 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassing the Baton: High Throughput Distributed Disk-Based Vector Search with BatANN
Dec 10, 2025



Vector search underpins modern information-retrieval systems, including retrieval-augmented generation (RAG) pipelines and search engines over unstructured text and images. As datasets scale to billions of vectors, disk-based vector search has emerged as a practical solution. However, looking to the future, we need to anticipate datasets too large for any single server. We present BatANN, a distributed disk-based approximate nearest neighbor (ANN) system that retains the logarithmic search efficiency of a single global graph while achieving near-linear throughput scaling in the number of servers. Our core innovation is that when accessing a neighborhood which is stored on another machine, we send the full state of the query to the other machine to continue executing there for improved locality. On 100M- and 1B-point datasets at 0.95 recall using 10 servers, BatANN achieves 6.21-6.49x and 2.5-5.10x the throughput of the scatter-gather baseline, respectively, while maintaining mean latency below 6 ms. Moreover, we get these results on standard TCP. To our knowledge, BatANN is the first open-source distributed disk-based vector search system to operate over a single global graph.
AI-Based Teat Shape and Skin Condition Prediction for Dairy Management
Dec 22, 2024Dairy owners spend significant effort to keep their animals healthy. There is good reason to hope that technologies such as computer vision and artificial intelligence (AI) could reduce these costs, yet obstacles arise when adapting advanced tools to farming environments. In this work, we adapt AI tools to dairy cow teat localization, teat shape, and teat skin condition classifications. We also curate a data collection and analysis methodology for a Machine Learning (ML) pipeline. The resulting teat shape prediction model achieves a mean Average Precision (mAP) of 0.783, and the teat skin condition model achieves a mean average precision of 0.828. Our work leverages existing ML vision models to facilitate the individualized identification of teat health and skin conditions, applying AI to the dairy management industry.
Compass: A Decentralized Scheduler for Latency-Sensitive ML Workflows
Feb 28, 2024



We consider ML query processing in distributed systems where GPU-enabled workers coordinate to execute complex queries: a computing style often seen in applications that interact with users in support of image processing and natural language processing. In such systems, coscheduling of GPU memory management and task placement represents a promising opportunity. We propose Compass, a novel framework that unifies these functions to reduce job latency while using resources efficiently, placing tasks where data dependencies will be satisfied, collocating tasks from the same job (when this will not overload the host or its GPU), and efficiently managing GPU memory. Comparison with other state of the art schedulers shows a significant reduction in completion times while requiring the same amount or even fewer resources. In one case, just half the servers were needed for processing the same workload.
Cascade: A Platform for Delay-Sensitive Edge Intelligence
Nov 29, 2023

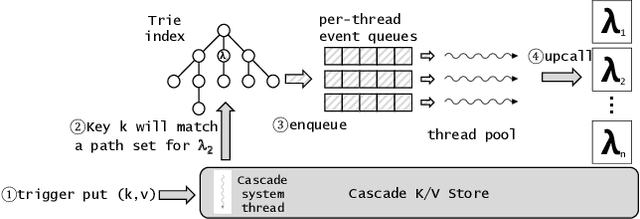
Interactive intelligent computing applications are increasingly prevalent, creating a need for AI/ML platforms optimized to reduce per-event latency while maintaining high throughput and efficient resource management. Yet many intelligent applications run on AI/ML platforms that optimize for high throughput even at the cost of high tail-latency. Cascade is a new AI/ML hosting platform intended to untangle this puzzle. Innovations include a legacy-friendly storage layer that moves data with minimal copying and a "fast path" that collocates data and computation to maximize responsiveness. Our evaluation shows that Cascade reduces latency by orders of magnitude with no loss of throughput.