 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoad Obstacle Video Segmentation
Sep 16, 2025With the growing deployment of autonomous driving agents, the detection and segmentation of road obstacles have become critical to ensure safe autonomous navigation. However, existing road-obstacle segmentation methods are applied on individual frames, overlooking the temporal nature of the problem, leading to inconsistent prediction maps between consecutive frames. In this work, we demonstrate that the road-obstacle segmentation task is inherently temporal, since the segmentation maps for consecutive frames are strongly correlated. To address this, we curate and adapt four evaluation benchmarks for road-obstacle video segmentation and evaluate 11 state-of-the-art image- and video-based segmentation methods on these benchmarks. Moreover, we introduce two strong baseline methods based on vision foundation models. Our approach establishes a new state-of-the-art in road-obstacle video segmentation for long-range video sequences, providing valuable insights and direction for future research.
ICPR 2024 Competition on Rider Intention Prediction
Mar 11, 2025The recent surge in the vehicle market has led to an alarming increase in road accidents. This underscores the critical importance of enhancing road safety measures, particularly for vulnerable road users like motorcyclists. Hence, we introduce the rider intention prediction (RIP) competition that aims to address challenges in rider safety by proactively predicting maneuvers before they occur, thereby strengthening rider safety. This capability enables the riders to react to the potential incorrect maneuvers flagged by advanced driver assistance systems (ADAS). We collect a new dataset, namely, rider action anticipation dataset (RAAD) for the competition consisting of two tasks: single-view RIP and multi-view RIP. The dataset incorporates a spectrum of traffic conditions and challenging navigational maneuvers on roads with varying lighting conditions. For the competition, we received seventy-five registrations and five team submissions for inference of which we compared the methods of the top three performing teams on both the RIP tasks: one state-space model (Mamba2) and two learning-based approaches (SVM and CNN-LSTM). The results indicate that the state-space model outperformed the other methods across the entire dataset, providing a balanced performance across maneuver classes. The SVM-based RIP method showed the second-best performance when using random sampling and SMOTE. However, the CNN-LSTM method underperformed, primarily due to class imbalance issues, particularly struggling with minority classes. This paper details the proposed RAAD dataset and provides a summary of the submissions for the RIP 2024 competition.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
Mask2Anomaly: Mask Transformer for Universal Open-set Segmentation
Sep 12, 2023Segmenting unknown or anomalous object instances is a critical task in autonomous driving applications, and it is approached traditionally as a per-pixel classification problem. However, reasoning individually about each pixel without considering their contextual semantics results in high uncertainty around the objects' boundaries and numerous false positives. We propose a paradigm change by shifting from a per-pixel classification to a mask classification. Our mask-based method, Mask2Anomaly, demonstrates the feasibility of integrating a mask-classification architecture to jointly address anomaly segmentation, open-set semantic segmentation, and open-set panoptic segmentation. Mask2Anomaly includes several technical novelties that are designed to improve the detection of anomalies/unknown objects: i) a global masked attention module to focus individually on the foreground and background regions; ii) a mask contrastive learning that maximizes the margin between an anomaly and known classes; iii) a mask refinement solution to reduce false positives; and iv) a novel approach to mine unknown instances based on the mask-architecture properties. By comprehensive qualitative and qualitative evaluation, we show Mask2Anomaly achieves new state-of-the-art results across the benchmarks of anomaly segmentation, open-set semantic segmentation, and open-set panoptic segmentation.
Unmasking Anomalies in Road-Scene Segmentation
Jul 25, 2023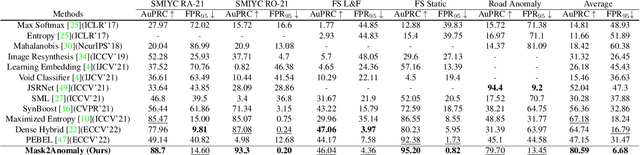
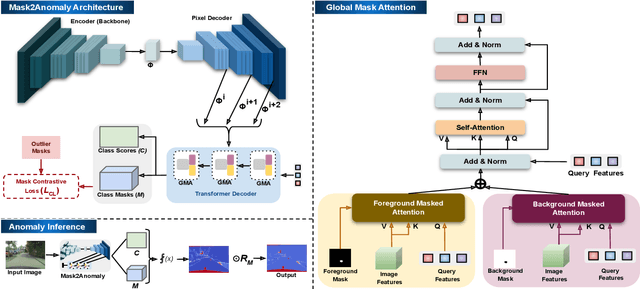
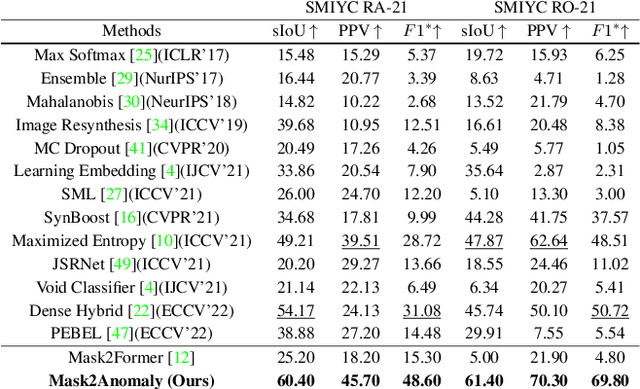

Anomaly segmentation is a critical task for driving applications, and it is approached traditionally as a per-pixel classification problem. However, reasoning individually about each pixel without considering their contextual semantics results in high uncertainty around the objects' boundaries and numerous false positives. We propose a paradigm change by shifting from a per-pixel classification to a mask classification. Our mask-based method, Mask2Anomaly, demonstrates the feasibility of integrating an anomaly detection method in a mask-classification architecture. Mask2Anomaly includes several technical novelties that are designed to improve the detection of anomalies in masks: i) a global masked attention module to focus individually on the foreground and background regions; ii) a mask contrastive learning that maximizes the margin between an anomaly and known classes; and iii) a mask refinement solution to reduce false positives. Mask2Anomaly achieves new state-of-the-art results across a range of benchmarks, both in the per-pixel and component-level evaluations. In particular, Mask2Anomaly reduces the average false positives rate by 60% wrt the previous state-of-the-art. Github page: https://github.com/shyam671/Mask2Anomaly-Unmasking-Anomalies-in-Road-Scene-Segmentation.