiPO's loss function with the desired unlearning direction. Extensive experiments demonstrate that DiPO achieves a strong trade-off between model utility and forget quality. Notably, DiPO attains the highest forget quality on the TOFU benchmark, and maintains leading scalability and sustainability in utility preservation on the MUSE benchmark.
Reinforcement Fine-Tuning Powers Reasoning Capability of Multimodal Large Language Models
May 24, 2025Standing in 2025, at a critical juncture in the pursuit of Artificial General Intelligence (AGI), reinforcement fine-tuning (RFT) has demonstrated significant potential in enhancing the reasoning capability of large language models (LLMs) and has led to the development of cutting-edge AI models such as OpenAI-o1 and DeepSeek-R1. Moreover, the efficient application of RFT to enhance the reasoning capability of multimodal large language models (MLLMs) has attracted widespread attention from the community. In this position paper, we argue that reinforcement fine-tuning powers the reasoning capability of multimodal large language models. To begin with, we provide a detailed introduction to the fundamental background knowledge that researchers interested in this field should be familiar with. Furthermore, we meticulously summarize the improvements of RFT in powering reasoning capability of MLLMs into five key points: diverse modalities, diverse tasks and domains, better training algorithms, abundant benchmarks and thriving engineering frameworks. Finally, we propose five promising directions for future research that the community might consider. We hope that this position paper will provide valuable insights to the community at this pivotal stage in the advancement toward AGI. Summary of works done on RFT for MLLMs is available at https://github.com/Sun-Haoyuan23/Awesome-RL-based-Reasoning-MLLMs.
Evaluation Study on SAM 2 for Class-agnostic Instance-level Segmentation
Sep 04, 2024



Segment Anything Model (SAM) has demonstrated powerful zero-shot segmentation performance in natural scenes. The recently released Segment Anything Model 2 (SAM2) has further heightened researchers' expectations towards image segmentation capabilities. To evaluate the performance of SAM2 on class-agnostic instance-level segmentation tasks, we adopt different prompt strategies for SAM2 to cope with instance-level tasks for three relevant scenarios: Salient Instance Segmentation (SIS), Camouflaged Instance Segmentation (CIS), and Shadow Instance Detection (SID). In addition, to further explore the effectiveness of SAM2 in segmenting granular object structures, we also conduct detailed tests on the high-resolution Dichotomous Image Segmentation (DIS) benchmark to assess the fine-grained segmentation capability. Qualitative and quantitative experimental results indicate that the performance of SAM2 varies significantly across different scenarios. Besides, SAM2 is not particularly sensitive to segmenting high-resolution fine details. We hope this technique report can drive the emergence of SAM2-based adapters, aiming to enhance the performance ceiling of large vision models on class-agnostic instance segmentation tasks.
Incorporating Clinical Guidelines through Adapting Multi-modal Large Language Model for Prostate Cancer PI-RADS Scoring
May 14, 2024The Prostate Imaging Reporting and Data System (PI-RADS) is pivotal in the diagnosis of clinically significant prostate cancer through MRI imaging. Current deep learning-based PI-RADS scoring methods often lack the incorporation of essential PI-RADS clinical guidelines~(PICG) utilized by radiologists, potentially compromising scoring accuracy. This paper introduces a novel approach that adapts a multi-modal large language model (MLLM) to incorporate PICG into PI-RADS scoring without additional annotations and network parameters. We present a two-stage fine-tuning process aimed at adapting MLLMs originally trained on natural images to the MRI data domain while effectively integrating the PICG. In the first stage, we develop a domain adapter layer specifically tailored for processing 3D MRI image inputs and design the MLLM instructions to differentiate MRI modalities effectively. In the second stage, we translate PICG into guiding instructions for the model to generate PICG-guided image features. Through feature distillation, we align scoring network features with the PICG-guided image feature, enabling the scoring network to effectively incorporate the PICG information. We develop our model on a public dataset and evaluate it in a real-world challenging in-house dataset. Experimental results demonstrate that our approach improves the performance of current scoring networks.