 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovieRecapsQA: A Multimodal Open-Ended Video Question-Answering Benchmark
Jan 05, 2026Understanding real-world videos such as movies requires integrating visual and dialogue cues to answer complex questions. Yet existing VideoQA benchmarks struggle to capture this multimodal reasoning and are largely not open-ended, given the difficulty of evaluating free-form answers. In this paper, we introduce a novel open-ended multi-modal VideoQA benchmark, MovieRecapsQA created using movie recap videos--a distinctive type of YouTube content that summarizes a film by presenting its key events through synchronized visual (recap video) and textual (recap summary) modalities. Using the recap summary, we generate $\approx 8.2$ K question-answer (QA) pairs (aligned with movie-subtitles) and provide the necessary "facts" needed to verify an answer in a reference-free manner. To our knowledge, this is the first open-ended VideoQA benchmark that supplies explicit textual context of the input (video and/or text); which we use for evaluation. Our benchmark provides videos of multiple lengths (i.e., recap-segments, movie-segments) and categorizations of questions (by modality and type) to enable fine-grained analysis. We evaluate the performance of seven state-of-the-art MLLMs using our benchmark and observe that: 1) visual-only questions remain the most challenging; 2) models default to textual inputs whenever available; 3) extracting factually accurate information from video content is still difficult for all models; and 4) proprietary and open-source models perform comparably on video-dependent questions.
Ranking with Slot Constraints
Oct 27, 2023We introduce the problem of ranking with slot constraints, which can be used to model a wide range of application problems -- from college admission with limited slots for different majors, to composing a stratified cohort of eligible participants in a medical trial. We show that the conventional Probability Ranking Principle (PRP) can be highly sub-optimal for slot-constrained ranking problems, and we devise a new ranking algorithm, called MatchRank. The goal of MatchRank is to produce rankings that maximize the number of filled slots if candidates are evaluated by a human decision maker in the order of the ranking. In this way, MatchRank generalizes the PRP, and it subsumes the PRP as a special case when there are no slot constraints. Our theoretical analysis shows that MatchRank has a strong approximation guarantee without any independence assumptions between slots or candidates. Furthermore, we show how MatchRank can be implemented efficiently. Beyond the theoretical guarantees, empirical evaluations show that MatchRank can provide substantial improvements over a range of synthetic and real-world tasks.
Augmenting Holistic Review in University Admission using Natural Language Processing for Essays and Recommendation Letters
Jun 30, 2023


University admission at many highly selective institutions uses a holistic review process, where all aspects of the application, including protected attributes (e.g., race, gender), grades, essays, and recommendation letters are considered, to compose an excellent and diverse class. In this study, we empirically evaluate how influential protected attributes are for predicting admission decisions using a machine learning (ML) model, and in how far textual information (e.g., personal essay, teacher recommendation) may substitute for the loss of protected attributes in the model. Using data from 14,915 applicants to an undergraduate admission office at a selective U.S. institution in the 2022-2023 cycle, we find that the exclusion of protected attributes from the ML model leads to substantially reduced admission-prediction performance. The inclusion of textual information via both a TF-IDF representation and a Latent Dirichlet allocation (LDA) model partially restores model performance, but does not appear to provide a full substitute for admitting a similarly diverse class. In particular, while the text helps with gender diversity, the proportion of URM applicants is severely impacted by the exclusion of protected attributes, and the inclusion of new attributes generated from the textual information does not recover this performance loss.
Comparing Human and Machine Bias in Face Recognition
Oct 25, 2021
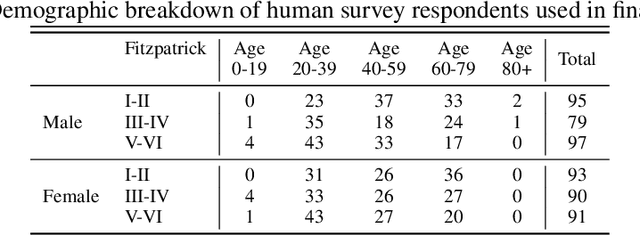

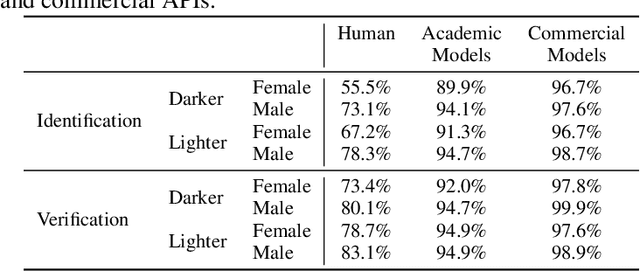
Much recent research has uncovered and discussed serious concerns of bias in facial analysis technologies, finding performance disparities between groups of people based on perceived gender, skin type, lighting condition, etc. These audits are immensely important and successful at measuring algorithmic bias but have two major challenges: the audits (1) use facial recognition datasets which lack quality metadata, like LFW and CelebA, and (2) do not compare their observed algorithmic bias to the biases of their human alternatives. In this paper, we release improvements to the LFW and CelebA datasets which will enable future researchers to obtain measurements of algorithmic bias that are not tainted by major flaws in the dataset (e.g. identical images appearing in both the gallery and test set). We also use these new data to develop a series of challenging facial identification and verification questions that we administered to various algorithms and a large, balanced sample of human reviewers. We find that both computer models and human survey participants perform significantly better at the verification task, generally obtain lower accuracy rates on dark-skinned or female subjects for both tasks, and obtain higher accuracy rates when their demographics match that of the question. Computer models are observed to achieve a higher level of accuracy than the survey participants on both tasks and exhibit bias to similar degrees as the human survey participants.