 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can Input Reformulation Improve Tool Usage Accuracy in a Complex Dynamic Environment? A Study on $τ$-bench
Aug 28, 2025Recent advances in reasoning and planning capabilities of large language models (LLMs) have enabled their potential as autonomous agents capable of tool use in dynamic environments. However, in multi-turn conversational environments like $\tau$-bench, these agents often struggle with consistent reasoning, adherence to domain-specific policies, and extracting correct information over a long horizon of tool-calls and conversation. To capture and mitigate these failures, we conduct a comprehensive manual analysis of the common errors occurring in the conversation trajectories. We then experiment with reformulations of inputs to the tool-calling agent for improvement in agent decision making. Finally, we propose the Input-Reformulation Multi-Agent (IRMA) framework, which automatically reformulates user queries augmented with relevant domain rules and tool suggestions for the tool-calling agent to focus on. The results show that IRMA significantly outperforms ReAct, Function Calling, and Self-Reflection by 16.1%, 12.7%, and 19.1%, respectively, in overall pass^5 scores. These findings highlight the superior reliability and consistency of IRMA compared to other methods in dynamic environments.
Dual Caption Preference Optimization for Diffusion Models
Feb 09, 2025


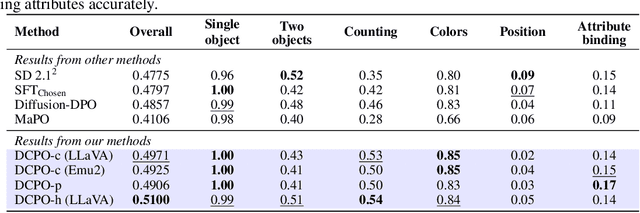
Recent advancements in human preference optimization, originally developed for Large Language Models (LLMs), have shown significant potential in improving text-to-image diffusion models. These methods aim to learn the distribution of preferred samples while distinguishing them from less preferred ones. However, existing preference datasets often exhibit overlap between these distributions, leading to a conflict distribution. Additionally, we identified that input prompts contain irrelevant information for less preferred images, limiting the denoising network's ability to accurately predict noise in preference optimization methods, known as the irrelevant prompt issue. To address these challenges, we propose Dual Caption Preference Optimization (DCPO), a novel approach that utilizes two distinct captions to mitigate irrelevant prompts. To tackle conflict distribution, we introduce the Pick-Double Caption dataset, a modified version of Pick-a-Pic v2 with separate captions for preferred and less preferred images. We further propose three different strategies for generating distinct captions: captioning, perturbation, and hybrid methods. Our experiments show that DCPO significantly improves image quality and relevance to prompts, outperforming Stable Diffusion (SD) 2.1, SFT_Chosen, Diffusion-DPO, and MaPO across multiple metrics, including Pickscore, HPSv2.1, GenEval, CLIPscore, and ImageReward, fine-tuned on SD 2.1 as the backbone.
UnSeenTimeQA: Time-Sensitive Question-Answering Beyond LLMs' Memorization
Jul 03, 2024



This paper introduces UnSeenTimeQA, a novel time-sensitive question-answering (TSQA) benchmark that diverges from traditional TSQA benchmarks by avoiding factual and web-searchable queries. We present a series of time-sensitive event scenarios decoupled from real-world factual information. It requires large language models (LLMs) to engage in genuine temporal reasoning, disassociating from the knowledge acquired during the pre-training phase. Our evaluation of six open-source LLMs (ranging from 2B to 70B in size) and three closed-source LLMs reveal that the questions from the UnSeenTimeQA present substantial challenges. This indicates the models' difficulties in handling complex temporal reasoning scenarios. Additionally, we present several analyses shedding light on the models' performance in answering time-sensitive questions.
Investigating and Addressing Hallucinations of LLMs in Tasks Involving Negation
Jun 08, 2024Large Language Models (LLMs) have achieved remarkable performance across a wide variety of natural language tasks. However, they have been shown to suffer from a critical limitation pertinent to 'hallucination' in their output. Recent research has focused on investigating and addressing this problem for a variety of tasks such as biography generation, question answering, abstractive summarization, and dialogue generation. However, the crucial aspect pertaining to 'negation' has remained considerably underexplored. Negation is important because it adds depth and nuance to the understanding of language and is also crucial for logical reasoning and inference. In this work, we address the above limitation and particularly focus on studying the impact of negation in LLM hallucinations. Specifically, we study four tasks with negation: 'false premise completion', 'constrained fact generation', 'multiple choice question answering', and 'fact generation'. We show that open-source state-of-the-art LLMs such as LLaMA-2-chat, Vicuna, and Orca-2 hallucinate considerably on all these tasks involving negation which underlines a critical shortcoming of these models. Addressing this problem, we further study numerous strategies to mitigate these hallucinations and demonstrate their impact.
Triple Preference Optimization: Achieving Better Alignment with Less Data in a Single Step Optimization
May 26, 2024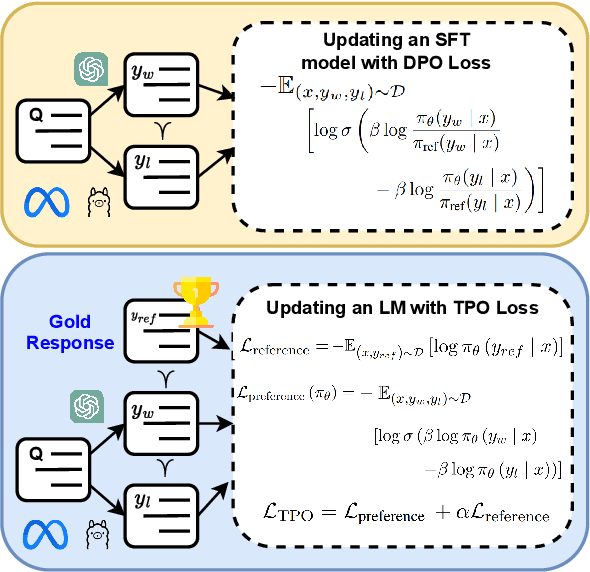



Large Language Models (LLMs) perform well across diverse tasks, but aligning them with human demonstrations is challenging. Recently, Reinforcement Learning (RL)-free methods like Direct Preference Optimization (DPO) have emerged, offering improved stability and scalability while retaining competitive performance relative to RL-based methods. However, while RL-free methods deliver satisfactory performance, they require significant data to develop a robust Supervised Fine-Tuned (SFT) model and an additional step to fine-tune this model on a preference dataset, which constrains their utility and scalability. In this paper, we introduce Triple Preference Optimization (TPO), a new preference learning method designed to align an LLM with three preferences without requiring a separate SFT step and using considerably less data. Through a combination of practical experiments and theoretical analysis, we show the efficacy of TPO as a single-step alignment strategy. Specifically, we fine-tuned the Phi-2 (2.7B) and Mistral (7B) models using TPO directly on the UltraFeedback dataset, achieving superior results compared to models aligned through other methods such as SFT, DPO, KTO, IPO, CPO, and ORPO. Moreover, the performance of TPO without the SFT component led to notable improvements in the MT-Bench score, with increases of +1.27 and +0.63 over SFT and DPO, respectively. Additionally, TPO showed higher average accuracy, surpassing DPO and SFT by 4.2% and 4.97% on the Open LLM Leaderboard benchmarks. Our code is publicly available at https://github.com/sahsaeedi/triple-preference-optimization .
Insights into Alignment: Evaluating DPO and its Variants Across Multiple Tasks
Apr 23, 2024



Large Language Models (LLMs) have demonstrated remarkable performance across a spectrum of tasks. Recently, Direct Preference Optimization (DPO) has emerged as an RL-free approach to optimize the policy model on human preferences. However, several limitations hinder the widespread adoption of this method. To address these shortcomings, various versions of DPO have been introduced. Yet, a comprehensive evaluation of these variants across diverse tasks is still lacking. In this study, we aim to bridge this gap by investigating the performance of alignment methods across three distinct scenarios: (1) keeping the Supervised Fine-Tuning (SFT) part, (2) skipping the SFT part, and (3) skipping the SFT part and utilizing an instruction-tuned model. Furthermore, we explore the impact of different training sizes on their performance. Our evaluation spans a range of tasks including dialogue systems, reasoning, mathematical problem-solving, question answering, truthfulness, and multi-task understanding, encompassing 13 benchmarks such as MT-Bench, Big Bench, and Open LLM Leaderboard. Key observations reveal that alignment methods achieve optimal performance with smaller training data subsets, exhibit limited effectiveness in reasoning tasks yet significantly impact mathematical problem-solving, and employing an instruction-tuned model notably influences truthfulness. We anticipate that our findings will catalyze further research aimed at developing more robust models to address alignment challenges.