 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparks of Artificial General Intelligence: Early experiments with GPT-4
Mar 27, 2023


Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT-4 is part of a new cohort of LLMs (along with ChatGPT and Google's PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4's performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
ART: Automatic multi-step reasoning and tool-use for large language models
Mar 16, 2023



Large language models (LLMs) can perform complex reasoning in few- and zero-shot settings by generating intermediate chain of thought (CoT) reasoning steps. Further, each reasoning step can rely on external tools to support computation beyond the core LLM capabilities (e.g. search/running code). Prior work on CoT prompting and tool use typically requires hand-crafting task-specific demonstrations and carefully scripted interleaving of model generations with tool use. We introduce Automatic Reasoning and Tool-use (ART), a framework that uses frozen LLMs to automatically generate intermediate reasoning steps as a program. Given a new task to solve, ART selects demonstrations of multi-step reasoning and tool use from a task library. At test time, ART seamlessly pauses generation whenever external tools are called, and integrates their output before resuming generation. ART achieves a substantial improvement over few-shot prompting and automatic CoT on unseen tasks in the BigBench and MMLU benchmarks, and matches performance of hand-crafted CoT prompts on a majority of these tasks. ART is also extensible, and makes it easy for humans to improve performance by correcting errors in task-specific programs or incorporating new tools, which we demonstrate by drastically improving performance on select tasks with minimal human intervention.
Adaptive Testing of Computer Vision Models
Dec 06, 2022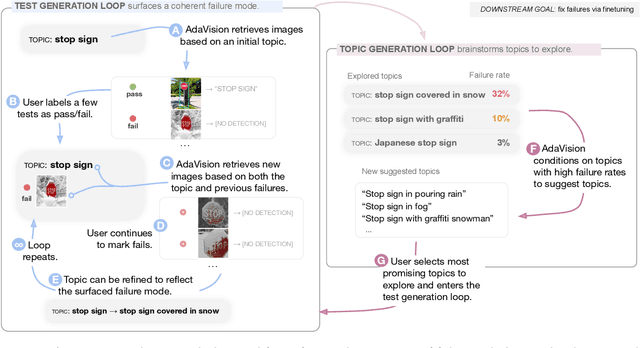
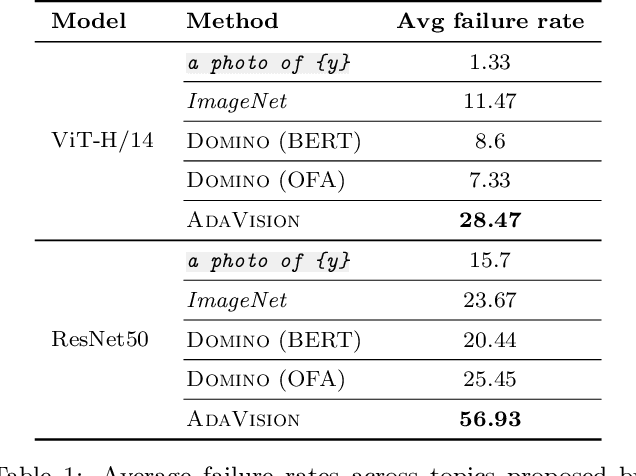
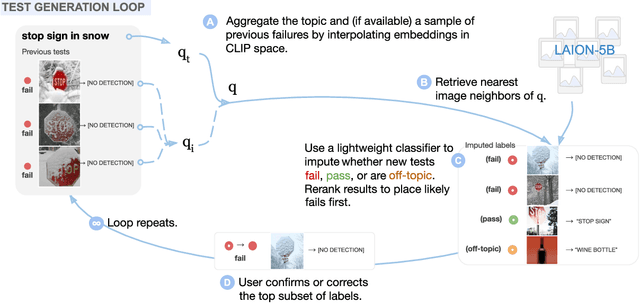

Vision models often fail systematically on groups of data that share common semantic characteristics (e.g., rare objects or unusual scenes), but identifying these failure modes is a challenge. We introduce AdaVision, an interactive process for testing vision models which helps users identify and fix coherent failure modes. Given a natural language description of a coherent group, AdaVision retrieves relevant images from LAION-5B with CLIP. The user then labels a small amount of data for model correctness, which is used in successive retrieval rounds to hill-climb towards high-error regions, refining the group definition. Once a group is saturated, AdaVision uses GPT-3 to suggest new group descriptions for the user to explore. We demonstrate the usefulness and generality of AdaVision in user studies, where users find major bugs in state-of-the-art classification, object detection, and image captioning models. These user-discovered groups have failure rates 2-3x higher than those surfaced by automatic error clustering methods. Finally, finetuning on examples found with AdaVision fixes the discovered bugs when evaluated on unseen examples, without degrading in-distribution accuracy, and while also improving performance on out-of-distribution datasets.
Fixing Model Bugs with Natural Language Patches
Nov 20, 2022



Current approaches for fixing systematic problems in NLP models (e.g. regex patches, finetuning on more data) are either brittle, or labor-intensive and liable to shortcuts. In contrast, humans often provide corrections to each other through natural language. Taking inspiration from this, we explore natural language patches -- declarative statements that allow developers to provide corrective feedback at the right level of abstraction, either overriding the model (``if a review gives 2 stars, the sentiment is negative'') or providing additional information the model may lack (``if something is described as the bomb, then it is good''). We model the task of determining if a patch applies separately from the task of integrating patch information, and show that with a small amount of synthetic data, we can teach models to effectively use real patches on real data -- 1 to 7 patches improve accuracy by ~1-4 accuracy points on different slices of a sentiment analysis dataset, and F1 by 7 points on a relation extraction dataset. Finally, we show that finetuning on as many as 100 labeled examples may be needed to match the performance of a small set of language patches.
Model-Agnostic Explainability for Visual Search
Feb 28, 2021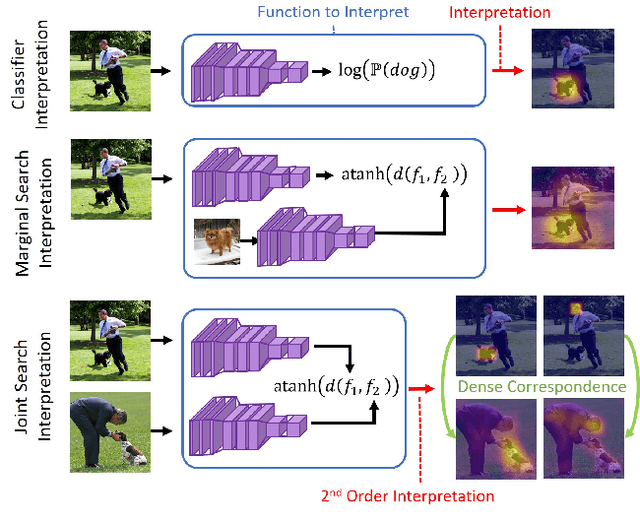


What makes two images similar? We propose new approaches to generate model-agnostic explanations for image similarity, search, and retrieval. In particular, we extend Class Activation Maps (CAMs), Additive Shapley Explanations (SHAP), and Locally Interpretable Model-Agnostic Explanations (LIME) to the domain of image retrieval and search. These approaches enable black and grey-box model introspection and can help diagnose errors and understand the rationale behind a model's similarity judgments. Furthermore, we extend these approaches to extract a full pairwise correspondence between the query and retrieved image pixels, an approach we call "joint interpretations". Formally, we show joint search interpretations arise from projecting Harsanyi dividends, and that this approach generalizes Shapley Values and The Shapley-Taylor indices. We introduce a fast kernel-based method for estimating Shapley-Taylor indices and empirically show that these game-theoretic measures yield more consistent explanations for image similarity architectures.
Explaining by Removing: A Unified Framework for Model Explanation
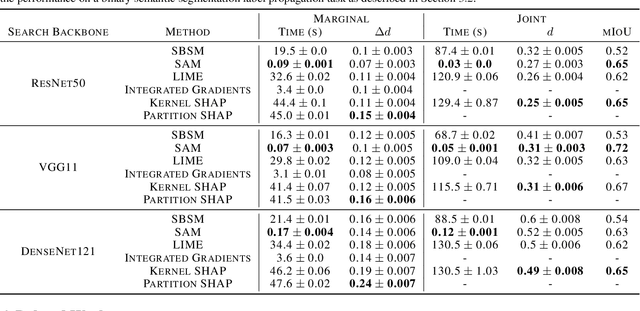
Nov 21, 2020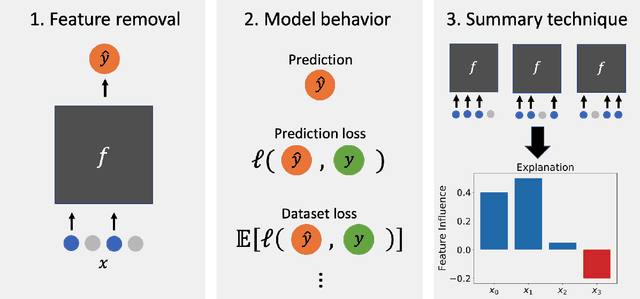
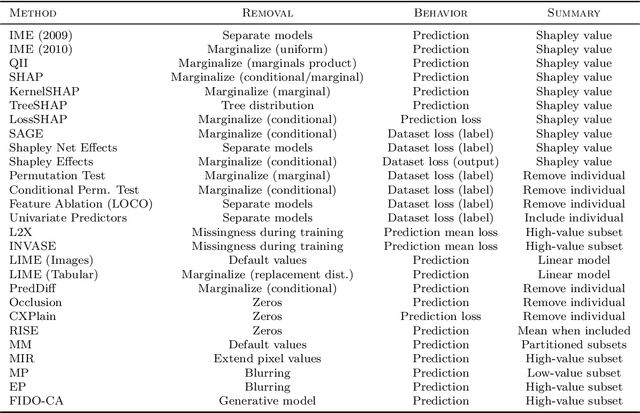
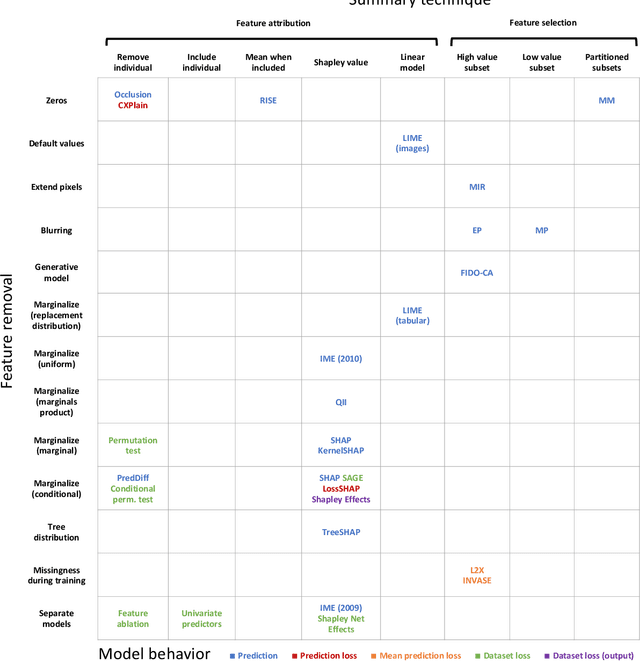

Researchers have proposed a wide variety of model explanation approaches, but it remains unclear how most methods are related or when one method is preferable to another. We establish a new class of methods, removal-based explanations, that are based on the principle of simulating feature removal to quantify each feature's influence. These methods vary in several respects, so we develop a framework that characterizes each method along three dimensions: 1) how the method removes features, 2) what model behavior the method explains, and 3) how the method summarizes each feature's influence. Our framework unifies 25 existing methods, including several of the most widely used approaches (SHAP, LIME, Meaningful Perturbations, permutation tests). This new class of explanation methods has rich connections that we examine using tools that have been largely overlooked by the explainability literature. To anchor removal-based explanations in cognitive psychology, we show that feature removal is a simple application of subtractive counterfactual reasoning. Ideas from cooperative game theory shed light on the relationships and trade-offs among different methods, and we derive conditions under which all removal-based explanations have information-theoretic interpretations. Through this analysis, we develop a unified framework that helps practitioners better understand model explanation tools, and that offers a strong theoretical foundation upon which future explainability research can build.
Shapley Flow: A Graph-based Approach to Interpreting Model Predictions
Nov 13, 2020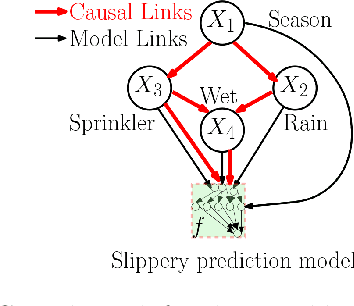
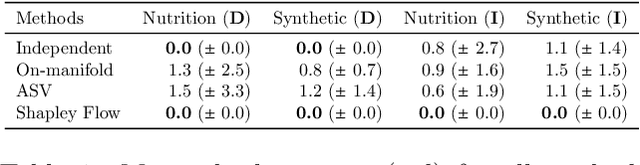
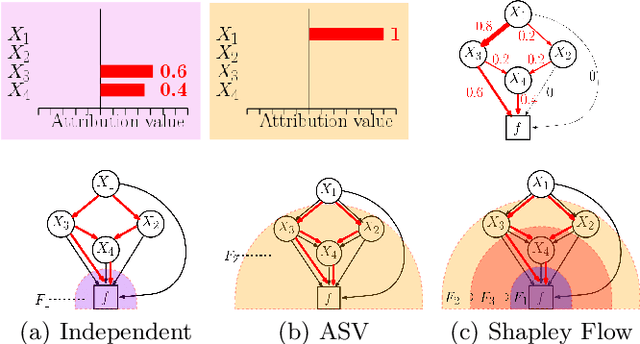
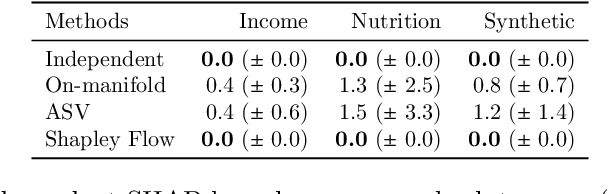
Many existing approaches for estimating feature importance are problematic because they ignore or hide dependencies among features. A causal graph, which encodes the relationships among input variables, can aid in assigning feature importance. However, current approaches that assign credit to nodes in the causal graph fail to explain the entire graph. In light of these limitations, we propose Shapley Flow, a novel approach to interpreting machine learning models. It considers the entire causal graph, and assigns credit to \textit{edges} instead of treating nodes as the fundamental unit of credit assignment. Shapley Flow is the unique solution to a generalization of the Shapley value axioms to directed acyclic graphs. We demonstrate the benefit of using Shapley Flow to reason about the impact of a model's input on its output. In addition to maintaining insights from existing approaches, Shapley Flow extends the flat, set-based, view prevalent in game theory based explanation methods to a deeper, \textit{graph-based}, view. This graph-based view enables users to understand the flow of importance through a system, and reason about potential interventions.
Feature Removal Is a Unifying Principle for Model Explanation Methods
Nov 06, 2020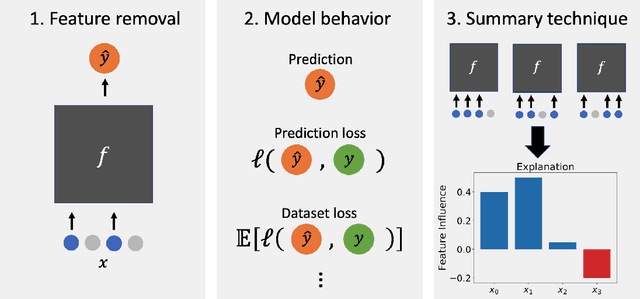
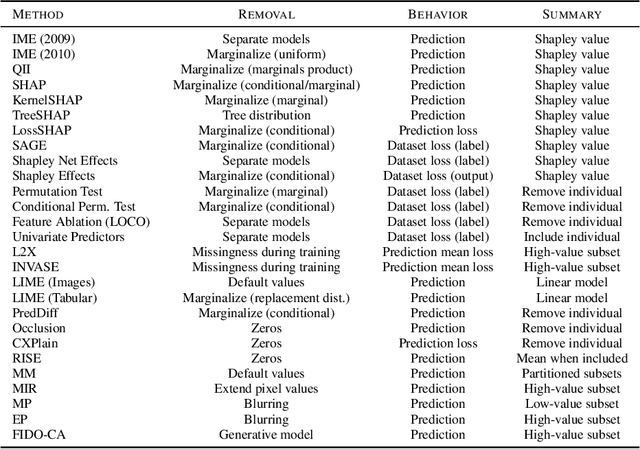
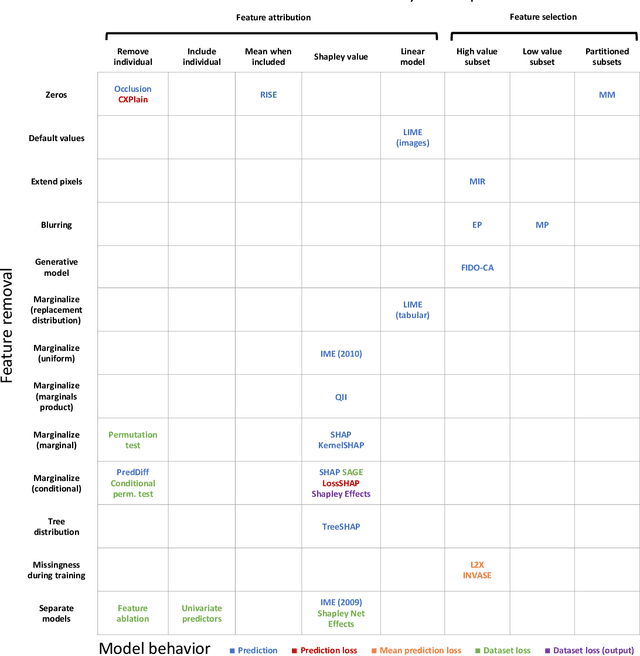
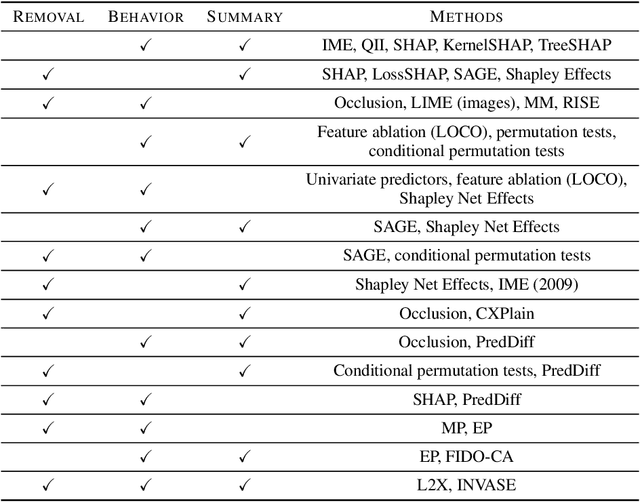
Researchers have proposed a wide variety of model explanation approaches, but it remains unclear how most methods are related or when one method is preferable to another. We examine the literature and find that many methods are based on a shared principle of explaining by removing - essentially, measuring the impact of removing sets of features from a model. These methods vary in several respects, so we develop a framework for removal-based explanations that characterizes each method along three dimensions: 1) how the method removes features, 2) what model behavior the method explains, and 3) how the method summarizes each feature's influence. Our framework unifies 25 existing methods, including several of the most widely used approaches (SHAP, LIME, Meaningful Perturbations, permutation tests). Exposing the fundamental similarities between these methods empowers users to reason about which tools to use and suggests promising directions for ongoing research in model explainability.
True to the Model or True to the Data?
Jun 29, 2020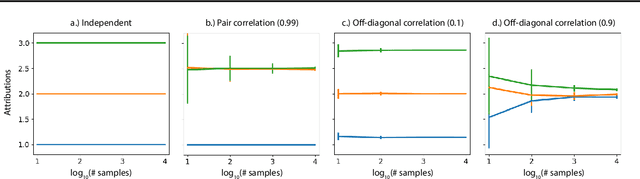
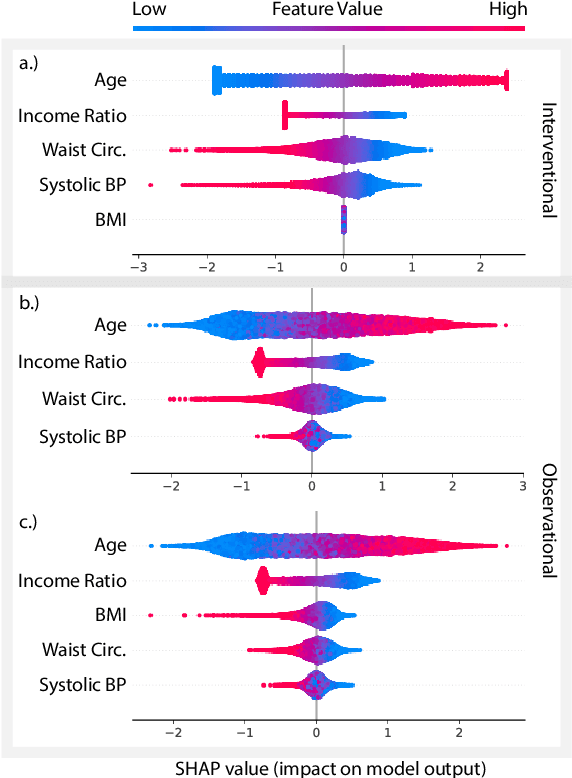
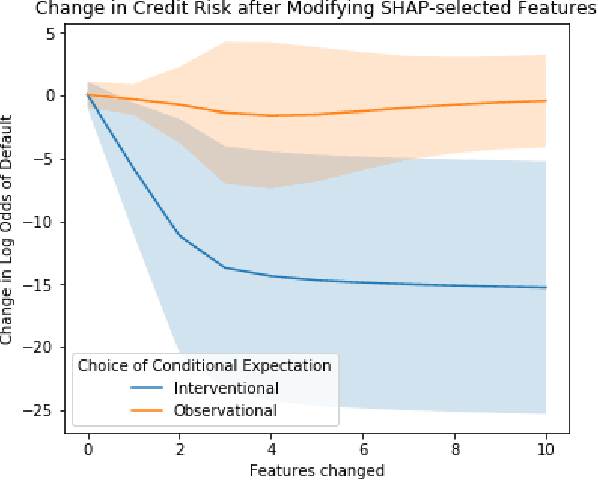
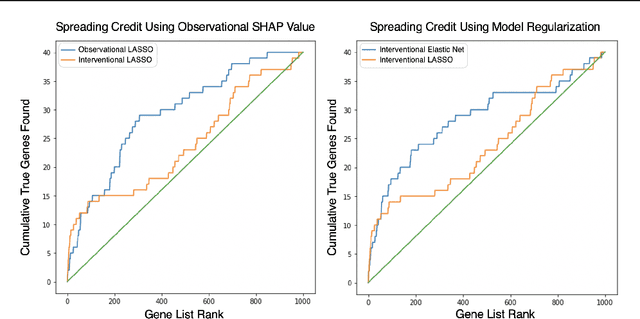
A variety of recent papers discuss the application of Shapley values, a concept for explaining coalitional games, for feature attribution in machine learning. However, the correct way to connect a machine learning model to a coalitional game has been a source of controversy. The two main approaches that have been proposed differ in the way that they condition on known features, using either (1) an interventional or (2) an observational conditional expectation. While previous work has argued that one of the two approaches is preferable in general, we argue that the choice is application dependent. Furthermore, we argue that the choice comes down to whether it is desirable to be true to the model or true to the data. We use linear models to investigate this choice. After deriving an efficient method for calculating observational conditional expectation Shapley values for linear models, we investigate how correlation in simulated data impacts the convergence of observational conditional expectation Shapley values. Finally, we present two real data examples that we consider to be representative of possible use cases for feature attribution -- (1) credit risk modeling and (2) biological discovery. We show how a different choice of value function performs better in each scenario, and how possible attributions are impacted by modeling choices.
Understanding Global Feature Contributions Through Additive Importance Measures
Apr 01, 2020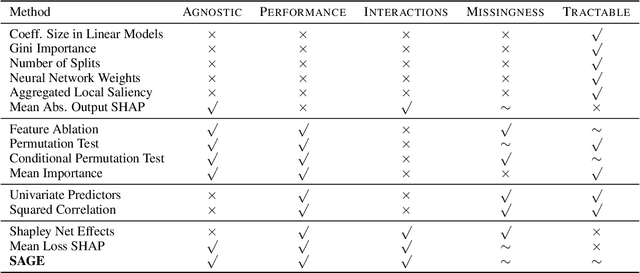
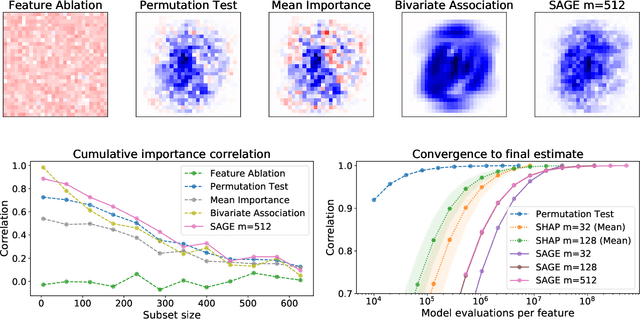


Understanding the inner workings of complex machine learning models is a long-standing problem, with recent research focusing primarily on local interpretability. To assess the role of individual input features in a global sense, we propose a new feature importance method, Shapley Additive Global importancE (SAGE), a model-agnostic measure of feature importance based on the predictive power associated with each feature. SAGE relates to prior work through the novel framework of additive importance measures, a perspective that unifies numerous other feature importance methods and shows that only SAGE properly accounts for complex feature interactions. We define SAGE using the Shapley value from cooperative game theory, which leads to numerous intuitive and desirable properties. Our experiments apply SAGE to eight datasets, including MNIST and breast cancer subtype classification, and demonstrate its advantages through quantitative and qualitative evaluations.