 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICPR 2024 Competition on Rider Intention Prediction
Mar 11, 2025The recent surge in the vehicle market has led to an alarming increase in road accidents. This underscores the critical importance of enhancing road safety measures, particularly for vulnerable road users like motorcyclists. Hence, we introduce the rider intention prediction (RIP) competition that aims to address challenges in rider safety by proactively predicting maneuvers before they occur, thereby strengthening rider safety. This capability enables the riders to react to the potential incorrect maneuvers flagged by advanced driver assistance systems (ADAS). We collect a new dataset, namely, rider action anticipation dataset (RAAD) for the competition consisting of two tasks: single-view RIP and multi-view RIP. The dataset incorporates a spectrum of traffic conditions and challenging navigational maneuvers on roads with varying lighting conditions. For the competition, we received seventy-five registrations and five team submissions for inference of which we compared the methods of the top three performing teams on both the RIP tasks: one state-space model (Mamba2) and two learning-based approaches (SVM and CNN-LSTM). The results indicate that the state-space model outperformed the other methods across the entire dataset, providing a balanced performance across maneuver classes. The SVM-based RIP method showed the second-best performance when using random sampling and SMOTE. However, the CNN-LSTM method underperformed, primarily due to class imbalance issues, particularly struggling with minority classes. This paper details the proposed RAAD dataset and provides a summary of the submissions for the RIP 2024 competition.
Predicting Outcome of Indian Premier League (IPL) Matches Using Machine Learning
Oct 11, 2018


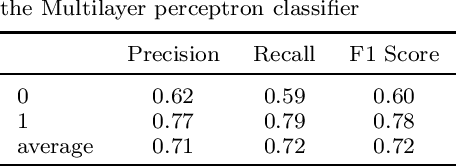
Cricket, especially the twenty20 format, has maximum uncertainty, where a single over can completely change the momentum of the game. With millions of people following the Indian Premier League, therefore developing a model for predicting the outcome of its matches beforehand is a real-world problem. A cricket match depends upon various factors, and in this work, various feature selection methods were used to reduce the number of features to 5 from 15. Player's performance in the field is considered to find out the overall weightage (relative strength) of the team. A Linear Regression based solution is proposed to calculate the weightage of a team based on the past performance of its players who have appeared most for the team. Finally, a dataset with the features: home team, away team, stadium, toss winner, toss decision, home-team-weightage and away-team-weightage is fed to a Random Forest Classifier to train the model and make a prediction on unseen matches. Classification results are satisfactory. The problems in the dataset and how the accuracy of the classifier can be improved is discussed.