 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatastrophic Interference in Reinforcement Learning: A Solution Based on Context Division and Knowledge Distillation
Paper and Code


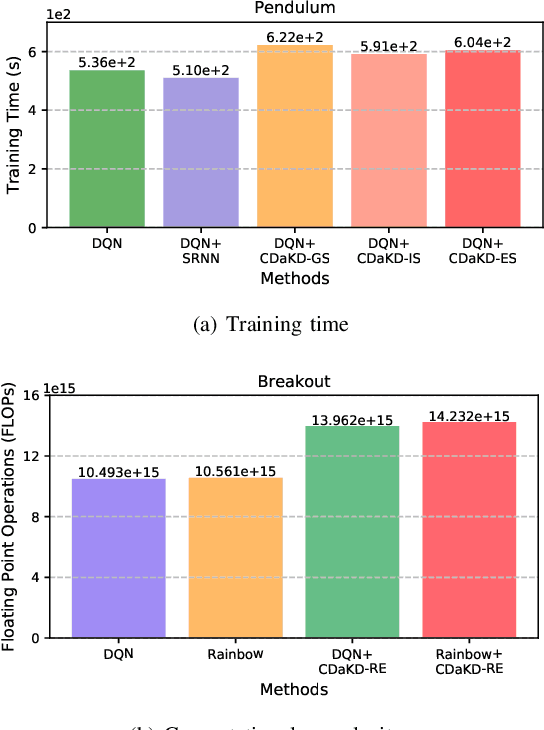
The powerful learning ability of deep neural networks enables reinforcement learning (RL) agents to learn competent control policies directly from high-dimensional and continuous environments. In theory, to achieve stable performance, neural networks assume i.i.d. inputs, which unfortunately does no hold in the general RL paradigm where the training data is temporally correlated and non-stationary. This issue may lead to the phenomenon of "catastrophic interference" and the collapse in performance as later training is likely to overwrite and interfer with previously learned policies. In this paper, we introduce the concept of "context" into single-task RL and develop a novel scheme, termed as Context Division and Knowledge Distillation (CDaKD) driven RL, to divide all states experienced during training into a series of contexts. Its motivation is to mitigate the challenge of aforementioned catastrophic interference in deep RL, thereby improving the stability and plasticity of RL models. At the heart of CDaKD is a value function, parameterized by a neural network feature extractor shared across all contexts, and a set of output heads, each specializing on an individual context. In CDaKD, we exploit online clustering to achieve context division, and interference is further alleviated by a knowledge distillation regularization term on the output layers for learned contexts. In addition, to effectively obtain the context division in high-dimensional state spaces (e.g., image inputs), we perform clustering in the lower-dimensional representation space of a randomly initialized convolutional encoder, which is fixed throughout training. Our results show that, with various replay memory capacities, CDaKD can consistently improve the performance of existing RL algorithms on classic OpenAI Gym tasks and the more complex high-dimensional Atari tasks, incurring only moderate computational overhead.