 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTDA: Spatio-Temporal Dual-Encoder Network Incorporating Driver Attention to Predict Driver Behaviors Under Safety-Critical Scenarios
Aug 03, 2024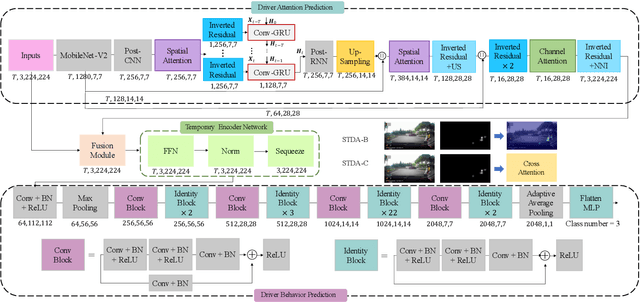
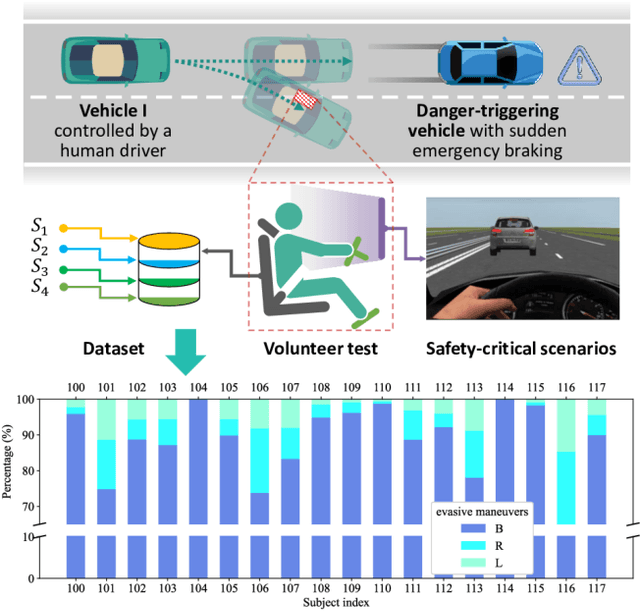
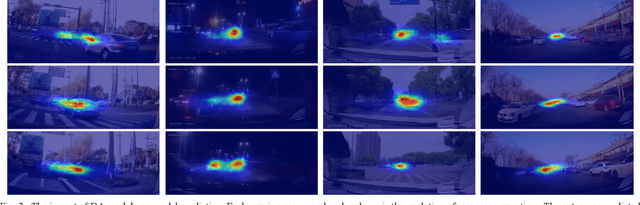
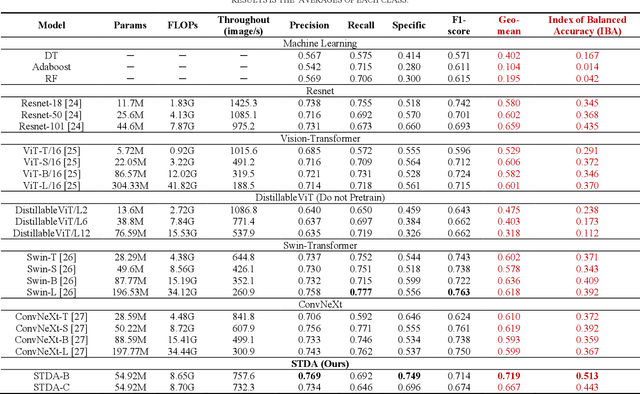
Accurate behavior prediction for vehicles is essential but challenging for autonomous driving. Most existing studies show satisfying performance under regular scenarios, but most neglected safety-critical scenarios. In this study, a spatio-temporal dual-encoder network named STDA for safety-critical scenarios was developed. Considering the exceptional capabilities of human drivers in terms of situational awareness and comprehending risks, driver attention was incorporated into STDA to facilitate swift identification of the critical regions, which is expected to improve both performance and interpretability. STDA contains four parts: the driver attention prediction module, which predicts driver attention; the fusion module designed to fuse the features between driver attention and raw images; the temporary encoder module used to enhance the capability to interpret dynamic scenes; and the behavior prediction module to predict the behavior. The experiment data are used to train and validate the model. The results show that STDA improves the G-mean from 0.659 to 0.719 when incorporating driver attention and adopting a temporal encoder module. In addition, extensive experimentation has been conducted to validate that the proposed module exhibits robust generalization capabilities and can be seamlessly integrated into other mainstream models.
Risk-Aware Vehicle Trajectory Prediction Under Safety-Critical Scenarios
Jul 18, 2024Trajectory prediction is significant for intelligent vehicles to achieve high-level autonomous driving, and a lot of relevant research achievements have been made recently. Despite the rapid development, most existing studies solely focused on normal safe scenarios while largely neglecting safety-critical scenarios, particularly those involving imminent collisions. This oversight may result in autonomous vehicles lacking the essential predictive ability in such situations, posing a significant threat to safety. To tackle these, this paper proposes a risk-aware trajectory prediction framework tailored to safety-critical scenarios. Leveraging distinctive hazardous features, we develop three core risk-aware components. First, we introduce a risk-incorporated scene encoder, which augments conventional encoders with quantitative risk information to achieve risk-aware encoding of hazardous scene contexts. Next, we incorporate endpoint-risk-combined intention queries as prediction priors in the decoder to ensure that the predicted multimodal trajectories cover both various spatial intentions and risk levels. Lastly, an auxiliary risk prediction task is implemented for the ultimate risk-aware prediction. Furthermore, to support model training and performance evaluation, we introduce a safety-critical trajectory prediction dataset and tailored evaluation metrics. We conduct comprehensive evaluations and compare our model with several SOTA models. Results demonstrate the superior performance of our model, with a significant improvement in most metrics. This prediction advancement enables autonomous vehicles to execute correct collision avoidance maneuvers under safety-critical scenarios, eventually enhancing road traffic safety.
Decision-Making under On-Ramp merge Scenarios by Distributional Soft Actor-Critic Algorithm
Mar 08, 2021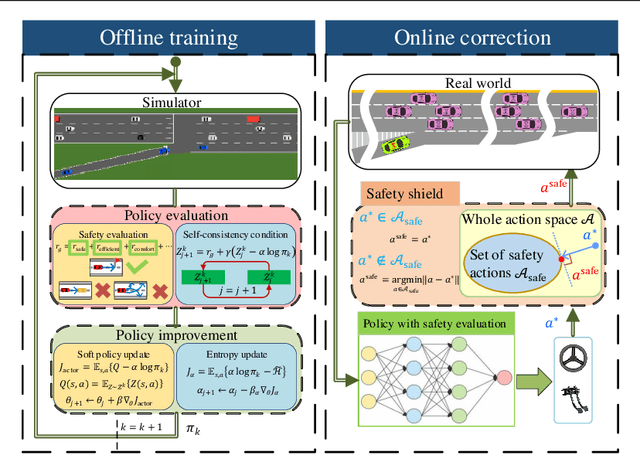
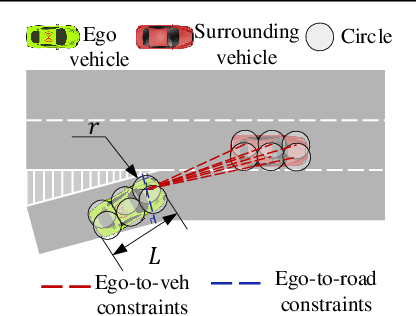
Merging into the highway from the on-ramp is an essential scenario for automated driving. The decision-making under the scenario needs to balance the safety and efficiency performance to optimize a long-term objective, which is challenging due to the dynamic, stochastic, and adversarial characteristics. The Rule-based methods often lead to conservative driving on this task while the learning-based methods have difficulties meeting the safety requirements. In this paper, we propose an RL-based end-to-end decision-making method under a framework of offline training and online correction, called the Shielded Distributional Soft Actor-critic (SDSAC). The SDSAC adopts the policy evaluation with safety consideration and a safety shield parameterized with the barrier function in its offline training and online correction, respectively. These two measures support each other for better safety while not damaging the efficiency performance severely. We verify the SDSAC on an on-ramp merge scenario in simulation. The results show that the SDSAC has the best safety performance compared to baseline algorithms and achieves efficient driving simultaneously.
Mixed Reinforcement Learning with Additive Stochastic Uncertainty
Feb 28, 2020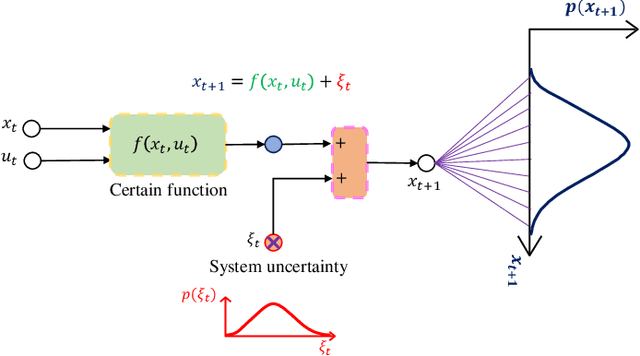
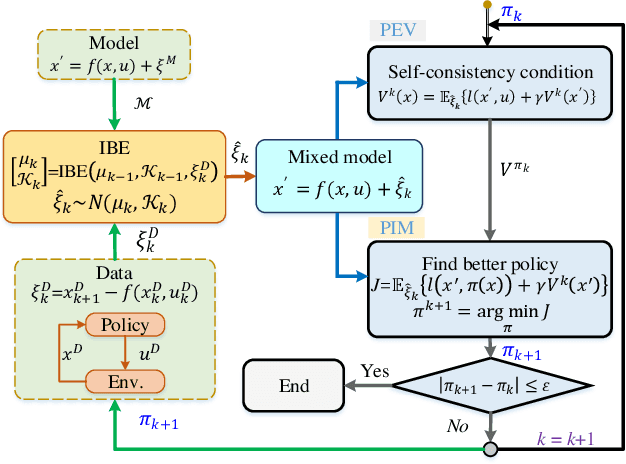
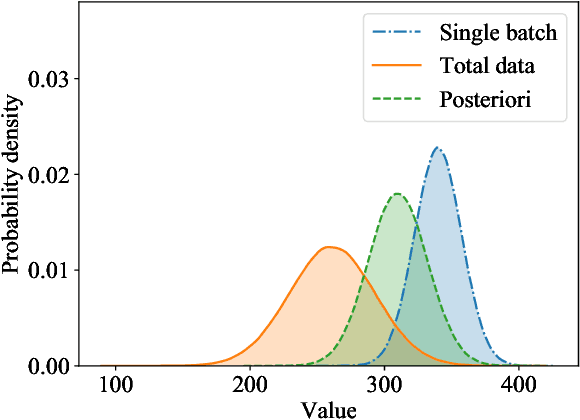
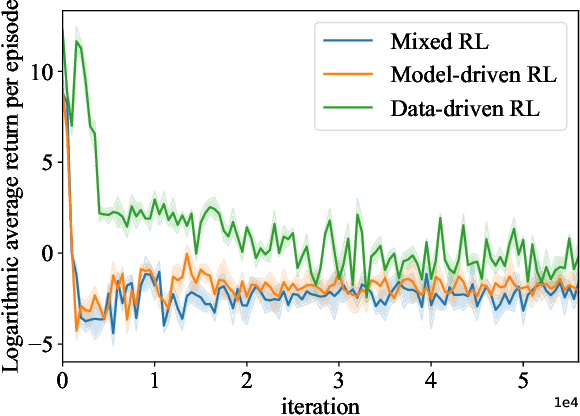
Reinforcement learning (RL) methods often rely on massive exploration data to search optimal policies, and suffer from poor sampling efficiency. This paper presents a mixed reinforcement learning (mixed RL) algorithm by simultaneously using dual representations of environmental dynamics to search the optimal policy with the purpose of improving both learning accuracy and training speed. The dual representations indicate the environmental model and the state-action data: the former can accelerate the learning process of RL, while its inherent model uncertainty generally leads to worse policy accuracy than the latter, which comes from direct measurements of states and actions. In the framework design of the mixed RL, the compensation of the additive stochastic model uncertainty is embedded inside the policy iteration RL framework by using explored state-action data via iterative Bayesian estimator (IBE). The optimal policy is then computed in an iterative way by alternating between policy evaluation (PEV) and policy improvement (PIM). The convergence of the mixed RL is proved using the Bellman's principle of optimality, and the recursive stability of the generated policy is proved via the Lyapunov's direct method. The effectiveness of the mixed RL is demonstrated by a typical optimal control problem of stochastic non-affine nonlinear systems (i.e., double lane change task with an automated vehicle).