 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICPR 2024 Competition on Rider Intention Prediction
Mar 11, 2025The recent surge in the vehicle market has led to an alarming increase in road accidents. This underscores the critical importance of enhancing road safety measures, particularly for vulnerable road users like motorcyclists. Hence, we introduce the rider intention prediction (RIP) competition that aims to address challenges in rider safety by proactively predicting maneuvers before they occur, thereby strengthening rider safety. This capability enables the riders to react to the potential incorrect maneuvers flagged by advanced driver assistance systems (ADAS). We collect a new dataset, namely, rider action anticipation dataset (RAAD) for the competition consisting of two tasks: single-view RIP and multi-view RIP. The dataset incorporates a spectrum of traffic conditions and challenging navigational maneuvers on roads with varying lighting conditions. For the competition, we received seventy-five registrations and five team submissions for inference of which we compared the methods of the top three performing teams on both the RIP tasks: one state-space model (Mamba2) and two learning-based approaches (SVM and CNN-LSTM). The results indicate that the state-space model outperformed the other methods across the entire dataset, providing a balanced performance across maneuver classes. The SVM-based RIP method showed the second-best performance when using random sampling and SMOTE. However, the CNN-LSTM method underperformed, primarily due to class imbalance issues, particularly struggling with minority classes. This paper details the proposed RAAD dataset and provides a summary of the submissions for the RIP 2024 competition.
Making the V in Text-VQA Matter
Aug 01, 2023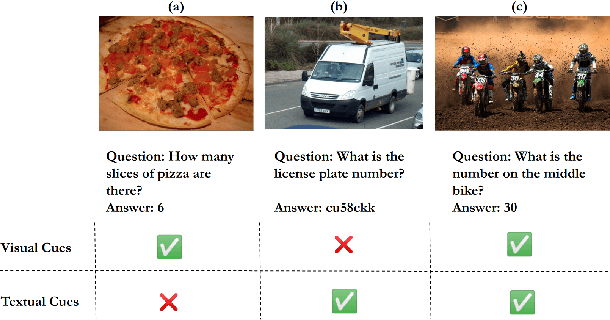


Text-based VQA aims at answering questions by reading the text present in the images. It requires a large amount of scene-text relationship understanding compared to the VQA task. Recent studies have shown that the question-answer pairs in the dataset are more focused on the text present in the image but less importance is given to visual features and some questions do not require understanding the image. The models trained on this dataset predict biased answers due to the lack of understanding of visual context. For example, in questions like "What is written on the signboard?", the answer predicted by the model is always "STOP" which makes the model to ignore the image. To address these issues, we propose a method to learn visual features (making V matter in TextVQA) along with the OCR features and question features using VQA dataset as external knowledge for Text-based VQA. Specifically, we combine the TextVQA dataset and VQA dataset and train the model on this combined dataset. Such a simple, yet effective approach increases the understanding and correlation between the image features and text present in the image, which helps in the better answering of questions. We further test the model on different datasets and compare their qualitative and quantitative results.
Weakly Supervised Visual Question Answer Generation
Jun 11, 2023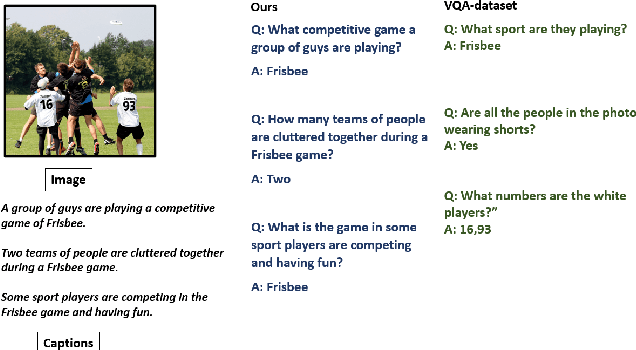

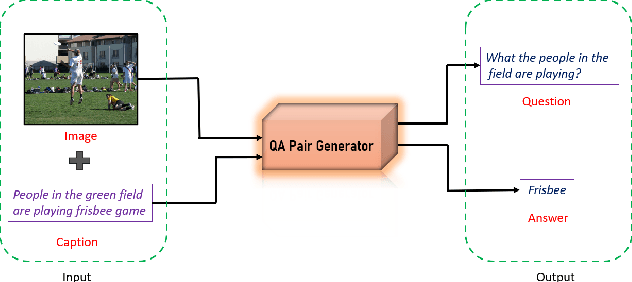

Growing interest in conversational agents promote twoway human-computer communications involving asking and answering visual questions have become an active area of research in AI. Thus, generation of visual questionanswer pair(s) becomes an important and challenging task. To address this issue, we propose a weakly-supervised visual question answer generation method that generates a relevant question-answer pairs for a given input image and associated caption. Most of the prior works are supervised and depend on the annotated question-answer datasets. In our work, we present a weakly supervised method that synthetically generates question-answer pairs procedurally from visual information and captions. The proposed method initially extracts list of answer words, then does nearest question generation that uses the caption and answer word to generate synthetic question. Next, the relevant question generator converts the nearest question to relevant language question by dependency parsing and in-order tree traversal, finally, fine-tune a ViLBERT model with the question-answer pair(s) generated at end. We perform an exhaustive experimental analysis on VQA dataset and see that our model significantly outperform SOTA methods on BLEU scores. We also show the results wrt baseline models and ablation study.
Look, Read and Ask: Learning to Ask Questions by Reading Text in Images
Nov 23, 2022We present a novel problem of text-based visual question generation or TextVQG in short. Given the recent growing interest of the document image analysis community in combining text understanding with conversational artificial intelligence, e.g., text-based visual question answering, TextVQG becomes an important task. TextVQG aims to generate a natural language question for a given input image and an automatically extracted text also known as OCR token from it such that the OCR token is an answer to the generated question. TextVQG is an essential ability for a conversational agent. However, it is challenging as it requires an in-depth understanding of the scene and the ability to semantically bridge the visual content with the text present in the image. To address TextVQG, we present an OCR consistent visual question generation model that Looks into the visual content, Reads the scene text, and Asks a relevant and meaningful natural language question. We refer to our proposed model as OLRA. We perform an extensive evaluation of OLRA on two public benchmarks and compare them against baselines. Our model OLRA automatically generates questions similar to the public text-based visual question answering datasets that were curated manually. Moreover, we significantly outperform baseline approaches on the performance measures popularly used in text generation literature.
PIG-Net: Inception based Deep Learning Architecture for 3D Point Cloud Segmentation
Jan 28, 2021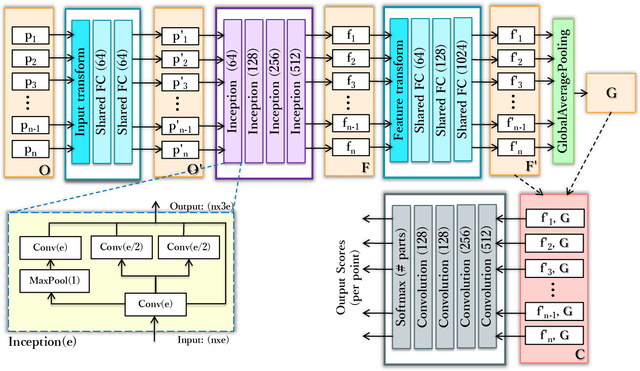



Point clouds, being the simple and compact representation of surface geometry of 3D objects, have gained increasing popularity with the evolution of deep learning networks for classification and segmentation tasks. Unlike human, teaching the machine to analyze the segments of an object is a challenging task and quite essential in various machine vision applications. In this paper, we address the problem of segmentation and labelling of the 3D point clouds by proposing a inception based deep network architecture called PIG-Net, that effectively characterizes the local and global geometric details of the point clouds. In PIG-Net, the local features are extracted from the transformed input points using the proposed inception layers and then aligned by feature transform. These local features are aggregated using the global average pooling layer to obtain the global features. Finally, feed the concatenated local and global features to the convolution layers for segmenting the 3D point clouds. We perform an exhaustive experimental analysis of the PIG-Net architecture on two state-of-the-art datasets, namely, ShapeNet [1] and PartNet [2]. We evaluate the effectiveness of our network by performing ablation study.