 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTDA: Spatio-Temporal Dual-Encoder Network Incorporating Driver Attention to Predict Driver Behaviors Under Safety-Critical Scenarios
Paper and Code
Aug 03, 2024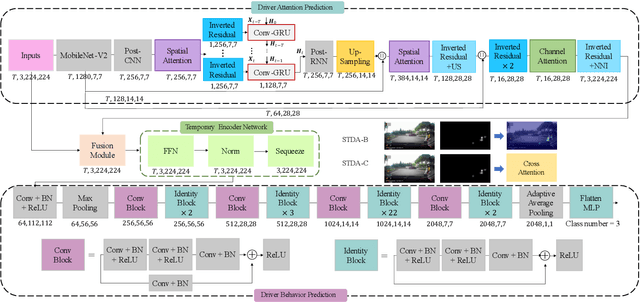
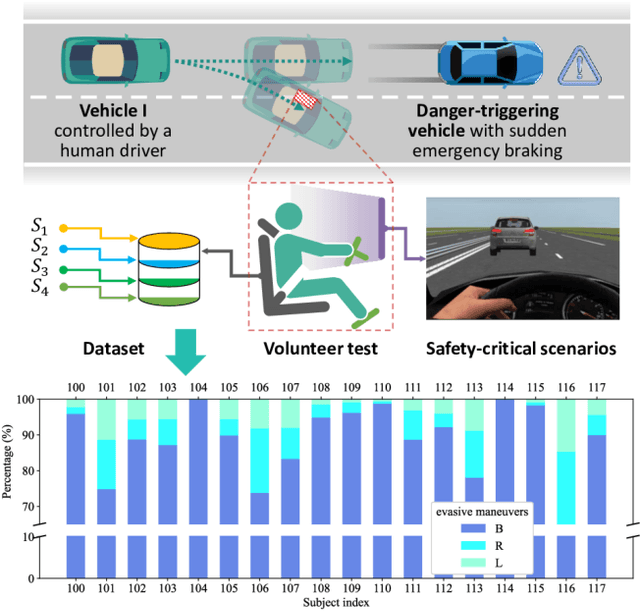
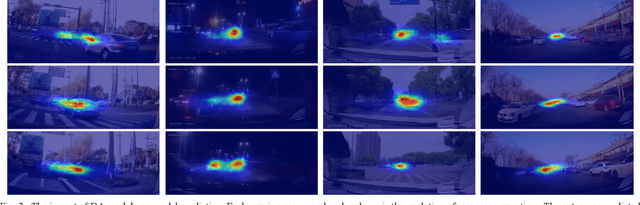
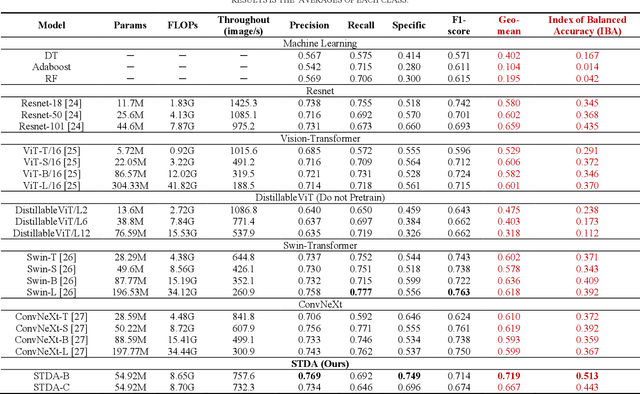
Accurate behavior prediction for vehicles is essential but challenging for autonomous driving. Most existing studies show satisfying performance under regular scenarios, but most neglected safety-critical scenarios. In this study, a spatio-temporal dual-encoder network named STDA for safety-critical scenarios was developed. Considering the exceptional capabilities of human drivers in terms of situational awareness and comprehending risks, driver attention was incorporated into STDA to facilitate swift identification of the critical regions, which is expected to improve both performance and interpretability. STDA contains four parts: the driver attention prediction module, which predicts driver attention; the fusion module designed to fuse the features between driver attention and raw images; the temporary encoder module used to enhance the capability to interpret dynamic scenes; and the behavior prediction module to predict the behavior. The experiment data are used to train and validate the model. The results show that STDA improves the G-mean from 0.659 to 0.719 when incorporating driver attention and adopting a temporal encoder module. In addition, extensive experimentation has been conducted to validate that the proposed module exhibits robust generalization capabilities and can be seamlessly integrated into other mainstream models.