 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Caption Preference Optimization for Diffusion Models
Feb 09, 2025Recent advancements in human preference optimization, originally developed for Large Language Models (LLMs), have shown significant potential in improving text-to-image diffusion models. These methods aim to learn the distribution of preferred samples while distinguishing them from less preferred ones. However, existing preference datasets often exhibit overlap between these distributions, leading to a conflict distribution. Additionally, we identified that input prompts contain irrelevant information for less preferred images, limiting the denoising network's ability to accurately predict noise in preference optimization methods, known as the irrelevant prompt issue. To address these challenges, we propose Dual Caption Preference Optimization (DCPO), a novel approach that utilizes two distinct captions to mitigate irrelevant prompts. To tackle conflict distribution, we introduce the Pick-Double Caption dataset, a modified version of Pick-a-Pic v2 with separate captions for preferred and less preferred images. We further propose three different strategies for generating distinct captions: captioning, perturbation, and hybrid methods. Our experiments show that DCPO significantly improves image quality and relevance to prompts, outperforming Stable Diffusion (SD) 2.1, SFT_Chosen, Diffusion-DPO, and MaPO across multiple metrics, including Pickscore, HPSv2.1, GenEval, CLIPscore, and ImageReward, fine-tuned on SD 2.1 as the backbone.
ACTGNN: Assessment of Clustering Tendency with Synthetically-Trained Graph Neural Networks
Jan 30, 2025



Determining clustering tendency in datasets is a fundamental but challenging task, especially in noisy or high-dimensional settings where traditional methods, such as the Hopkins Statistic and Visual Assessment of Tendency (VAT), often struggle to produce reliable results. In this paper, we propose ACTGNN, a graph-based framework designed to assess clustering tendency by leveraging graph representations of data. Node features are constructed using Locality-Sensitive Hashing (LSH), which captures local neighborhood information, while edge features incorporate multiple similarity metrics, such as the Radial Basis Function (RBF) kernel, to model pairwise relationships. A Graph Neural Network (GNN) is trained exclusively on synthetic datasets, enabling robust learning of clustering structures under controlled conditions. Extensive experiments demonstrate that ACTGNN significantly outperforms baseline methods on both synthetic and real-world datasets, exhibiting superior performance in detecting faint clustering structures, even in high-dimensional or noisy data. Our results highlight the generalizability and effectiveness of the proposed approach, making it a promising tool for robust clustering tendency assessment.
REVISION: Rendering Tools Enable Spatial Fidelity in Vision-Language Models
Aug 05, 2024Text-to-Image (T2I) and multimodal large language models (MLLMs) have been adopted in solutions for several computer vision and multimodal learning tasks. However, it has been found that such vision-language models lack the ability to correctly reason over spatial relationships. To tackle this shortcoming, we develop the REVISION framework which improves spatial fidelity in vision-language models. REVISION is a 3D rendering based pipeline that generates spatially accurate synthetic images, given a textual prompt. REVISION is an extendable framework, which currently supports 100+ 3D assets, 11 spatial relationships, all with diverse camera perspectives and backgrounds. Leveraging images from REVISION as additional guidance in a training-free manner consistently improves the spatial consistency of T2I models across all spatial relationships, achieving competitive performance on the VISOR and T2I-CompBench benchmarks. We also design RevQA, a question-answering benchmark to evaluate the spatial reasoning abilities of MLLMs, and find that state-of-the-art models are not robust to complex spatial reasoning under adversarial settings. Our results and findings indicate that utilizing rendering-based frameworks is an effective approach for developing spatially-aware generative models.
STDA: Spatio-Temporal Dual-Encoder Network Incorporating Driver Attention to Predict Driver Behaviors Under Safety-Critical Scenarios
Aug 03, 2024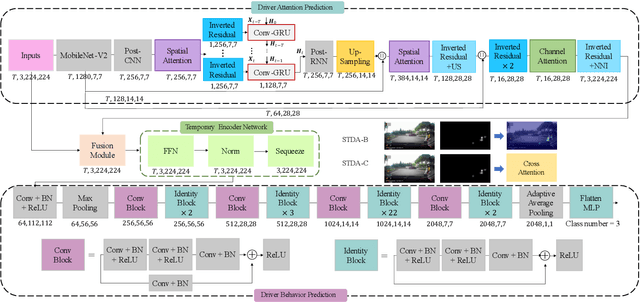
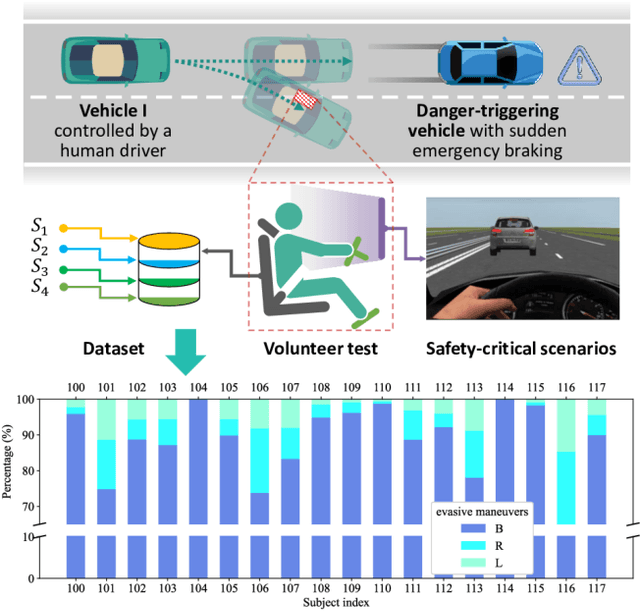
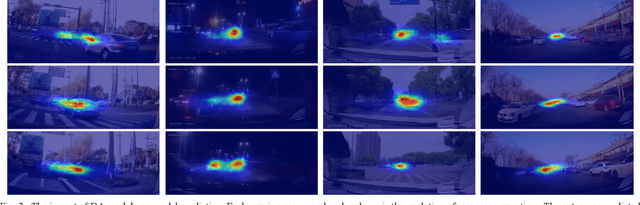
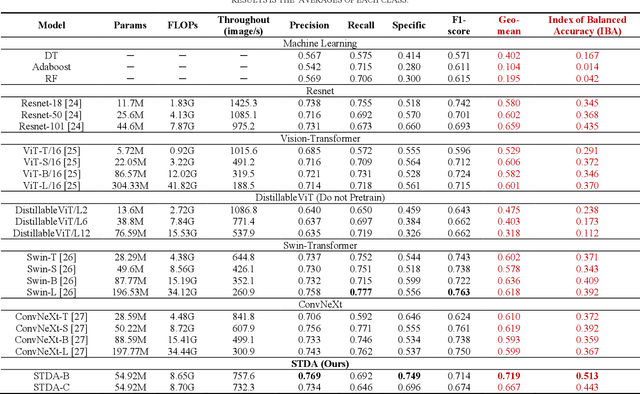
Accurate behavior prediction for vehicles is essential but challenging for autonomous driving. Most existing studies show satisfying performance under regular scenarios, but most neglected safety-critical scenarios. In this study, a spatio-temporal dual-encoder network named STDA for safety-critical scenarios was developed. Considering the exceptional capabilities of human drivers in terms of situational awareness and comprehending risks, driver attention was incorporated into STDA to facilitate swift identification of the critical regions, which is expected to improve both performance and interpretability. STDA contains four parts: the driver attention prediction module, which predicts driver attention; the fusion module designed to fuse the features between driver attention and raw images; the temporary encoder module used to enhance the capability to interpret dynamic scenes; and the behavior prediction module to predict the behavior. The experiment data are used to train and validate the model. The results show that STDA improves the G-mean from 0.659 to 0.719 when incorporating driver attention and adopting a temporal encoder module. In addition, extensive experimentation has been conducted to validate that the proposed module exhibits robust generalization capabilities and can be seamlessly integrated into other mainstream models.
TRAWL: Tensor Reduced and Approximated Weights for Large Language Models
Jun 25, 2024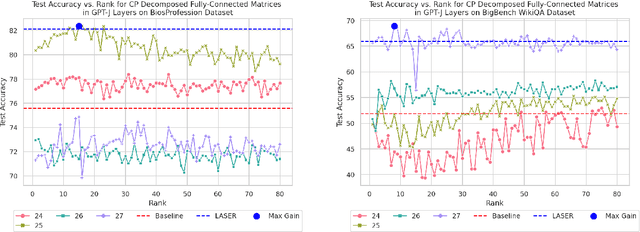
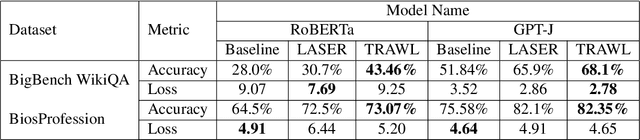
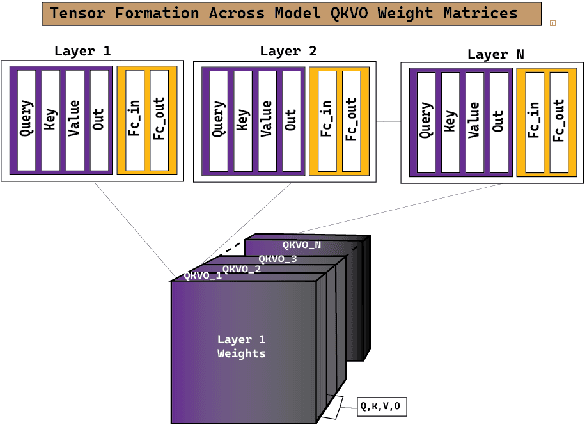
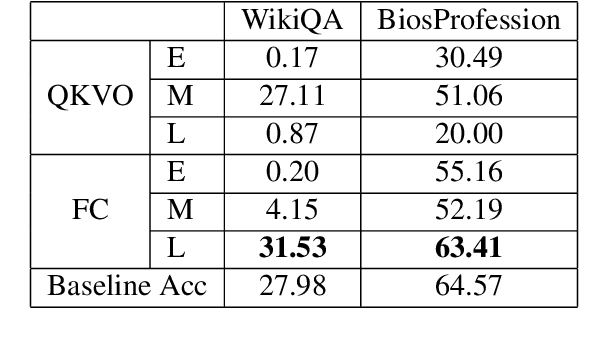
Large language models (LLMs) have fundamentally transformed artificial intelligence, catalyzing recent advancements while imposing substantial environmental and computational burdens. We introduce TRAWL (Tensor Reduced and Approximated Weights for Large Language Models), a novel methodology for optimizing LLMs through tensor decomposition. TRAWL leverages diverse strategies to exploit matrices within transformer-based architectures, realizing notable performance enhancements without necessitating retraining. The most significant improvements were observed through a layer-by-layer intervention strategy, particularly when applied to fully connected weights of the final layers, yielding up to 16% enhancement in accuracy without the need for additional data or fine-tuning. These results underscore the importance of targeted and adaptive techniques in increasing the efficiency and effectiveness of large language model optimization, thereby promoting the development of more sustainable and accessible AI systems.
Grounding Stylistic Domain Generalization with Quantitative Domain Shift Measures and Synthetic Scene Images
May 24, 2024



Domain Generalization (DG) is a challenging task in machine learning that requires a coherent ability to comprehend shifts across various domains through extraction of domain-invariant features. DG performance is typically evaluated by performing image classification in domains of various image styles. However, current methodology lacks quantitative understanding about shifts in stylistic domain, and relies on a vast amount of pre-training data, such as ImageNet1K, which are predominantly in photo-realistic style with weakly supervised class labels. Such a data-driven practice could potentially result in spurious correlation and inflated performance on DG benchmarks. In this paper, we introduce a new DG paradigm to address these risks. We first introduce two new quantitative measures ICV and IDD to describe domain shifts in terms of consistency of classes within one domain and similarity between two stylistic domains. We then present SuperMarioDomains (SMD), a novel synthetic multi-domain dataset sampled from video game scenes with more consistent classes and sufficient dissimilarity compared to ImageNet1K. We demonstrate our DG method SMOS. SMOS first uses SMD to train a precursor model, which is then used to ground the training on a DG benchmark. We observe that SMOS contributes to state-of-the-art performance across five DG benchmarks, gaining large improvements to performances on abstract domains along with on-par or slight improvements to those on photo-realistic domains. Our qualitative analysis suggests that these improvements can be attributed to reduced distributional divergence between originally distant domains. Our data are available at https://github.com/fpsluozi/SMD-SMOS .
Model, Analyze, and Comprehend User Interactions and Various Attributes within a Social Media Platform
Mar 23, 2024How can we effectively model, analyze, and comprehend user interactions and various attributes within a social media platform based on post-comment relationship? In this study, we propose a novel graph-based approach to model and analyze user interactions within a social media platform based on post-comment relationship. We construct a user interaction graph from social media data and analyze it to gain insights into community dynamics, user behavior, and content preferences. Our investigation reveals that while 56.05% of the active users are strongly connected within the community, only 0.8% of them significantly contribute to its dynamics. Moreover, we observe temporal variations in community activity, with certain periods experiencing heightened engagement. Additionally, our findings highlight a correlation between user activity and popularity showing that more active users are generally more popular. Alongside these, a preference for positive and informative content is also observed where 82.41% users preferred positive and informative content. Overall, our study provides a comprehensive framework for understanding and managing online communities, leveraging graph-based techniques to gain valuable insights into user behavior and community dynamics.
Lost in Translation? Translation Errors and Challenges for Fair Assessment of Text-to-Image Models on Multilingual Concepts
Mar 17, 2024



Benchmarks of the multilingual capabilities of text-to-image (T2I) models compare generated images prompted in a test language to an expected image distribution over a concept set. One such benchmark, "Conceptual Coverage Across Languages" (CoCo-CroLa), assesses the tangible noun inventory of T2I models by prompting them to generate pictures from a concept list translated to seven languages and comparing the output image populations. Unfortunately, we find that this benchmark contains translation errors of varying severity in Spanish, Japanese, and Chinese. We provide corrections for these errors and analyze how impactful they are on the utility and validity of CoCo-CroLa as a benchmark. We reassess multiple baseline T2I models with the revisions, compare the outputs elicited under the new translations to those conditioned on the old, and show that a correction's impactfulness on the image-domain benchmark results can be predicted in the text domain with similarity scores. Our findings will guide the future development of T2I multilinguality metrics by providing analytical tools for practical translation decisions.
High-Accuracy Absolute-Position-Aided Code Phase Tracking Based on RTK/INS Deep Integration in Challenging Static Scenarios
Dec 31, 2022

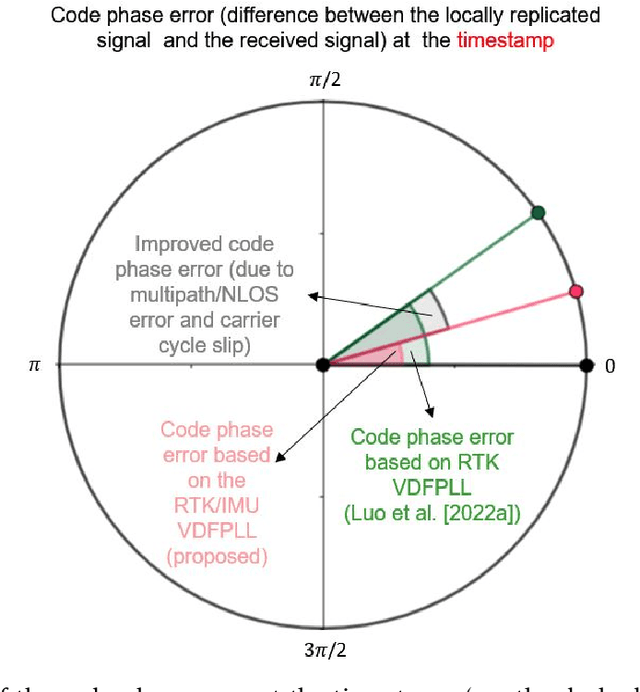
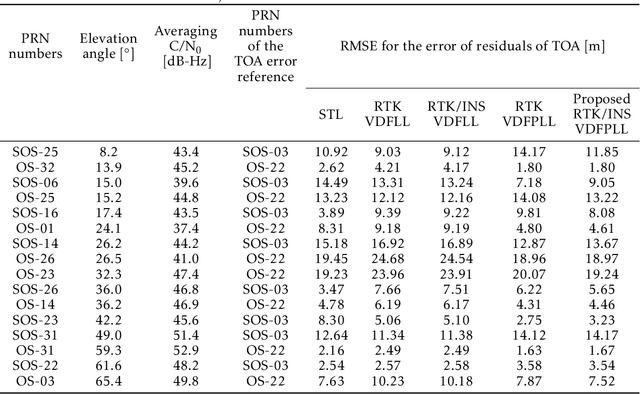
Many multi-sensor navigation systems urgently demand accurate positioning initialization from global navigation satellite systems (GNSSs) in challenging static scenarios. However, ground blockages against line-of-sight (LOS) signal reception make it difficult for GNSS users. Steering local codes in GNSS basebands is a desiring way to correct instantaneous signal phase misalignment, efficiently gathering useful signal power and increasing positioning accuracy. Besides, inertial navigation systems (INSs) have been used as a well-complementary dead reckoning (DR) sensor for GNSS receivers in kinematic scenarios resisting various interferences since early. But little work focuses on the case of whether the INS can improve GNSS receivers in static scenarios. Thus, this paper proposes an enhanced navigation system deeply integrated with low-cost INS solutions and GNSS high-accuracy carrier-based positioning. First, an absolute code phase is predicted from base station information, and integrated solution of the INS DR and real-time kinematic (RTK) results through an extended Kalman filter (EKF). Then, a numerically controlled oscillator (NCO) leverages the predicted code phase to improve the alignment between instantaneous local code phases and received ones. The proposed algorithm is realized in a vector-tracking GNSS software-defined radio (SDR). Real-world experiments demonstrate the proposed SDR regarding estimating time-of-arrival (TOA) and positioning accuracy.
To Find Waldo You Need Contextual Cues: Debiasing Who's Waldo
Mar 30, 2022
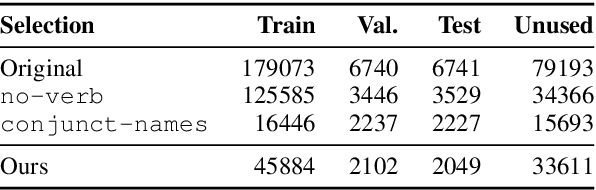
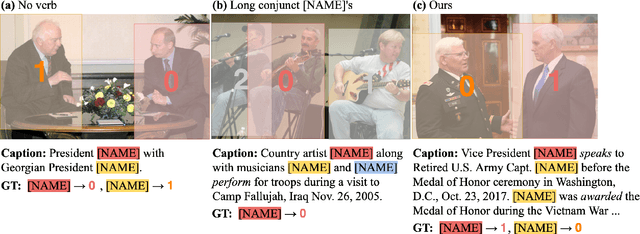
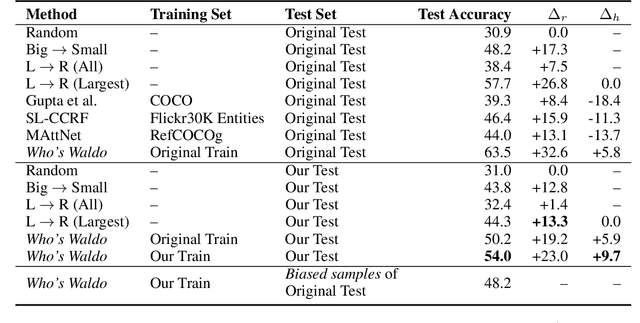
We present a debiased dataset for the Person-centric Visual Grounding (PCVG) task first proposed by Cui et al. (2021) in the Who's Waldo dataset. Given an image and a caption, PCVG requires pairing up a person's name mentioned in a caption with a bounding box that points to the person in the image. We find that the original Who's Waldo dataset compiled for this task contains a large number of biased samples that are solvable simply by heuristic methods; for instance, in many cases the first name in the sentence corresponds to the largest bounding box, or the sequence of names in the sentence corresponds to an exact left-to-right order in the image. Naturally, models trained on these biased data lead to over-estimation of performance on the benchmark. To enforce models being correct for the correct reasons, we design automated tools to filter and debias the original dataset by ruling out all examples of insufficient context, such as those with no verb or with a long chain of conjunct names in their captions. Our experiments show that our new sub-sampled dataset contains less bias with much lowered heuristic performances and widened gaps between heuristic and supervised methods. We also demonstrate the same benchmark model trained on our debiased training set outperforms that trained on the original biased (and larger) training set on our debiased test set. We argue our debiased dataset offers the PCVG task a more practical baseline for reliable benchmarking and future improvements.