 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSibylSense: Adaptive Rubric Learning via Memory Tuning and Adversarial Probing
Feb 24, 2026Designing aligned and robust rewards for open-ended generation remains a key barrier to RL post-training. Rubrics provide structured, interpretable supervision, but scaling rubric construction is difficult: expert rubrics are costly, prompted rubrics are often superficial or inconsistent, and fixed-pool discriminative rubrics can saturate and drift, enabling reward hacking. We present SibylSense, an inference-time learning approach that adapts a frozen rubric generator through a tunable memory bank of validated rubric items. Memory is updated via verifier-based item rewards measured by reference-candidate answer discriminative gaps from a handful of examples. SibylSense alternates memory tuning with a rubric-adversarial policy update that produces rubric-satisfying candidate answers, shrinking discriminative gaps and driving the rubric generator to capture new quality dimensions. Experiments on two open-ended tasks show that SibylSense yields more discriminative rubrics and improves downstream RL performance over static and non-adaptive baselines.
AI-Based Teat Shape and Skin Condition Prediction for Dairy Management
Dec 22, 2024Dairy owners spend significant effort to keep their animals healthy. There is good reason to hope that technologies such as computer vision and artificial intelligence (AI) could reduce these costs, yet obstacles arise when adapting advanced tools to farming environments. In this work, we adapt AI tools to dairy cow teat localization, teat shape, and teat skin condition classifications. We also curate a data collection and analysis methodology for a Machine Learning (ML) pipeline. The resulting teat shape prediction model achieves a mean Average Precision (mAP) of 0.783, and the teat skin condition model achieves a mean average precision of 0.828. Our work leverages existing ML vision models to facilitate the individualized identification of teat health and skin conditions, applying AI to the dairy management industry.
Compass: A Decentralized Scheduler for Latency-Sensitive ML Workflows
Feb 28, 2024



We consider ML query processing in distributed systems where GPU-enabled workers coordinate to execute complex queries: a computing style often seen in applications that interact with users in support of image processing and natural language processing. In such systems, coscheduling of GPU memory management and task placement represents a promising opportunity. We propose Compass, a novel framework that unifies these functions to reduce job latency while using resources efficiently, placing tasks where data dependencies will be satisfied, collocating tasks from the same job (when this will not overload the host or its GPU), and efficiently managing GPU memory. Comparison with other state of the art schedulers shows a significant reduction in completion times while requiring the same amount or even fewer resources. In one case, just half the servers were needed for processing the same workload.
Scale up with Order: Finding Good Data Permutations for Distributed Training
Feb 02, 2023



Gradient Balancing (GraB) is a recently proposed technique that finds provably better data permutations when training models with multiple epochs over a finite dataset. It converges at a faster rate than the widely adopted Random Reshuffling, by minimizing the discrepancy of the gradients on adjacently selected examples. However, GraB only operates under critical assumptions such as small batch sizes and centralized data, leaving open the question of how to order examples at large scale -- i.e. distributed learning with decentralized data. To alleviate the limitation, in this paper we propose D-GraB that involves two novel designs: (1) $\textsf{PairBalance}$ that eliminates the requirement to use stale gradient mean in GraB which critically relies on small learning rates; (2) an ordering protocol that runs $\textsf{PairBalance}$ in a distributed environment with negligible overhead, which benefits from both data ordering and parallelism. We prove D-GraB enjoys linear speed up at rate $\tilde{O}((mnT)^{-2/3})$ on smooth non-convex objectives and $\tilde{O}((mnT)^{-2})$ under PL condition, where $n$ denotes the number of parallel workers, $m$ denotes the number of examples per worker and $T$ denotes the number of epochs. Empirically, we show on various applications including GLUE, CIFAR10 and WikiText-2 that D-GraB outperforms naive parallel GraB and Distributed Random Reshuffling in terms of both training and validation performance.
MCTensor: A High-Precision Deep Learning Library with Multi-Component Floating-Point
Jul 18, 2022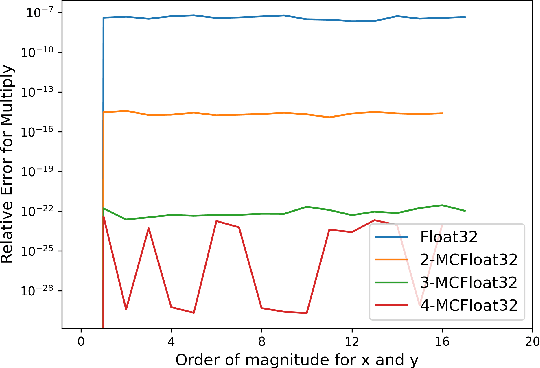

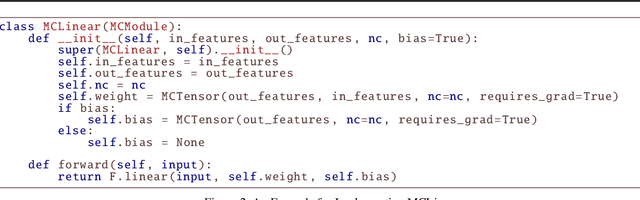
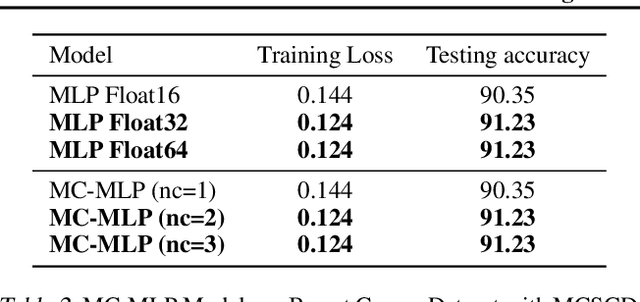
In this paper, we introduce MCTensor, a library based on PyTorch for providing general-purpose and high-precision arithmetic for DL training. MCTensor is used in the same way as PyTorch Tensor: we implement multiple basic, matrix-level computation operators and NN modules for MCTensor with identical PyTorch interface. Our algorithms achieve high precision computation and also benefits from heavily-optimized PyTorch floating-point arithmetic. We evaluate MCTensor arithmetic against PyTorch native arithmetic for a series of tasks, where models using MCTensor in float16 would match or outperform the PyTorch model with float32 or float64 precision.
XJTLUIndoorLoc: A New Fingerprinting Database for Indoor Localization and Trajectory Estimation Based on Wi-Fi RSS and Geomagnetic Field
Oct 17, 2018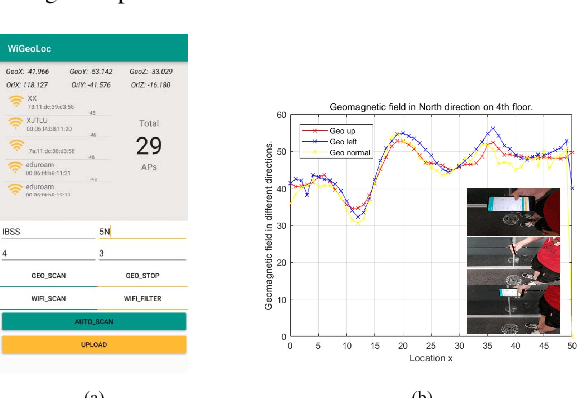
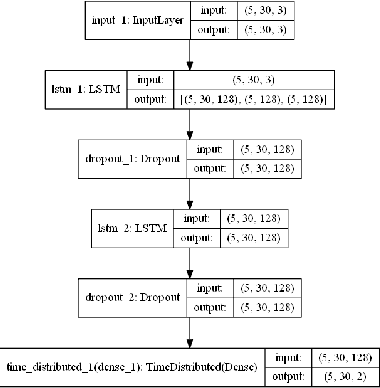
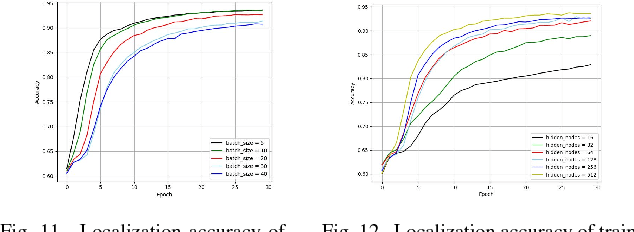
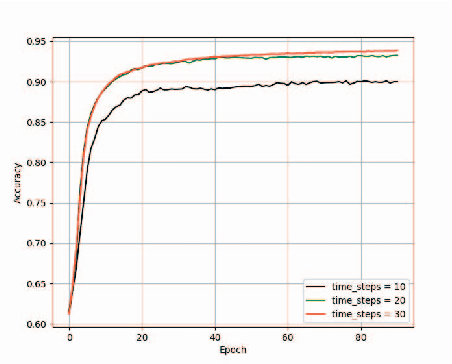
In this paper, we present a new location fingerprinting database comprised of Wi-Fi received signal strength (RSS) and geomagnetic field intensity measured with multiple devices at a multi-floor building in Xi'an Jiatong-Liverpool University, Suzhou, China. We also provide preliminary results of localization and trajectory estimation based on convolutional neural network (CNN) and long short-term memory (LSTM) network with this database. For localization, we map RSS data for a reference point to an image-like, two-dimensional array and then apply CNN which is popular in image and video analysis and recognition. For trajectory estimation, we use a modified random way point model to efficiently generate continuous step traces imitating human walking and train a stacked two-layer LSTM network with the generated data to remember the changing pattern of geomagnetic field intensity against (x,y) coordinates. Experimental results demonstrate the usefulness of our new database and the feasibility of the CNN and LSTM-based localization and trajectory estimation with the database.