 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Policy Replay for Continual Supervised Fine-Tuning
May 28, 2026Continual supervised fine-tuning (SFT) is the de facto recipe for adapting large language models (LLMs) to a stream of downstream tasks, but it suffers from catastrophic forgetting of earlier capabilities. Recent work shows that on-policy signals -- training on the model's own outputs -- reduce forgetting more reliably than off-policy supervision. Existing on-policy methods route this signal through a new training objective (e.g., self-distillation losses with a teacher copy), inheriting an extra forward pass, schedule sensitivity, and stylistic drift from the teacher.We instead route the on-policy signal through the training data source. Our method, On-Policy Replay (OPR), rolls out the most recent checkpoint on a small budget of historical prompts, filters the generations by a task reward, and replays the surviving (prompt, model response) pairs as ordinary SFT examples. There is no teacher, no auxiliary loss, and no on-the-fly distillation. Across three 7--8B instruction-tuned backbones (Qwen2.5-7B-Instruct, Qwen3-8B, Llama3.1-8B-Instruct) on the TRACE continual-learning benchmark, OPR consistently reduces forgetting; on the sharpest stress test (Qwen2.5-7B-Instruct, Sequential SFT BWT -13.93), OPR lifts BWT to -0.65 at a 10% replay budget and to -2.29 at a 1% budget -- a 46% reduction in |BWT| over a tuned Vanilla Replay baseline, with 42--46% reductions observed across all three backbones. We give a KL-shrinkage interpretation that places OPR and prior on-policy distillation methods on a single axis, and we present a counterintuitive finding that explains why Vanilla Replay is already a strong baseline: low-score replay is uniformly worse than Vanilla Replay, demonstrating that the active ingredient in OPR is the on-policy distribution, not the response quality alone.Our code is available at https://github.com/Yancey2024/OnPolicyReplay.
Bridging SFT and RL: Dynamic Policy Optimization for Robust Reasoning
Apr 10, 2026Post-training paradigms for Large Language Models (LLMs), primarily Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), face a fundamental dilemma: SFT provides stability (low variance) but suffers from high fitting bias, while RL enables exploration (low bias) but grapples with high gradient variance. Existing unified optimization strategies often employ naive loss weighting, overlooking the statistical conflict between these distinct gradient signals. In this paper, we provide a rigorous theoretical analysis of this bias-variance trade-off and propose \textbf{DYPO} (Dynamic Policy Optimization), a unified framework designed to structurally mitigate this conflict. DYPO integrates three core components: (1) a \textit{Group Alignment Loss (GAL)} that leverages intrinsic group dynamics to significantly reduce RL gradient variance; (2) a \textit{Multi-Teacher Distillation} mechanism that corrects SFT fitting bias via diverse reasoning paths; and (3) a \textit{Dynamic Exploitation-Exploration Gating} mechanism that adaptively arbitrates between stable SFT and exploratory RL based on reward feedback. Theoretical analysis confirms that DYPO linearly reduces fitting bias and minimizes overall variance. Extensive experiments demonstrate that DYPO significantly outperforms traditional sequential pipelines, achieving an average improvement of 4.8\% on complex reasoning benchmarks and 13.3\% on out-of-distribution tasks. Our code is publicly available at https://github.com/Tocci-Zhu/DYPO.
STDA: Spatio-Temporal Dual-Encoder Network Incorporating Driver Attention to Predict Driver Behaviors Under Safety-Critical Scenarios
Aug 03, 2024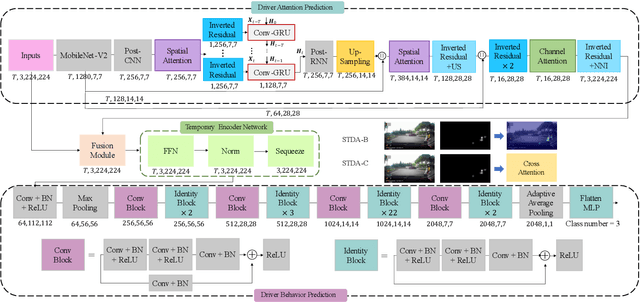
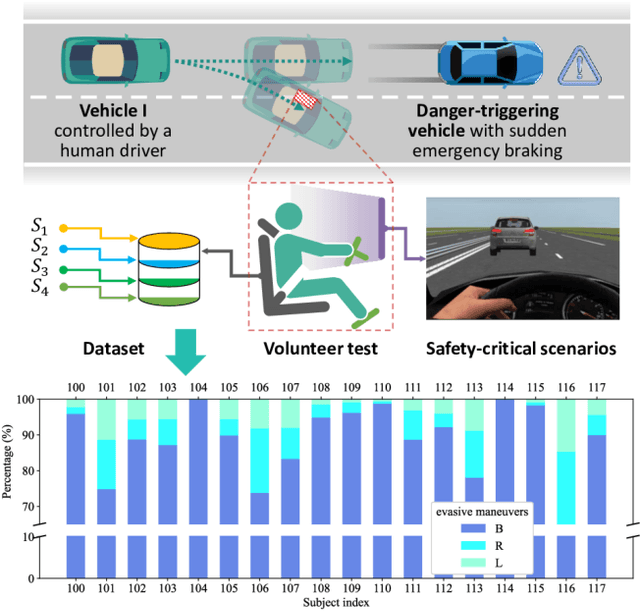
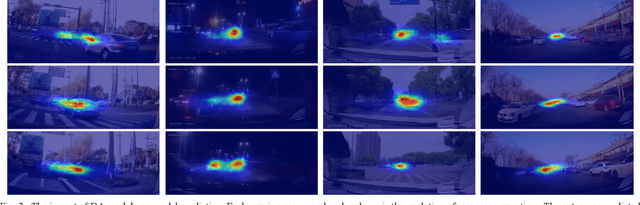
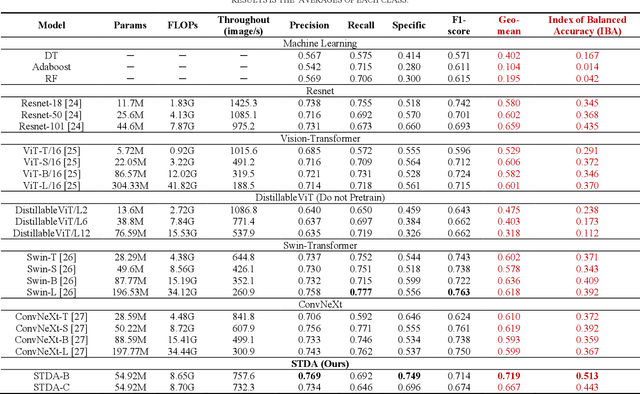
Accurate behavior prediction for vehicles is essential but challenging for autonomous driving. Most existing studies show satisfying performance under regular scenarios, but most neglected safety-critical scenarios. In this study, a spatio-temporal dual-encoder network named STDA for safety-critical scenarios was developed. Considering the exceptional capabilities of human drivers in terms of situational awareness and comprehending risks, driver attention was incorporated into STDA to facilitate swift identification of the critical regions, which is expected to improve both performance and interpretability. STDA contains four parts: the driver attention prediction module, which predicts driver attention; the fusion module designed to fuse the features between driver attention and raw images; the temporary encoder module used to enhance the capability to interpret dynamic scenes; and the behavior prediction module to predict the behavior. The experiment data are used to train and validate the model. The results show that STDA improves the G-mean from 0.659 to 0.719 when incorporating driver attention and adopting a temporal encoder module. In addition, extensive experimentation has been conducted to validate that the proposed module exhibits robust generalization capabilities and can be seamlessly integrated into other mainstream models.
AHMF: Adaptive Hybrid-Memory-Fusion Model for Driver Attention Prediction
Jul 24, 2024



Accurate driver attention prediction can serve as a critical reference for intelligent vehicles in understanding traffic scenes and making informed driving decisions. Though existing studies on driver attention prediction improved performance by incorporating advanced saliency detection techniques, they overlooked the opportunity to achieve human-inspired prediction by analyzing driving tasks from a cognitive science perspective. During driving, drivers' working memory and long-term memory play crucial roles in scene comprehension and experience retrieval, respectively. Together, they form situational awareness, facilitating drivers to quickly understand the current traffic situation and make optimal decisions based on past driving experiences. To explicitly integrate these two types of memory, this paper proposes an Adaptive Hybrid-Memory-Fusion (AHMF) driver attention prediction model to achieve more human-like predictions. Specifically, the model first encodes information about specific hazardous stimuli in the current scene to form working memories. Then, it adaptively retrieves similar situational experiences from the long-term memory for final prediction. Utilizing domain adaptation techniques, the model performs parallel training across multiple datasets, thereby enriching the accumulated driving experience within the long-term memory module. Compared to existing models, our model demonstrates significant improvements across various metrics on multiple public datasets, proving the effectiveness of integrating hybrid memories in driver attention prediction.
Risk-Aware Vehicle Trajectory Prediction Under Safety-Critical Scenarios
Jul 18, 2024Trajectory prediction is significant for intelligent vehicles to achieve high-level autonomous driving, and a lot of relevant research achievements have been made recently. Despite the rapid development, most existing studies solely focused on normal safe scenarios while largely neglecting safety-critical scenarios, particularly those involving imminent collisions. This oversight may result in autonomous vehicles lacking the essential predictive ability in such situations, posing a significant threat to safety. To tackle these, this paper proposes a risk-aware trajectory prediction framework tailored to safety-critical scenarios. Leveraging distinctive hazardous features, we develop three core risk-aware components. First, we introduce a risk-incorporated scene encoder, which augments conventional encoders with quantitative risk information to achieve risk-aware encoding of hazardous scene contexts. Next, we incorporate endpoint-risk-combined intention queries as prediction priors in the decoder to ensure that the predicted multimodal trajectories cover both various spatial intentions and risk levels. Lastly, an auxiliary risk prediction task is implemented for the ultimate risk-aware prediction. Furthermore, to support model training and performance evaluation, we introduce a safety-critical trajectory prediction dataset and tailored evaluation metrics. We conduct comprehensive evaluations and compare our model with several SOTA models. Results demonstrate the superior performance of our model, with a significant improvement in most metrics. This prediction advancement enables autonomous vehicles to execute correct collision avoidance maneuvers under safety-critical scenarios, eventually enhancing road traffic safety.
Safeguarding Next Generation Multiple Access Using Physical Layer Security Techniques: A Tutorial
Mar 25, 2024



Driven by the ever-increasing requirements of ultra-high spectral efficiency, ultra-low latency, and massive connectivity, the forefront of wireless research calls for the design of advanced next generation multiple access schemes to facilitate provisioning of these stringent demands. This inspires the embrace of non-orthogonal multiple access (NOMA) in future wireless communication networks. Nevertheless, the support of massive access via NOMA leads to additional security threats, due to the open nature of the air interface, the broadcast characteristic of radio propagation as well as intertwined relationship among paired NOMA users. To address this specific challenge, the superimposed transmission of NOMA can be explored as new opportunities for security aware design, for example, multiuser interference inherent in NOMA can be constructively engineered to benefit communication secrecy and privacy. The purpose of this tutorial is to provide a comprehensive overview on the state-of-the-art physical layer security techniques that guarantee wireless security and privacy for NOMA networks, along with the opportunities, technical challenges, and future research trends.
M2DA: Multi-Modal Fusion Transformer Incorporating Driver Attention for Autonomous Driving
Mar 19, 2024End-to-end autonomous driving has witnessed remarkable progress. However, the extensive deployment of autonomous vehicles has yet to be realized, primarily due to 1) inefficient multi-modal environment perception: how to integrate data from multi-modal sensors more efficiently; 2) non-human-like scene understanding: how to effectively locate and predict critical risky agents in traffic scenarios like an experienced driver. To overcome these challenges, in this paper, we propose a Multi-Modal fusion transformer incorporating Driver Attention (M2DA) for autonomous driving. To better fuse multi-modal data and achieve higher alignment between different modalities, a novel Lidar-Vision-Attention-based Fusion (LVAFusion) module is proposed. By incorporating driver attention, we empower the human-like scene understanding ability to autonomous vehicles to identify crucial areas within complex scenarios precisely and ensure safety. We conduct experiments on the CARLA simulator and achieve state-of-the-art performance with less data in closed-loop benchmarks. Source codes are available at https://anonymous.4open.science/r/M2DA-4772.
GraphBEV: Towards Robust BEV Feature Alignment for Multi-Modal 3D Object Detection
Mar 18, 2024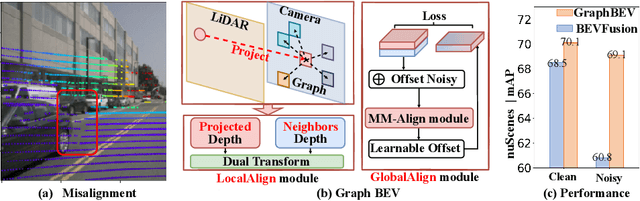
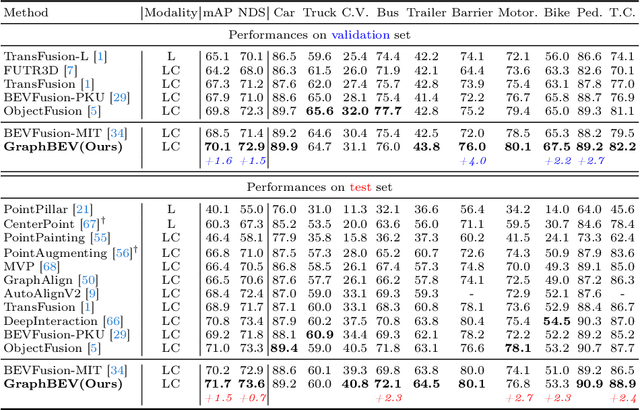
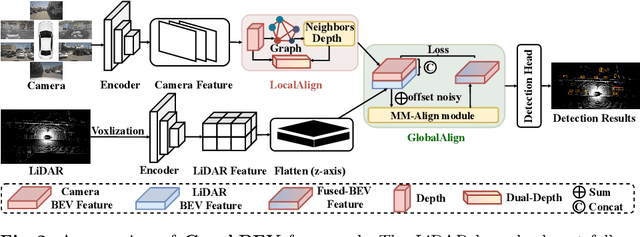
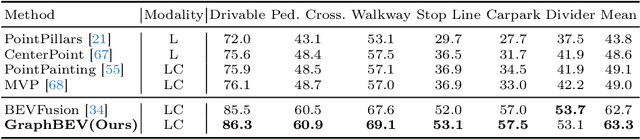
Integrating LiDAR and camera information into Bird's-Eye-View (BEV) representation has emerged as a crucial aspect of 3D object detection in autonomous driving. However, existing methods are susceptible to the inaccurate calibration relationship between LiDAR and the camera sensor. Such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a robust fusion framework called Graph BEV. Addressing errors caused by inaccurate point cloud projection, we introduce a Local Align module that employs neighbor-aware depth features via Graph matching. Additionally, we propose a Global Align module to rectify the misalignment between LiDAR and camera BEV features. Our Graph BEV framework achieves state-of-the-art performance, with an mAP of 70.1\%, surpassing BEV Fusion by 1.6\% on the nuscenes validation set. Importantly, our Graph BEV outperforms BEV Fusion by 8.3\% under conditions with misalignment noise.
Implementation and Evaluation of Physical Layer Key Generation on SDR based LoRa Platform
Aug 30, 2023



Physical layer key generation technology which leverages channel randomness to generate secret keys has attracted extensive attentions in long range (LoRa)-based networks recently. We in this paper develop a software-defined radio (SDR) based LoRa communications platform using GNU Radio on universal software radio peripheral (USRP) to implement and evaluate typical physical layer key generation schemes. Thanks to the flexibility and configurability of GNU Radio to extract LoRa packets, we are able to obtain the fine-grained channel frequency response (CFR) through LoRa preamble based channel estimation for key generation. Besides, we propose a lowcomplexity preprocessing method to enhance the randomness of quantization while reducing the secret key disagreement ratio. The results indicate that we can achieve 367 key bits with a high level of randomness through just a single effective channel probing in an indoor environment at a distance of 2 meters under the circumstance of a spreading factor (SF) of 7, a preamble length of 8, a signal bandwidth of 250 kHz, and a sampling rate of 1 MHz.
Quantum Learning Based Nonrandom Superimposed Coding for Secure Wireless Access in 5G URLLC
Jan 24, 2021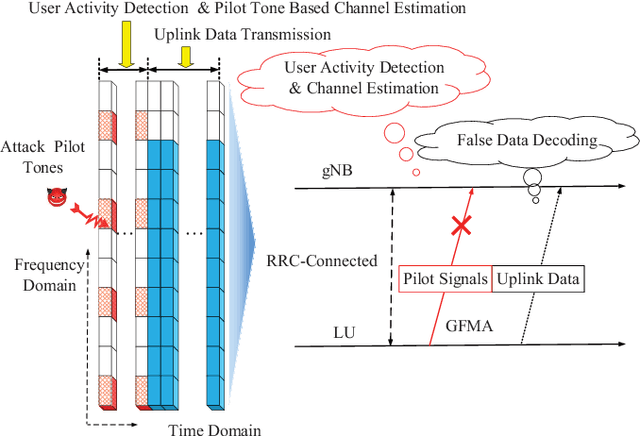
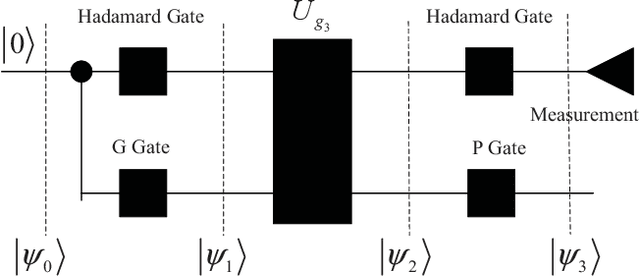
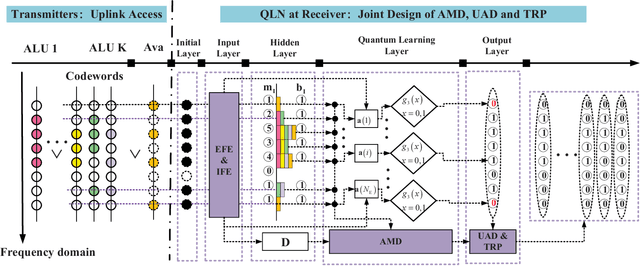
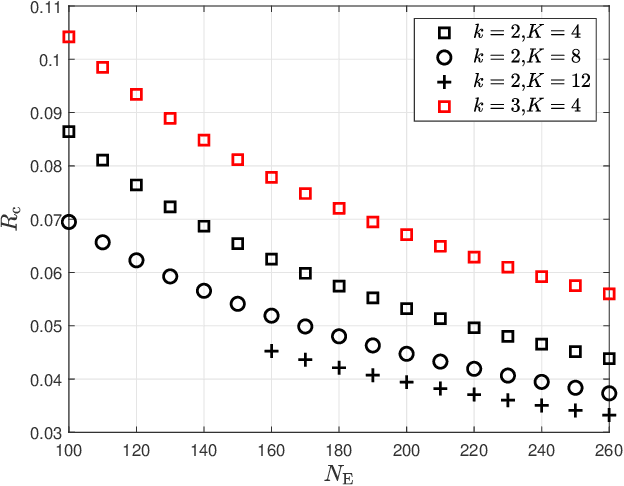
Secure wireless access in ultra-reliable low-latency communications (URLLC), which is a critical aspect of 5G security, has become increasingly important due to its potential support of grant-free configuration. In grant-free URLLC, precise allocation of different pilot resources to different users that share the same time-frequency resource is essential for the next generation NodeB (gNB) to exactly identify those users under access collision and to maintain precise channel estimation required for reliable data transmission. However, this process easily suffers from attacks on pilots. We in this paper propose a quantum learning based nonrandom superimposed coding method to encode and decode pilots on multidimensional resources, such that the uncertainty of attacks can be learned quickly and eliminated precisely. Particularly, multiuser pilots for uplink access are encoded as distinguishable subcarrier activation patterns (SAPs) and gNB decodes pilots of interest from observed SAPs, a superposition of SAPs from access users, by joint design of attack mode detection and user activity detection though a quantum learning network (QLN). We found that the uncertainty lies in the identification process of codeword digits from the attacker, which can be always modelled as a black-box model, resolved by a quantum learning algorithm and quantum circuit. Novel analytical closed-form expressions of failure probability are derived to characterize the reliability of this URLLC system with short packet transmission. Simulations how that our method can bring ultra-high reliability and low latency despite attacks on pilots.