 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEAST: A Flexible Mealtime-Assistance System Towards In-the-Wild Personalization
Jun 17, 2025Physical caregiving robots hold promise for improving the quality of life of millions worldwide who require assistance with feeding. However, in-home meal assistance remains challenging due to the diversity of activities (e.g., eating, drinking, mouth wiping), contexts (e.g., socializing, watching TV), food items, and user preferences that arise during deployment. In this work, we propose FEAST, a flexible mealtime-assistance system that can be personalized in-the-wild to meet the unique needs of individual care recipients. Developed in collaboration with two community researchers and informed by a formative study with a diverse group of care recipients, our system is guided by three key tenets for in-the-wild personalization: adaptability, transparency, and safety. FEAST embodies these principles through: (i) modular hardware that enables switching between assisted feeding, drinking, and mouth-wiping, (ii) diverse interaction methods, including a web interface, head gestures, and physical buttons, to accommodate diverse functional abilities and preferences, and (iii) parameterized behavior trees that can be safely and transparently adapted using a large language model. We evaluate our system based on the personalization requirements identified in our formative study, demonstrating that FEAST offers a wide range of transparent and safe adaptations and outperforms a state-of-the-art baseline limited to fixed customizations. To demonstrate real-world applicability, we conduct an in-home user study with two care recipients (who are community researchers), feeding them three meals each across three diverse scenarios. We further assess FEAST's ecological validity by evaluating with an Occupational Therapist previously unfamiliar with the system. In all cases, users successfully personalize FEAST to meet their individual needs and preferences. Website: https://emprise.cs.cornell.edu/feast
Long-RVOS: A Comprehensive Benchmark for Long-term Referring Video Object Segmentation
May 19, 2025Referring video object segmentation (RVOS) aims to identify, track and segment the objects in a video based on language descriptions, which has received great attention in recent years. However, existing datasets remain focus on short video clips within several seconds, with salient objects visible in most frames. To advance the task towards more practical scenarios, we introduce \textbf{Long-RVOS}, a large-scale benchmark for long-term referring video object segmentation. Long-RVOS contains 2,000+ videos of an average duration exceeding 60 seconds, covering a variety of objects that undergo occlusion, disappearance-reappearance and shot changing. The objects are manually annotated with three different types of descriptions to individually evaluate the understanding of static attributes, motion patterns and spatiotemporal relationships. Moreover, unlike previous benchmarks that rely solely on the per-frame spatial evaluation, we introduce two new metrics to assess the temporal and spatiotemporal consistency. We benchmark 6 state-of-the-art methods on Long-RVOS. The results show that current approaches struggle severely with the long-video challenges. To address this, we further propose ReferMo, a promising baseline method that integrates motion information to expand the temporal receptive field, and employs a local-to-global architecture to capture both short-term dynamics and long-term dependencies. Despite simplicity, ReferMo achieves significant improvements over current methods in long-term scenarios. We hope that Long-RVOS and our baseline can drive future RVOS research towards tackling more realistic and long-form videos.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025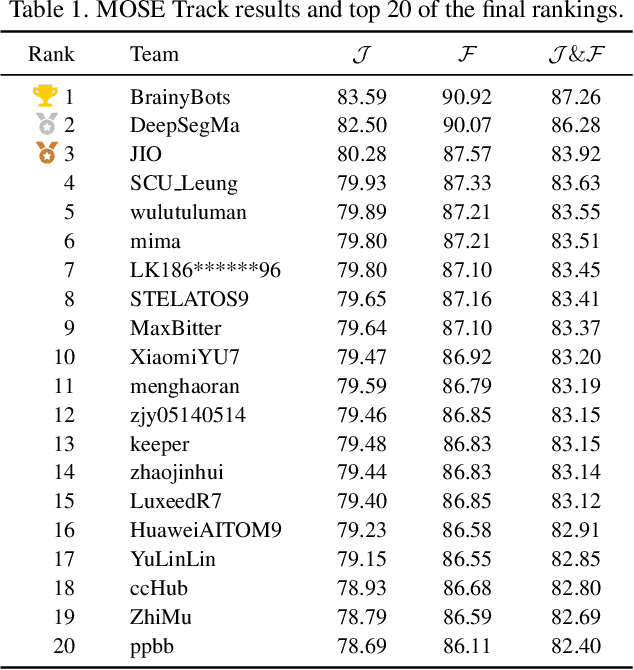
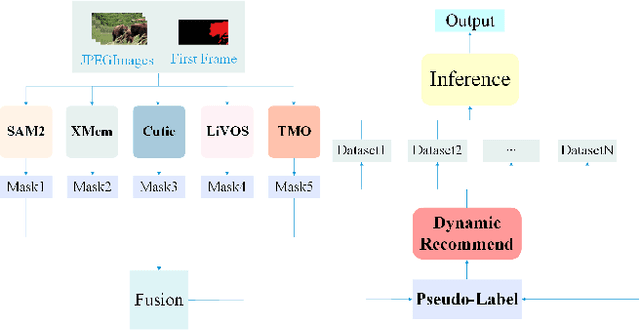
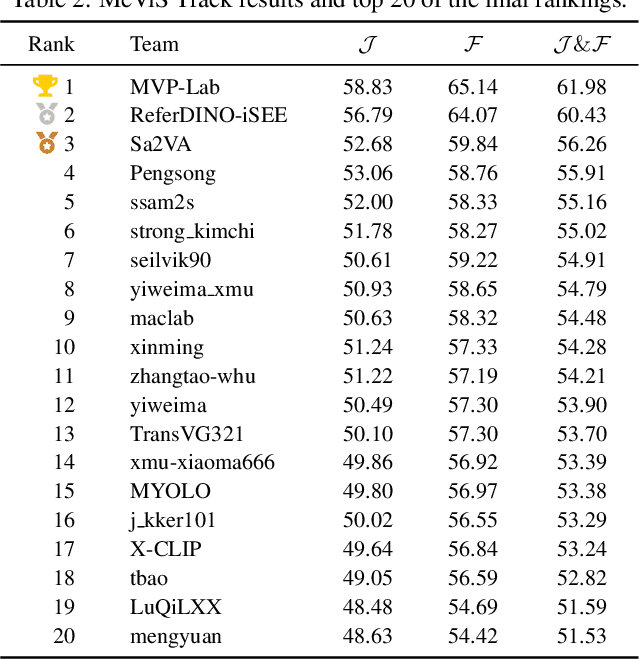
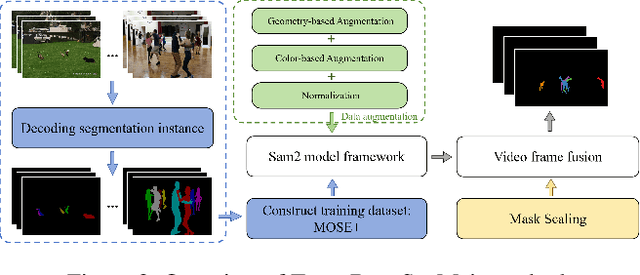
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
FVOS for MOSE Track of 4th PVUW Challenge: 3rd Place Solution
Apr 13, 2025Video Object Segmentation (VOS) is one of the most fundamental and challenging tasks in computer vision and has a wide range of applications. Most existing methods rely on spatiotemporal memory networks to extract frame-level features and have achieved promising results on commonly used datasets. However, these methods often struggle in more complex real-world scenarios. This paper addresses this issue, aiming to achieve accurate segmentation of video objects in challenging scenes. We propose fine-tuning VOS (FVOS), optimizing existing methods for specific datasets through tailored training. Additionally, we introduce a morphological post-processing strategy to address the issue of excessively large gaps between adjacent objects in single-model predictions. Finally, we apply a voting-based fusion method on multi-scale segmentation results to generate the final output. Our approach achieves J&F scores of 76.81% and 83.92% during the validation and testing stages, respectively, securing third place overall in the MOSE Track of the 4th PVUW challenge 2025.
Classic Video Denoising in a Machine Learning World: Robust, Fast, and Controllable
Apr 04, 2025Denoising is a crucial step in many video processing pipelines such as in interactive editing, where high quality, speed, and user control are essential. While recent approaches achieve significant improvements in denoising quality by leveraging deep learning, they are prone to unexpected failures due to discrepancies between training data distributions and the wide variety of noise patterns found in real-world videos. These methods also tend to be slow and lack user control. In contrast, traditional denoising methods perform reliably on in-the-wild videos and run relatively quickly on modern hardware. However, they require manually tuning parameters for each input video, which is not only tedious but also requires skill. We bridge the gap between these two paradigms by proposing a differentiable denoising pipeline based on traditional methods. A neural network is then trained to predict the optimal denoising parameters for each specific input, resulting in a robust and efficient approach that also supports user control.
AI-Based Teat Shape and Skin Condition Prediction for Dairy Management
Dec 22, 2024Dairy owners spend significant effort to keep their animals healthy. There is good reason to hope that technologies such as computer vision and artificial intelligence (AI) could reduce these costs, yet obstacles arise when adapting advanced tools to farming environments. In this work, we adapt AI tools to dairy cow teat localization, teat shape, and teat skin condition classifications. We also curate a data collection and analysis methodology for a Machine Learning (ML) pipeline. The resulting teat shape prediction model achieves a mean Average Precision (mAP) of 0.783, and the teat skin condition model achieves a mean average precision of 0.828. Our work leverages existing ML vision models to facilitate the individualized identification of teat health and skin conditions, applying AI to the dairy management industry.
Improving the Multi-label Atomic Activity Recognition by Robust Visual Feature and Advanced Attention @ ROAD++ Atomic Activity Recognition 2024
Oct 21, 2024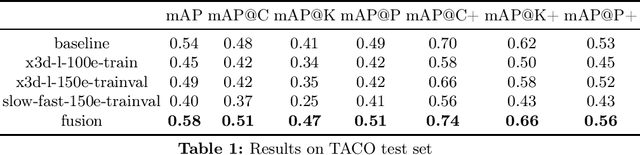
Road++ Track3 proposes a multi-label atomic activity recognition task in traffic scenarios, which can be standardized as a 64-class multi-label video action recognition task. In the multi-label atomic activity recognition task, the robustness of visual feature extraction remains a key challenge, which directly affects the model performance and generalization ability. To cope with these issues, our team optimized three aspects: data processing, model and post-processing. Firstly, the appropriate resolution and video sampling strategy are selected, and a fixed sampling strategy is set on the validation and test sets. Secondly, in terms of model training, the team selects a variety of visual backbone networks for feature extraction, and then introduces the action-slot model, which is trained on the training and validation sets, and reasoned on the test set. Finally, for post-processing, the team combined the strengths and weaknesses of different models for weighted fusion, and the final mAP on the test set was 58%, which is 4% higher than the challenge baseline.
SoccerNet 2024 Challenges Results
Sep 16, 2024

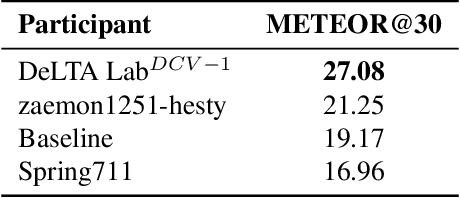
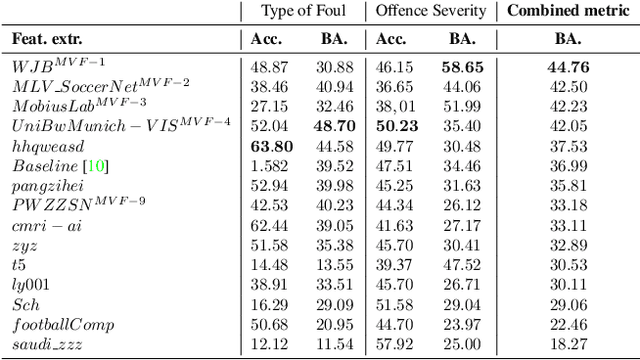
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.