 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial-JEPA: Emergent Geometric Isomorphism
Feb 28, 2026World models compress rich sensory streams into compact latent codes that anticipate future observations. We let separate agents acquire such models from distinct viewpoints of the same environment without any parameter sharing or coordination. After training, their internal representations exhibit a striking emergent property: the two latent spaces are related by an approximate linear isometry, enabling transparent translation between them. This geometric consensus survives large viewpoint shifts and scant overlap in raw pixels. Leveraging the learned alignment, a classifier trained on one agent can be ported to the other with no additional gradient steps, while distillation-like migration accelerates later learning and markedly reduces total compute. The findings reveal that predictive learning objectives impose strong regularities on representation geometry, suggesting a lightweight path to interoperability among decentralized vision systems. The code is available at https://anonymous.4open.science/r/Social-JEPA-5C57.
Zenith: Scaling up Ranking Models for Billion-scale Livestreaming Recommendation
Jan 29, 2026Accurately capturing feature interactions is essential in recommender systems, and recent trends show that scaling up model capacity could be a key driver for next-level predictive performance. While prior work has explored various model architectures to capture multi-granularity feature interactions, relatively little attention has been paid to efficient feature handling and scaling model capacity without incurring excessive inference latency. In this paper, we address this by presenting Zenith, a scalable and efficient ranking architecture that learns complex feature interactions with minimal runtime overhead. Zenith is designed to handle a few high-dimensional Prime Tokens with Token Fusion and Token Boost modules, which exhibits superior scaling laws compared to other state-of-the-art ranking methods, thanks to its improved token heterogeneity. Its real-world effectiveness is demonstrated by deploying the architecture to TikTok Live, a leading online livestreaming platform that attracts billions of users globally. Our A/B test shows that Zenith achieves +1.05%/-1.10% in online CTR AUC and Logloss, and realizes +9.93% gains in Quality Watch Session / User and +8.11% in Quality Watch Duration / User.
SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
Dec 16, 2025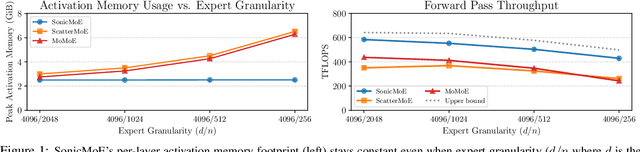
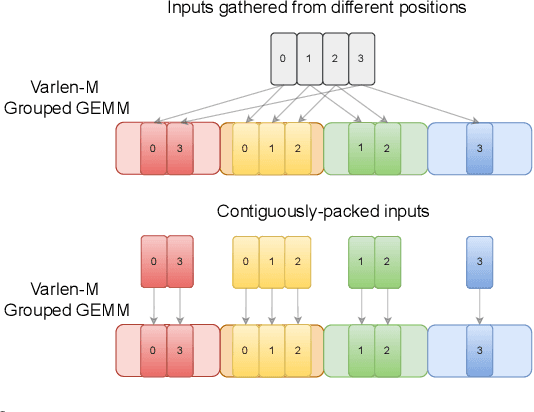
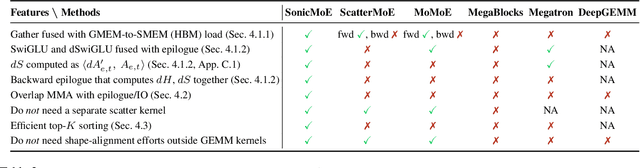
Mixture of Experts (MoE) models have emerged as the de facto architecture for scaling up language models without significantly increasing the computational cost. Recent MoE models demonstrate a clear trend towards high expert granularity (smaller expert intermediate dimension) and higher sparsity (constant number of activated experts with higher number of total experts), which improve model quality per FLOP. However, fine-grained MoEs suffer from increased activation memory footprint and reduced hardware efficiency due to higher IO costs, while sparser MoEs suffer from wasted computations due to padding in Grouped GEMM kernels. In response, we propose a memory-efficient algorithm to compute the forward and backward passes of MoEs with minimal activation caching for the backward pass. We also design GPU kernels that overlap memory IO with computation benefiting all MoE architectures. Finally, we propose a novel "token rounding" method that minimizes the wasted compute due to padding in Grouped GEMM kernels. As a result, our method SonicMoE reduces activation memory by 45% and achieves a 1.86x compute throughput improvement on Hopper GPUs compared to ScatterMoE's BF16 MoE kernel for a fine-grained 7B MoE. Concretely, SonicMoE on 64 H100s achieves a training throughput of 213 billion tokens per day comparable to ScatterMoE's 225 billion tokens per day on 96 H100s for a 7B MoE model training with FSDP-2 using the lm-engine codebase. Under high MoE sparsity settings, our tile-aware token rounding algorithm yields an additional 1.16x speedup on kernel execution time compared to vanilla top-$K$ routing while maintaining similar downstream performance. We open-source all our kernels to enable faster MoE model training.
SCAL for Pinch-Lifting: Complementary Rotational and Linear Prototypes for Environment-Adaptive Grasping
Oct 26, 2025This paper presents environment-adaptive pinch-lifting built on a slot-constrained adaptive linkage (SCAL) and instantiated in two complementary fingers: SCAL-R, a rotational-drive design with an active fingertip that folds inward after contact to form an envelope, and SCAL-L, a linear-drive design that passively opens on contact to span wide or weak-feature objects. Both fingers convert surface following into an upward lifting branch while maintaining fingertip orientation, enabling thin or low-profile targets to be raised from supports with minimal sensing and control. Two-finger grippers are fabricated via PLA-based 3D printing. Experiments evaluate (i) contact-preserving sliding and pinch-lifting on tabletops, (ii) ramp negotiation followed by lift, and (iii) handling of bulky objects via active enveloping (SCAL-R) or contact-triggered passive opening (SCAL-L). Across dozens of trials on small parts, boxes, jars, and tape rolls, both designs achieve consistent grasps with limited tuning. A quasi-static analysis provides closed-form fingertip-force models for linear parallel pinching and two-point enveloping, offering geometry-aware guidance for design and operation. Overall, the results indicate complementary operating regimes and a practical path to robust, environment-adaptive grasping with simple actuation.
PolyConf: Unlocking Polymer Conformation Generation through Hierarchical Generative Models
Apr 11, 2025Polymer conformation generation is a critical task that enables atomic-level studies of diverse polymer materials. While significant advances have been made in designing various conformation generation methods for small molecules and proteins, these methods struggle to generate polymer conformations due to polymers' unique structural characteristics. The scarcity of polymer conformation datasets further limits progress, making this promising area largely unexplored. In this work, we propose PolyConf, a pioneering tailored polymer conformation generation method that leverages hierarchical generative models to unlock new possibilities for this task. Specifically, we decompose the polymer conformation into a series of local conformations (i.e., the conformations of its repeating units), generating these local conformations through an autoregressive model. We then generate corresponding orientation transformations via a diffusion model to assemble these local conformations into the complete polymer conformation. Moreover, we develop the first benchmark with a high-quality polymer conformation dataset derived from molecular dynamics simulations to boost related research in this area. The comprehensive evaluation demonstrates that PolyConf consistently generates high-quality polymer conformations, facilitating advancements in polymer modeling and simulation.
Sensitivity Meets Sparsity: The Impact of Extremely Sparse Parameter Patterns on Theory-of-Mind of Large Language Models
Apr 05, 2025



This paper investigates the emergence of Theory-of-Mind (ToM) capabilities in large language models (LLMs) from a mechanistic perspective, focusing on the role of extremely sparse parameter patterns. We introduce a novel method to identify ToM-sensitive parameters and reveal that perturbing as little as 0.001% of these parameters significantly degrades ToM performance while also impairing contextual localization and language understanding. To understand this effect, we analyze their interaction with core architectural components of LLMs. Our findings demonstrate that these sensitive parameters are closely linked to the positional encoding module, particularly in models using Rotary Position Embedding (RoPE), where perturbations disrupt dominant-frequency activations critical for contextual processing. Furthermore, we show that perturbing ToM-sensitive parameters affects LLM's attention mechanism by modulating the angle between queries and keys under positional encoding. These insights provide a deeper understanding of how LLMs acquire social reasoning abilities, bridging AI interpretability with cognitive science. Our results have implications for enhancing model alignment, mitigating biases, and improving AI systems designed for human interaction.
A high-accuracy multi-model mixing retrosynthetic method
Sep 06, 2024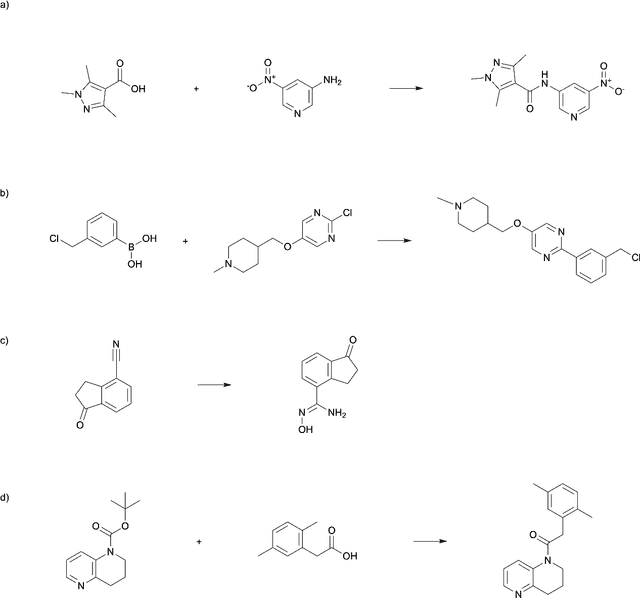
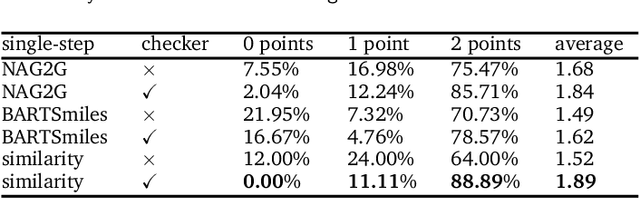
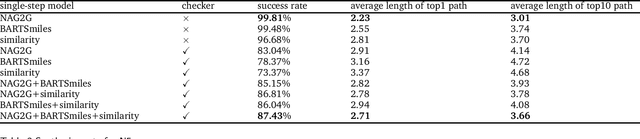
The field of computer-aided synthesis planning (CASP) has seen rapid advancements in recent years, achieving significant progress across various algorithmic benchmarks. However, chemists often encounter numerous infeasible reactions when using CASP in practice. This article delves into common errors associated with CASP and introduces a product prediction model aimed at enhancing the accuracy of single-step models. While the product prediction model reduces the number of single-step reactions, it integrates multiple single-step models to maintain the overall reaction count and increase reaction diversity. Based on manual analysis and large-scale testing, the product prediction model, combined with the multi-model ensemble approach, has been proven to offer higher feasibility and greater diversity.
A WT-ResNet based fault diagnosis model for the urban rail train transmission system
Jun 10, 2024



This study presents a novel fault diagnosis model for urban rail transit systems based on Wavelet Transform Residual Neural Network (WT-ResNet). The model integrates the advantages of wavelet transform for feature extraction and ResNet for pattern recognition, offering enhanced diagnostic accuracy and robustness. Experimental results demonstrate the effectiveness of the proposed model in identifying faults in urban rail trains, paving the way for improved maintenance strategies and reduced downtime.
Predicting Polymer Properties Based on Multimodal Multitask Pretraining
Jun 07, 2024In the past few decades, polymers, high-molecular-weight compounds formed by bonding numerous identical or similar monomers covalently, have played an essential role in various scientific fields. In this context, accurate prediction of their properties is becoming increasingly crucial. Typically, the properties of a polymer, such as plasticity, conductivity, bio-compatibility, and so on, are highly correlated with its 3D structure. However, current methods for predicting polymer properties heavily rely on information from polymer SMILES sequences (P-SMILES strings) while ignoring crucial 3D structural information, leading to sub-optimal performance. In this work, we propose MMPolymer, a novel multimodal multitask pretraining framework incorporating both polymer 1D sequential information and 3D structural information to enhance downstream polymer property prediction tasks. Besides, to overcome the limited availability of polymer 3D data, we further propose the "Star Substitution" strategy to extract 3D structural information effectively. During pretraining, MMPolymer not only predicts masked tokens and recovers 3D coordinates but also achieves the cross-modal alignment of latent representation. Subsequently, we further fine-tune the pretrained MMPolymer for downstream polymer property prediction tasks in the supervised learning paradigm. Experimental results demonstrate that MMPolymer achieves state-of-the-art performance in various polymer property prediction tasks. Moreover, leveraging the pretrained MMPolymer and using only one modality (either P-SMILES string or 3D conformation) during fine-tuning can also surpass existing polymer property prediction methods, highlighting the exceptional capability of MMPolymer in polymer feature extraction and utilization. Our online platform for polymer property prediction is available at https://app.bohrium.dp.tech/mmpolymer.
Zeroth-Order Fine-Tuning of LLMs with Extreme Sparsity
Jun 05, 2024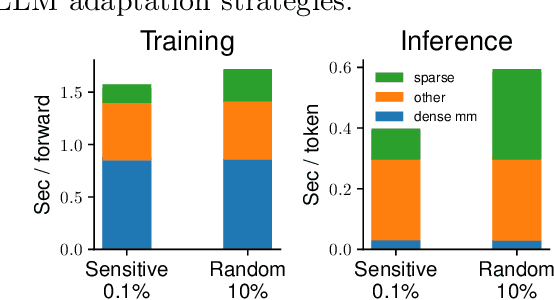
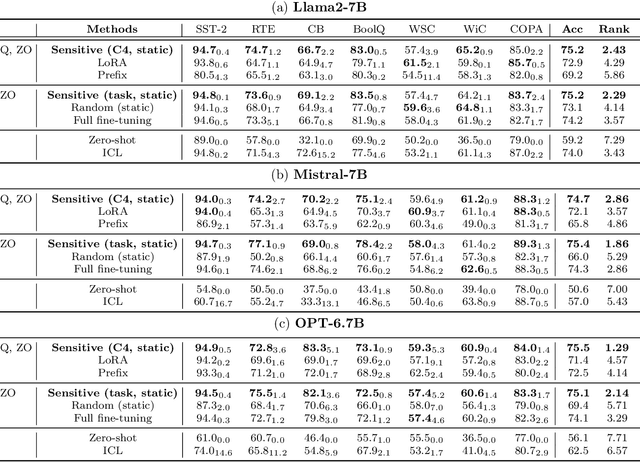
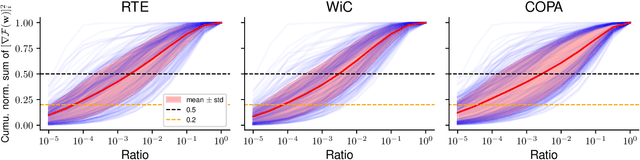
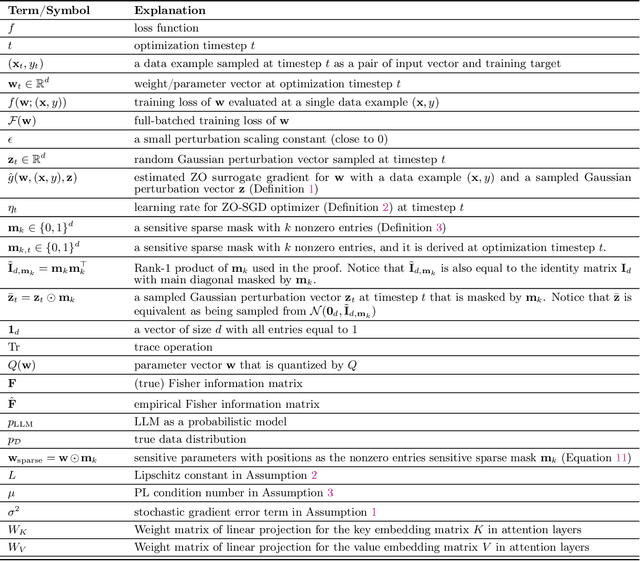
Zeroth-order optimization (ZO) is a memory-efficient strategy for fine-tuning Large Language Models using only forward passes. However, the application of ZO fine-tuning in memory-constrained settings such as mobile phones and laptops is still challenging since full precision forward passes are infeasible. In this study, we address this limitation by integrating sparsity and quantization into ZO fine-tuning of LLMs. Specifically, we investigate the feasibility of fine-tuning an extremely small subset of LLM parameters using ZO. This approach allows the majority of un-tuned parameters to be quantized to accommodate the constraint of limited device memory. Our findings reveal that the pre-training process can identify a set of "sensitive parameters" that can guide the ZO fine-tuning of LLMs on downstream tasks. Our results demonstrate that fine-tuning 0.1% sensitive parameters in the LLM with ZO can outperform the full ZO fine-tuning performance, while offering wall-clock time speedup. Additionally, we show that ZO fine-tuning targeting these 0.1% sensitive parameters, combined with 4 bit quantization, enables efficient ZO fine-tuning of an Llama2-7B model on a GPU device with less than 8 GiB of memory and notably reduced latency.