 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerEval: A Framework for Evaluating Steerability with Natural Language Profiles for Recommendation
Jan 28, 2026Natural-language user profiles have recently attracted attention not only for improved interpretability, but also for their potential to make recommender systems more steerable. By enabling direct editing, natural-language profiles allow users to explicitly articulate preferences that may be difficult to infer from past behavior. However, it remains unclear whether current natural-language-based recommendation methods can follow such steering commands. While existing steerability evaluations have shown some success for well-recognized item attributes (e.g., movie genres), we argue that these benchmarks fail to capture the richer forms of user control that motivate steerable recommendations. To address this gap, we introduce SteerEval, an evaluation framework designed to measure more nuanced and diverse forms of steerability by using interventions that range from genres to content-warning for movies. We assess the steerability of a family of pretrained natural-language recommenders, examine the potential and limitations of steering on relatively niche topics, and compare how different profile and recommendation interventions impact steering effectiveness. Finally, we offer practical design suggestions informed by our findings and discuss future steps in steerable recommender design.
End-to-end Training for Recommendation with Language-based User Profiles
Oct 24, 2024



Many online platforms maintain user profiles for personalization. Unfortunately, these profiles are typically not interpretable or easily modifiable by the user. To remedy this shortcoming, we explore natural language-based user profiles, as they promise enhanced transparency and scrutability of recommender systems. While existing work has shown that language-based profiles from standard LLMs can be effective, such generalist LLMs are unlikely to be optimal for this task. In this paper, we introduce LangPTune, the first end-to-end learning method for training LLMs to produce language-based user profiles that optimize recommendation effectiveness. Through comprehensive evaluations of LangPTune across various training configurations and benchmarks, we demonstrate that our approach significantly outperforms existing profile-based methods. In addition, it approaches performance levels comparable to state-of-the-art, less transparent recommender systems, providing a robust and interpretable alternative to conventional systems. Finally, we validate the relative interpretability of these language-based user profiles through user studies involving crowdworkers and GPT-4-based evaluations. Implementation of LangPTune can be found at https://github.com/ZhaolinGao/LangPTune.
Language-Based User Profiles for Recommendation
Feb 23, 2024



Most conventional recommendation methods (e.g., matrix factorization) represent user profiles as high-dimensional vectors. Unfortunately, these vectors lack interpretability and steerability, and often perform poorly in cold-start settings. To address these shortcomings, we explore the use of user profiles that are represented as human-readable text. We propose the Language-based Factorization Model (LFM), which is essentially an encoder/decoder model where both the encoder and the decoder are large language models (LLMs). The encoder LLM generates a compact natural-language profile of the user's interests from the user's rating history. The decoder LLM uses this summary profile to complete predictive downstream tasks. We evaluate our LFM approach on the MovieLens dataset, comparing it against matrix factorization and an LLM model that directly predicts from the user's rating history. In cold-start settings, we find that our method can have higher accuracy than matrix factorization. Furthermore, we find that generating a compact and human-readable summary often performs comparably with or better than direct LLM prediction, while enjoying better interpretability and shorter model input length. Our results motivate a number of future research directions and potential improvements.
GPT as a Baseline for Recommendation Explanation Texts
Sep 16, 2023



In this work, we establish a baseline potential for how modern model-generated text explanations of movie recommendations may help users, and explore what different components of these text explanations that users like or dislike, especially in contrast to existing human movie reviews. We found that participants gave no significantly different rankings between movies, nor did they give significantly different individual quality scores to reviews of movies that they had never seen before. However, participants did mark reviews as significantly better when they were movies they had seen before. We also explore specific aspects of movie review texts that participants marked as important for each quality. Overall, we establish that modern LLMs are a promising source of recommendation explanations, and we intend on further exploring personalizable text explanations in the future.
Augmenting Holistic Review in University Admission using Natural Language Processing for Essays and Recommendation Letters
Jun 30, 2023


University admission at many highly selective institutions uses a holistic review process, where all aspects of the application, including protected attributes (e.g., race, gender), grades, essays, and recommendation letters are considered, to compose an excellent and diverse class. In this study, we empirically evaluate how influential protected attributes are for predicting admission decisions using a machine learning (ML) model, and in how far textual information (e.g., personal essay, teacher recommendation) may substitute for the loss of protected attributes in the model. Using data from 14,915 applicants to an undergraduate admission office at a selective U.S. institution in the 2022-2023 cycle, we find that the exclusion of protected attributes from the ML model leads to substantially reduced admission-prediction performance. The inclusion of textual information via both a TF-IDF representation and a Latent Dirichlet allocation (LDA) model partially restores model performance, but does not appear to provide a full substitute for admitting a similarly diverse class. In particular, while the text helps with gender diversity, the proportion of URM applicants is severely impacted by the exclusion of protected attributes, and the inclusion of new attributes generated from the textual information does not recover this performance loss.
An Interactive UI to Support Sensemaking over Collections of Parallel Texts
Mar 11, 2023



Scientists and science journalists, among others, often need to make sense of a large number of papers and how they compare with each other in scope, focus, findings, or any other important factors. However, with a large corpus of papers, it's cognitively demanding to pairwise compare and contrast them all with each other. Fully automating this review process would be infeasible, because it often requires domain-specific knowledge, as well as understanding what the context and motivations for the review are. While there are existing tools to help with the process of organizing and annotating papers for literature reviews, at the core they still rely on people to serially read through papers and manually make sense of relevant information. We present AVTALER, which combines peoples' unique skills, contextual awareness, and knowledge, together with the strength of automation. Given a set of comparable text excerpts from a paper corpus, it supports users in sensemaking and contrasting paper attributes by interactively aligning text excerpts in a table so that comparable details are presented in a shared column. AVTALER is based on a core alignment algorithm that makes use of modern NLP tools. Furthermore, AVTALER is a mixed-initiative system: users can interactively give the system constraints which are integrated into the alignment construction process.
Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance
Jun 30, 2020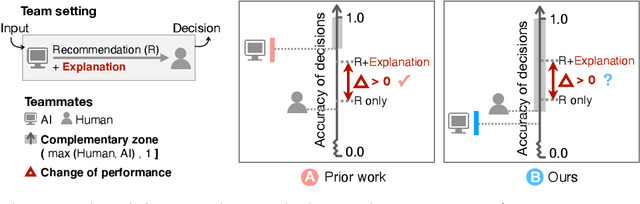
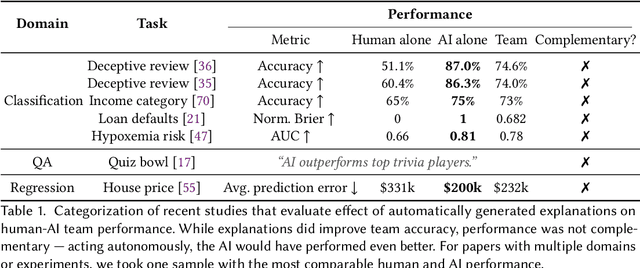
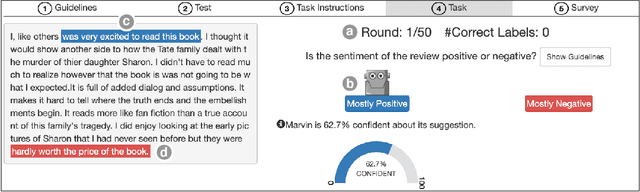
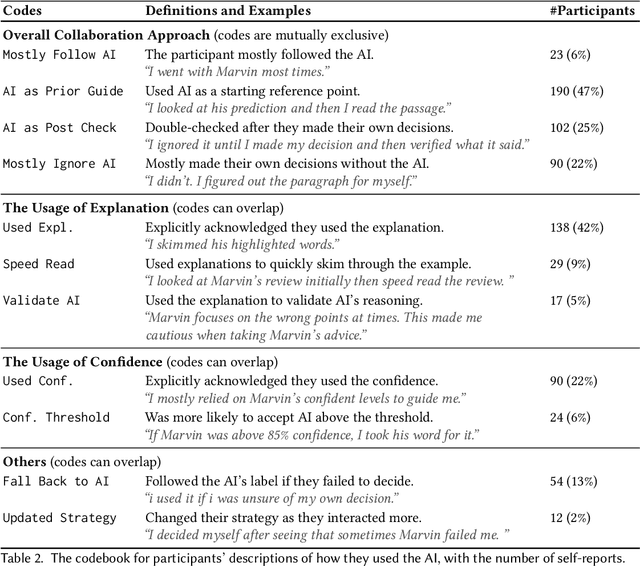
Increasingly, organizations are pairing humans with AI systems to improve decision-making and reducing costs. Proponents of human-centered AI argue that team performance can even further improve when the AI model explains its recommendations. However, a careful analysis of existing literature reveals that prior studies observed improvements due to explanations only when the AI, alone, outperformed both the human and the best human-AI team. This raises an important question: can explanations lead to complementary performance, i.e., with accuracy higher than both the human and the AI working alone? We address this question by devising comprehensive studies on human-AI teaming, where participants solve a task with help from an AI system without explanations and from one with varying types of AI explanation support. We carefully controlled to ensure comparable human and AI accuracy across experiments on three NLP datasets (two for sentiment analysis and one for question answering). While we found complementary improvements from AI augmentation, they were not increased by state-of-the-art explanations compared to simpler strategies, such as displaying the AI's confidence. We show that explanations increase the chance that humans will accept the AI's recommendation regardless of whether the AI is correct. While this clarifies the gains in team performance from explanations in prior work, it poses new challenges for human-centered AI: how can we best design systems to produce complementary performance? Can we develop explanatory approaches that help humans decide whether and when to trust AI input?