 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartQA-X: Generating Explanations for Charts
Apr 17, 2025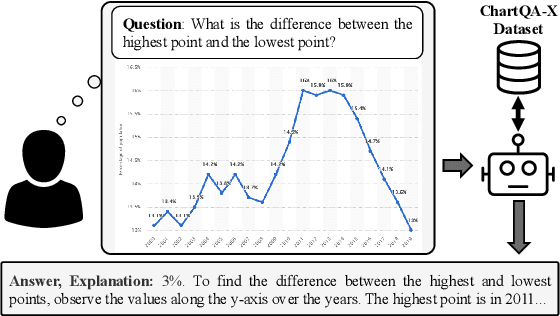



The ability to interpret and explain complex information from visual data in charts is crucial for data-driven decision-making. In this work, we address the challenge of providing explanations alongside answering questions about chart images. We present ChartQA-X, a comprehensive dataset comprising various chart types with 28,299 contextually relevant questions, answers, and detailed explanations. These explanations are generated by prompting six different models and selecting the best responses based on metrics such as faithfulness, informativeness, coherence, and perplexity. Our experiments show that models fine-tuned on our dataset for explanation generation achieve superior performance across various metrics and demonstrate improved accuracy in question-answering tasks on new datasets. By integrating answers with explanatory narratives, our approach enhances the ability of intelligent agents to convey complex information effectively, improve user understanding, and foster trust in the generated responses.
Dual Caption Preference Optimization for Diffusion Models
Feb 09, 2025


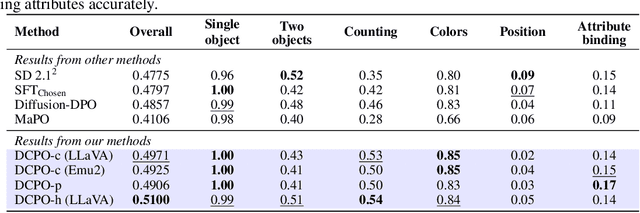
Recent advancements in human preference optimization, originally developed for Large Language Models (LLMs), have shown significant potential in improving text-to-image diffusion models. These methods aim to learn the distribution of preferred samples while distinguishing them from less preferred ones. However, existing preference datasets often exhibit overlap between these distributions, leading to a conflict distribution. Additionally, we identified that input prompts contain irrelevant information for less preferred images, limiting the denoising network's ability to accurately predict noise in preference optimization methods, known as the irrelevant prompt issue. To address these challenges, we propose Dual Caption Preference Optimization (DCPO), a novel approach that utilizes two distinct captions to mitigate irrelevant prompts. To tackle conflict distribution, we introduce the Pick-Double Caption dataset, a modified version of Pick-a-Pic v2 with separate captions for preferred and less preferred images. We further propose three different strategies for generating distinct captions: captioning, perturbation, and hybrid methods. Our experiments show that DCPO significantly improves image quality and relevance to prompts, outperforming Stable Diffusion (SD) 2.1, SFT_Chosen, Diffusion-DPO, and MaPO across multiple metrics, including Pickscore, HPSv2.1, GenEval, CLIPscore, and ImageReward, fine-tuned on SD 2.1 as the backbone.
Making the V in Text-VQA Matter
Aug 01, 2023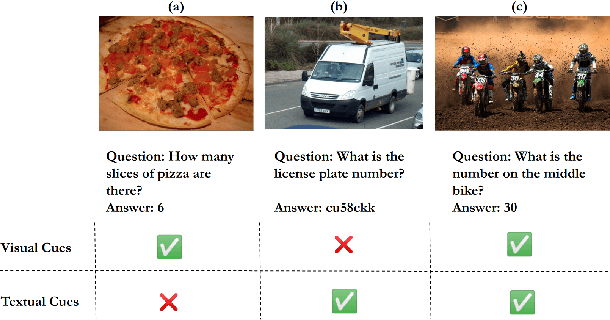


Text-based VQA aims at answering questions by reading the text present in the images. It requires a large amount of scene-text relationship understanding compared to the VQA task. Recent studies have shown that the question-answer pairs in the dataset are more focused on the text present in the image but less importance is given to visual features and some questions do not require understanding the image. The models trained on this dataset predict biased answers due to the lack of understanding of visual context. For example, in questions like "What is written on the signboard?", the answer predicted by the model is always "STOP" which makes the model to ignore the image. To address these issues, we propose a method to learn visual features (making V matter in TextVQA) along with the OCR features and question features using VQA dataset as external knowledge for Text-based VQA. Specifically, we combine the TextVQA dataset and VQA dataset and train the model on this combined dataset. Such a simple, yet effective approach increases the understanding and correlation between the image features and text present in the image, which helps in the better answering of questions. We further test the model on different datasets and compare their qualitative and quantitative results.
Weakly Supervised Visual Question Answer Generation
Jun 11, 2023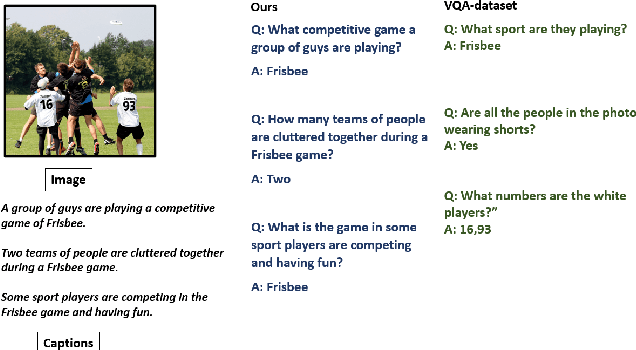

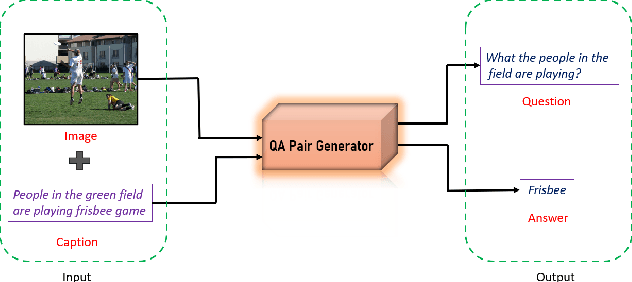

Growing interest in conversational agents promote twoway human-computer communications involving asking and answering visual questions have become an active area of research in AI. Thus, generation of visual questionanswer pair(s) becomes an important and challenging task. To address this issue, we propose a weakly-supervised visual question answer generation method that generates a relevant question-answer pairs for a given input image and associated caption. Most of the prior works are supervised and depend on the annotated question-answer datasets. In our work, we present a weakly supervised method that synthetically generates question-answer pairs procedurally from visual information and captions. The proposed method initially extracts list of answer words, then does nearest question generation that uses the caption and answer word to generate synthetic question. Next, the relevant question generator converts the nearest question to relevant language question by dependency parsing and in-order tree traversal, finally, fine-tune a ViLBERT model with the question-answer pair(s) generated at end. We perform an exhaustive experimental analysis on VQA dataset and see that our model significantly outperform SOTA methods on BLEU scores. We also show the results wrt baseline models and ablation study.