 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Data Generation: Finding and Fixing Model Weaknesses
May 28, 2023
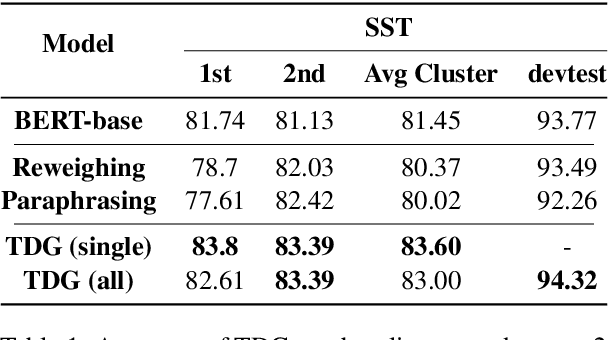


Even when aggregate accuracy is high, state-of-the-art NLP models often fail systematically on specific subgroups of data, resulting in unfair outcomes and eroding user trust. Additional data collection may not help in addressing these weaknesses, as such challenging subgroups may be unknown to users, and underrepresented in the existing and new data. We propose Targeted Data Generation (TDG), a framework that automatically identifies challenging subgroups, and generates new data for those subgroups using large language models (LLMs) with a human in the loop. TDG estimates the expected benefit and potential harm of data augmentation for each subgroup, and selects the ones most likely to improve within group performance without hurting overall performance. In our experiments, TDG significantly improves the accuracy on challenging subgroups for state-of-the-art sentiment analysis and natural language inference models, while also improving overall test accuracy.
Collaborative Development of NLP models
May 24, 2023



Despite substantial advancements, Natural Language Processing (NLP) models often require post-training adjustments to enforce business rules, rectify undesired behavior, and align with user values. These adjustments involve operationalizing "concepts"--dictating desired model responses to certain inputs. However, it's difficult for a single entity to enumerate and define all possible concepts, indicating a need for a multi-user, collaborative model alignment framework. Moreover, the exhaustive delineation of a concept is challenging, and an improper approach can create shortcuts or interfere with original data or other concepts. To address these challenges, we introduce CoDev, a framework that enables multi-user interaction with the model, thereby mitigating individual limitations. CoDev aids users in operationalizing their concepts using Large Language Models, and relying on the principle that NLP models exhibit simpler behaviors in local regions. Our main insight is learning a \emph{local} model for each concept, and a \emph{global} model to integrate the original data with all concepts. We then steer a large language model to generate instances within concept boundaries where local and global disagree. Our experiments show CoDev is effective at helping multiple users operationalize concepts and avoid interference for a variety of scenarios, tasks, and models.
Supporting Human-AI Collaboration in Auditing LLMs with LLMs
Apr 19, 2023



Large language models are becoming increasingly pervasive and ubiquitous in society via deployment in sociotechnical systems. Yet these language models, be it for classification or generation, have been shown to be biased and behave irresponsibly, causing harm to people at scale. It is crucial to audit these language models rigorously. Existing auditing tools leverage either or both humans and AI to find failures. In this work, we draw upon literature in human-AI collaboration and sensemaking, and conduct interviews with research experts in safe and fair AI, to build upon the auditing tool: AdaTest (Ribeiro and Lundberg, 2022), which is powered by a generative large language model (LLM). Through the design process we highlight the importance of sensemaking and human-AI communication to leverage complementary strengths of humans and generative models in collaborative auditing. To evaluate the effectiveness of the augmented tool, AdaTest++, we conduct user studies with participants auditing two commercial language models: OpenAI's GPT-3 and Azure's sentiment analysis model. Qualitative analysis shows that AdaTest++ effectively leverages human strengths such as schematization, hypothesis formation and testing. Further, with our tool, participants identified a variety of failures modes, covering 26 different topics over 2 tasks, that have been shown before in formal audits and also those previously under-reported.
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Mar 27, 2023


Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT-4 is part of a new cohort of LLMs (along with ChatGPT and Google's PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4's performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
ART: Automatic multi-step reasoning and tool-use for large language models
Mar 16, 2023



Large language models (LLMs) can perform complex reasoning in few- and zero-shot settings by generating intermediate chain of thought (CoT) reasoning steps. Further, each reasoning step can rely on external tools to support computation beyond the core LLM capabilities (e.g. search/running code). Prior work on CoT prompting and tool use typically requires hand-crafting task-specific demonstrations and carefully scripted interleaving of model generations with tool use. We introduce Automatic Reasoning and Tool-use (ART), a framework that uses frozen LLMs to automatically generate intermediate reasoning steps as a program. Given a new task to solve, ART selects demonstrations of multi-step reasoning and tool use from a task library. At test time, ART seamlessly pauses generation whenever external tools are called, and integrates their output before resuming generation. ART achieves a substantial improvement over few-shot prompting and automatic CoT on unseen tasks in the BigBench and MMLU benchmarks, and matches performance of hand-crafted CoT prompts on a majority of these tasks. ART is also extensible, and makes it easy for humans to improve performance by correcting errors in task-specific programs or incorporating new tools, which we demonstrate by drastically improving performance on select tasks with minimal human intervention.
ScatterShot: Interactive In-context Example Curation for Text Transformation
Feb 14, 2023



The in-context learning capabilities of LLMs like GPT-3 allow annotators to customize an LLM to their specific tasks with a small number of examples. However, users tend to include only the most obvious patterns when crafting examples, resulting in underspecified in-context functions that fall short on unseen cases. Further, it is hard to know when "enough" examples have been included even for known patterns. In this work, we present ScatterShot, an interactive system for building high-quality demonstration sets for in-context learning. ScatterShot iteratively slices unlabeled data into task-specific patterns, samples informative inputs from underexplored or not-yet-saturated slices in an active learning manner, and helps users label more efficiently with the help of an LLM and the current example set. In simulation studies on two text perturbation scenarios, ScatterShot sampling improves the resulting few-shot functions by 4-5 percentage points over random sampling, with less variance as more examples are added. In a user study, ScatterShot greatly helps users in covering different patterns in the input space and labeling in-context examples more efficiently, resulting in better in-context learning and less user effort.
Editing Models with Task Arithmetic
Dec 08, 2022Changing how pre-trained models behave -- e.g., improving their performance on a downstream task or mitigating biases learned during pre-training -- is a common practice when developing machine learning systems. In this work, we propose a new paradigm for steering the behavior of neural networks, centered around \textit{task vectors}. A task vector specifies a direction in the weight space of a pre-trained model, such that movement in that direction improves performance on the task. We build task vectors by subtracting the weights of a pre-trained model from the weights of the same model after fine-tuning on a task. We show that these task vectors can be modified and combined together through arithmetic operations such as negation and addition, and the behavior of the resulting model is steered accordingly. Negating a task vector decreases performance on the target task, with little change in model behavior on control tasks. Moreover, adding task vectors together can improve performance on multiple tasks at once. Finally, when tasks are linked by an analogy relationship of the form ``A is to B as C is to D", combining task vectors from three of the tasks can improve performance on the fourth, even when no data from the fourth task is used for training. Overall, our experiments with several models, modalities and tasks show that task arithmetic is a simple, efficient and effective way of editing models.
Adaptive Testing of Computer Vision Models
Dec 06, 2022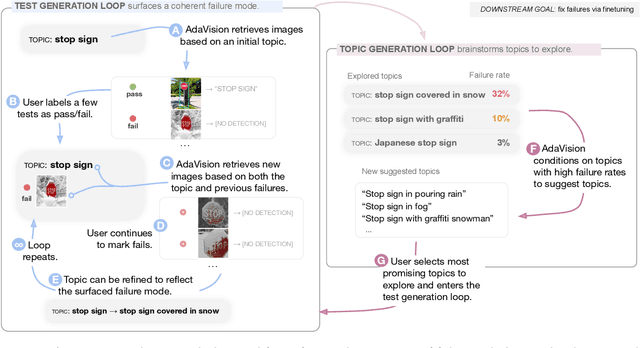
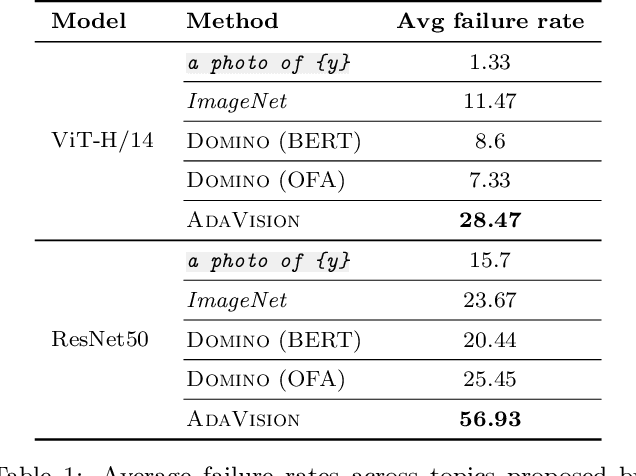
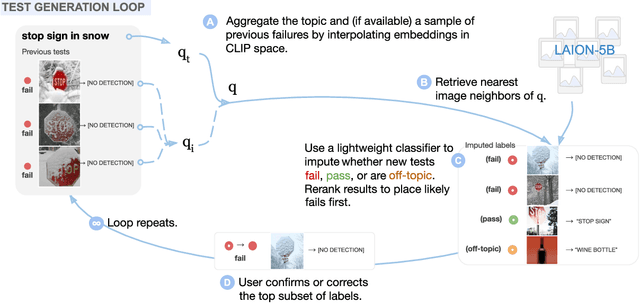

Vision models often fail systematically on groups of data that share common semantic characteristics (e.g., rare objects or unusual scenes), but identifying these failure modes is a challenge. We introduce AdaVision, an interactive process for testing vision models which helps users identify and fix coherent failure modes. Given a natural language description of a coherent group, AdaVision retrieves relevant images from LAION-5B with CLIP. The user then labels a small amount of data for model correctness, which is used in successive retrieval rounds to hill-climb towards high-error regions, refining the group definition. Once a group is saturated, AdaVision uses GPT-3 to suggest new group descriptions for the user to explore. We demonstrate the usefulness and generality of AdaVision in user studies, where users find major bugs in state-of-the-art classification, object detection, and image captioning models. These user-discovered groups have failure rates 2-3x higher than those surfaced by automatic error clustering methods. Finally, finetuning on examples found with AdaVision fixes the discovered bugs when evaluated on unseen examples, without degrading in-distribution accuracy, and while also improving performance on out-of-distribution datasets.
Fixing Model Bugs with Natural Language Patches
Nov 20, 2022



Current approaches for fixing systematic problems in NLP models (e.g. regex patches, finetuning on more data) are either brittle, or labor-intensive and liable to shortcuts. In contrast, humans often provide corrections to each other through natural language. Taking inspiration from this, we explore natural language patches -- declarative statements that allow developers to provide corrective feedback at the right level of abstraction, either overriding the model (``if a review gives 2 stars, the sentiment is negative'') or providing additional information the model may lack (``if something is described as the bomb, then it is good''). We model the task of determining if a patch applies separately from the task of integrating patch information, and show that with a small amount of synthetic data, we can teach models to effectively use real patches on real data -- 1 to 7 patches improve accuracy by ~1-4 accuracy points on different slices of a sentiment analysis dataset, and F1 by 7 points on a relation extraction dataset. Finally, we show that finetuning on as many as 100 labeled examples may be needed to match the performance of a small set of language patches.
Evaluating Systemic Error Detection Methods using Synthetic Images
Jul 08, 2022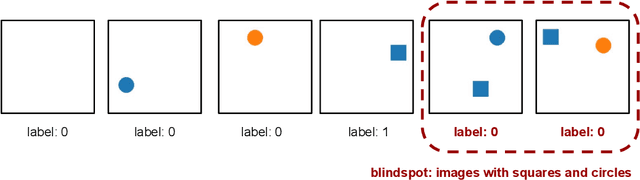
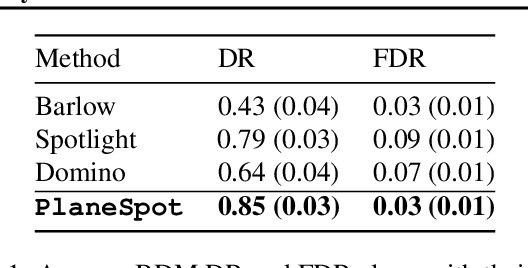
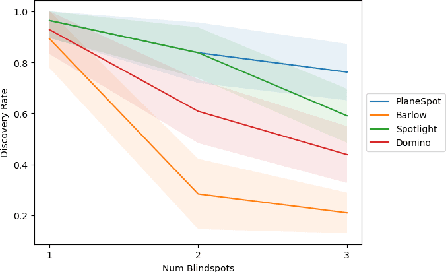

We introduce SpotCheck, a framework for generating synthetic datasets to use for evaluating methods for discovering blindspots (i.e., systemic errors) in image classifiers. We use SpotCheck to run controlled studies of how various factors influence the performance of blindspot discovery methods. Our experiments reveal several shortcomings of existing methods, such as relatively poor performance in settings with multiple blindspots and sensitivity to hyperparameters. Further, we find that a method based on dimensionality reduction, PlaneSpot, is competitive with existing methods, which has promising implications for the development of interactive tools.