 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLaVA Meets Objects: Token Composition for Vision-Language-Models
Feb 04, 2026Current autoregressive Vision Language Models (VLMs) usually rely on a large number of visual tokens to represent images, resulting in a need for more compute especially at inference time. To address this problem, we propose Mask-LLaVA, a framework that leverages different levels of visual features to create a compact yet information-rich visual representation for autoregressive VLMs. Namely, we combine mask-based object representations together with global tokens and local patch tokens. While all tokens are used during training, it shows that the resulting model can flexibly drop especially the number of mask-based object-tokens at test time, allowing to adapt the number of tokens during inference without the need to retrain the model and without a significant drop in performance. We evaluate the proposed approach on a suite of standard benchmarks showing results competitive to current token efficient methods and comparable to the original LLaVA baseline using only a fraction of visual tokens. Our analysis demonstrates that combining multi-level features enables efficient learning with fewer tokens while allowing dynamic token selection at test time for good performance.
Understanding Video Scenes through Text: Insights from Text-based Video Question Answering
Sep 11, 2023Researchers have extensively studied the field of vision and language, discovering that both visual and textual content is crucial for understanding scenes effectively. Particularly, comprehending text in videos holds great significance, requiring both scene text understanding and temporal reasoning. This paper focuses on exploring two recently introduced datasets, NewsVideoQA and M4-ViteVQA, which aim to address video question answering based on textual content. The NewsVideoQA dataset contains question-answer pairs related to the text in news videos, while M4-ViteVQA comprises question-answer pairs from diverse categories like vlogging, traveling, and shopping. We provide an analysis of the formulation of these datasets on various levels, exploring the degree of visual understanding and multi-frame comprehension required for answering the questions. Additionally, the study includes experimentation with BERT-QA, a text-only model, which demonstrates comparable performance to the original methods on both datasets, indicating the shortcomings in the formulation of these datasets. Furthermore, we also look into the domain adaptation aspect by examining the effectiveness of training on M4-ViteVQA and evaluating on NewsVideoQA and vice-versa, thereby shedding light on the challenges and potential benefits of out-of-domain training.
Making the V in Text-VQA Matter
Aug 01, 2023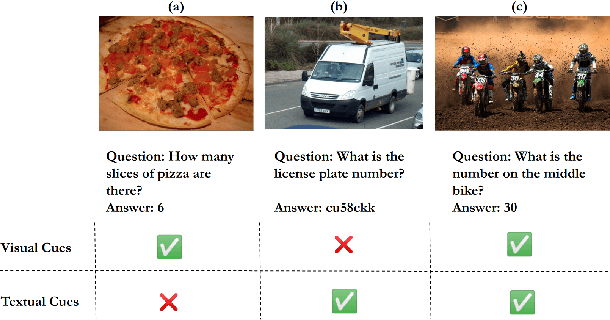

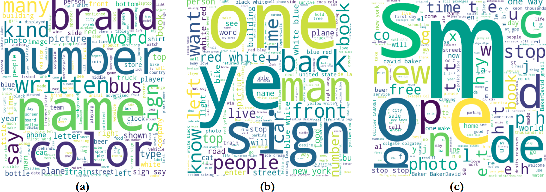

Text-based VQA aims at answering questions by reading the text present in the images. It requires a large amount of scene-text relationship understanding compared to the VQA task. Recent studies have shown that the question-answer pairs in the dataset are more focused on the text present in the image but less importance is given to visual features and some questions do not require understanding the image. The models trained on this dataset predict biased answers due to the lack of understanding of visual context. For example, in questions like "What is written on the signboard?", the answer predicted by the model is always "STOP" which makes the model to ignore the image. To address these issues, we propose a method to learn visual features (making V matter in TextVQA) along with the OCR features and question features using VQA dataset as external knowledge for Text-based VQA. Specifically, we combine the TextVQA dataset and VQA dataset and train the model on this combined dataset. Such a simple, yet effective approach increases the understanding and correlation between the image features and text present in the image, which helps in the better answering of questions. We further test the model on different datasets and compare their qualitative and quantitative results.
Weakly Supervised Visual Question Answer Generation
Jun 11, 2023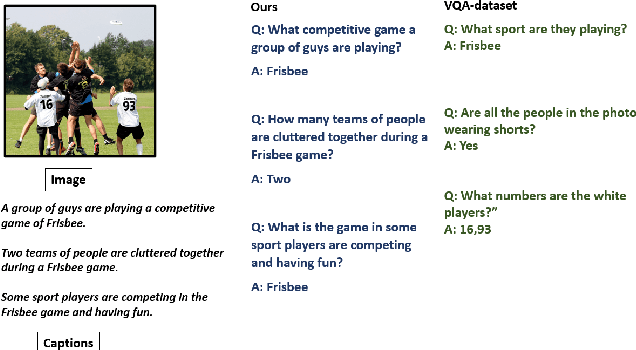

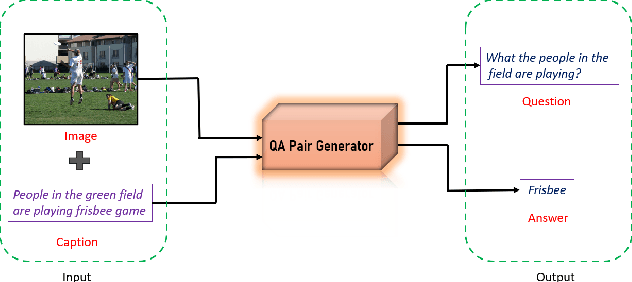

Growing interest in conversational agents promote twoway human-computer communications involving asking and answering visual questions have become an active area of research in AI. Thus, generation of visual questionanswer pair(s) becomes an important and challenging task. To address this issue, we propose a weakly-supervised visual question answer generation method that generates a relevant question-answer pairs for a given input image and associated caption. Most of the prior works are supervised and depend on the annotated question-answer datasets. In our work, we present a weakly supervised method that synthetically generates question-answer pairs procedurally from visual information and captions. The proposed method initially extracts list of answer words, then does nearest question generation that uses the caption and answer word to generate synthetic question. Next, the relevant question generator converts the nearest question to relevant language question by dependency parsing and in-order tree traversal, finally, fine-tune a ViLBERT model with the question-answer pair(s) generated at end. We perform an exhaustive experimental analysis on VQA dataset and see that our model significantly outperform SOTA methods on BLEU scores. We also show the results wrt baseline models and ablation study.
Look, Read and Ask: Learning to Ask Questions by Reading Text in Images
Nov 23, 2022We present a novel problem of text-based visual question generation or TextVQG in short. Given the recent growing interest of the document image analysis community in combining text understanding with conversational artificial intelligence, e.g., text-based visual question answering, TextVQG becomes an important task. TextVQG aims to generate a natural language question for a given input image and an automatically extracted text also known as OCR token from it such that the OCR token is an answer to the generated question. TextVQG is an essential ability for a conversational agent. However, it is challenging as it requires an in-depth understanding of the scene and the ability to semantically bridge the visual content with the text present in the image. To address TextVQG, we present an OCR consistent visual question generation model that Looks into the visual content, Reads the scene text, and Asks a relevant and meaningful natural language question. We refer to our proposed model as OLRA. We perform an extensive evaluation of OLRA on two public benchmarks and compare them against baselines. Our model OLRA automatically generates questions similar to the public text-based visual question answering datasets that were curated manually. Moreover, we significantly outperform baseline approaches on the performance measures popularly used in text generation literature.
Watching the News: Towards VideoQA Models that can Read
Nov 10, 2022Video Question Answering methods focus on commonsense reasoning and visual cognition of objects or persons and their interactions over time. Current VideoQA approaches ignore the textual information present in the video. Instead, we argue that textual information is complementary to the action and provides essential contextualisation cues to the reasoning process. To this end, we propose a novel VideoQA task that requires reading and understanding the text in the video. To explore this direction, we focus on news videos and require QA systems to comprehend and answer questions about the topics presented by combining visual and textual cues in the video. We introduce the ``NewsVideoQA'' dataset that comprises more than $8,600$ QA pairs on $3,000+$ news videos obtained from diverse news channels from around the world. We demonstrate the limitations of current Scene Text VQA and VideoQA methods and propose ways to incorporate scene text information into VideoQA methods.