 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradual Fine-Tuning for Flow Matching Models
Jan 30, 2026Fine-tuning flow matching models is a central challenge in settings with limited data, evolving distributions, or strict efficiency demands, where unconstrained fine-tuning can erode the accuracy and efficiency gains learned during pretraining. Prior work has produced theoretical guarantees and empirical advances for reward-based fine-tuning formulations, but these methods often impose restrictions on permissible drift structure or training techniques. In this work, we propose Gradual Fine-Tuning (GFT), a principled framework for fine-tuning flow-based generative models when samples from the target distribution are available. For stochastic flows, GFT defines a temperature-controlled sequence of intermediate objectives that smoothly interpolate between the pretrained and target drifts, approaching the true target as the temperature approaches zero. We prove convergence results for both marginal and conditional GFT objectives, enabling the use of suitable (e.g., optimal transport) couplings during GFT while preserving correctness. Empirically, GFT improves convergence stability and shortens probability paths, resulting in faster inference, while maintaining generation quality comparable to standard fine-tuning. Our results position GFT as a theoretically grounded and practically effective alternative for scalable adaptation of flow matching models under distribution shift.
Comparing Human and Machine Bias in Face Recognition
Oct 25, 2021
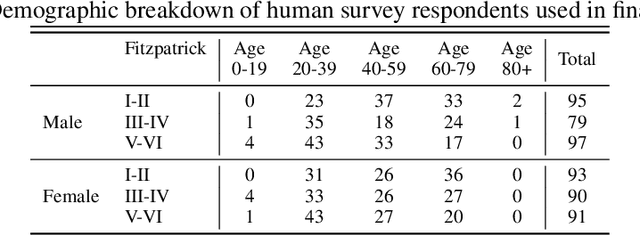

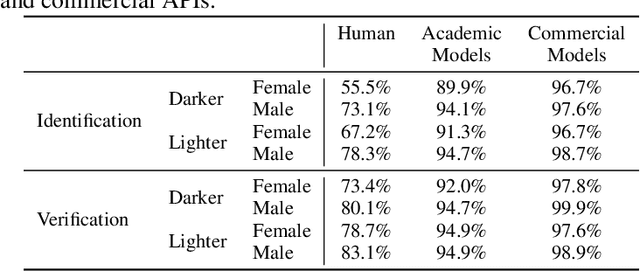
Much recent research has uncovered and discussed serious concerns of bias in facial analysis technologies, finding performance disparities between groups of people based on perceived gender, skin type, lighting condition, etc. These audits are immensely important and successful at measuring algorithmic bias but have two major challenges: the audits (1) use facial recognition datasets which lack quality metadata, like LFW and CelebA, and (2) do not compare their observed algorithmic bias to the biases of their human alternatives. In this paper, we release improvements to the LFW and CelebA datasets which will enable future researchers to obtain measurements of algorithmic bias that are not tainted by major flaws in the dataset (e.g. identical images appearing in both the gallery and test set). We also use these new data to develop a series of challenging facial identification and verification questions that we administered to various algorithms and a large, balanced sample of human reviewers. We find that both computer models and human survey participants perform significantly better at the verification task, generally obtain lower accuracy rates on dark-skinned or female subjects for both tasks, and obtain higher accuracy rates when their demographics match that of the question. Computer models are observed to achieve a higher level of accuracy than the survey participants on both tasks and exhibit bias to similar degrees as the human survey participants.