 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Model Performance in the Presence of an Intervention
Nov 14, 2025AI models are often evaluated based on their ability to predict the outcome of interest. However, in many AI for social impact applications, the presence of an intervention that affects the outcome can bias the evaluation. Randomized controlled trials (RCTs) randomly assign interventions, allowing data from the control group to be used for unbiased model evaluation. However, this approach is inefficient because it ignores data from the treatment group. Given the complexity and cost often associated with RCTs, making the most use of the data is essential. Thus, we investigate model evaluation strategies that leverage all data from an RCT. First, we theoretically quantify the estimation bias that arises from naïvely aggregating performance estimates from treatment and control groups and derive the condition under which this bias leads to incorrect model selection. Leveraging these theoretical insights, we propose nuisance parameter weighting (NPW), an unbiased model evaluation approach that reweights data from the treatment group to mimic the distributions of samples that would or would not experience the outcome under no intervention. Using synthetic and real-world datasets, we demonstrate that our proposed evaluation approach consistently yields better model selection than the standard approach, which ignores data from the treatment group, across various intervention effect and sample size settings. Our contribution represents a meaningful step towards more efficient model evaluation in real-world contexts.
Random Search Neural Networks for Efficient and Expressive Graph Learning
Oct 26, 2025Random walk neural networks (RWNNs) have emerged as a promising approach for graph representation learning, leveraging recent advances in sequence models to process random walks. However, under realistic sampling constraints, RWNNs often fail to capture global structure even in small graphs due to incomplete node and edge coverage, limiting their expressivity. To address this, we propose \textit{random search neural networks} (RSNNs), which operate on random searches, each of which guarantees full node coverage. Theoretically, we demonstrate that in sparse graphs, only $O(\log |V|)$ searches are needed to achieve full edge coverage, substantially reducing sampling complexity compared to the $O(|V|)$ walks required by RWNNs (assuming walk lengths scale with graph size). Furthermore, when paired with universal sequence models, RSNNs are universal approximators. We lastly show RSNNs are probabilistically invariant to graph isomorphisms, ensuring their expectation is an isomorphism-invariant graph function. Empirically, RSNNs consistently outperform RWNNs on molecular and protein benchmarks, achieving comparable or superior performance with up to 16$\times$ fewer sampled sequences. Our work bridges theoretical and practical advances in random walk based approaches, offering an efficient and expressive framework for learning on sparse graphs.
On the Limits of Selective AI Prediction: A Case Study in Clinical Decision Making
Aug 11, 2025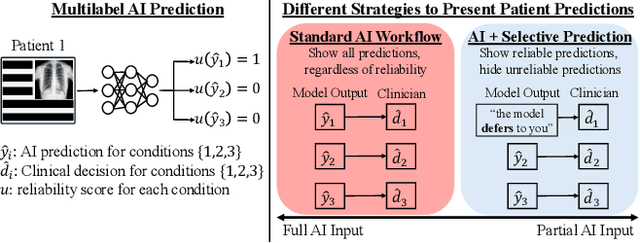
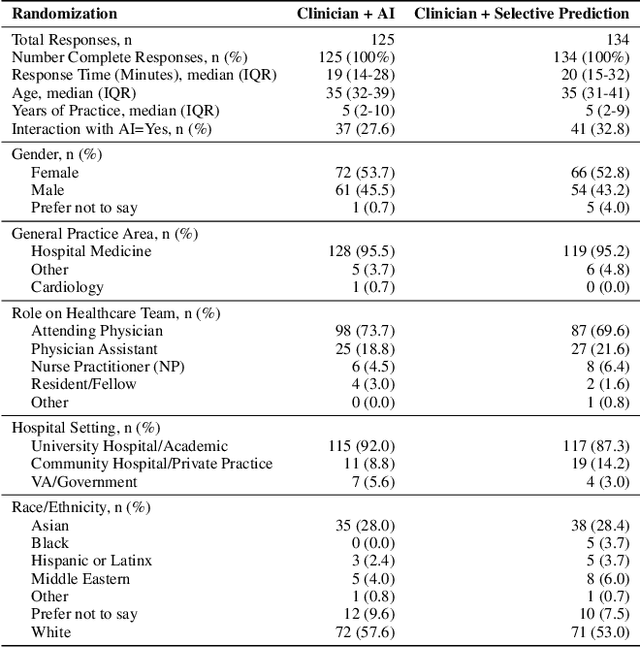
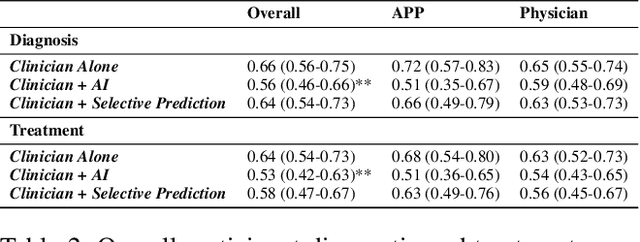
AI has the potential to augment human decision making. However, even high-performing models can produce inaccurate predictions when deployed. These inaccuracies, combined with automation bias, where humans overrely on AI predictions, can result in worse decisions. Selective prediction, in which potentially unreliable model predictions are hidden from users, has been proposed as a solution. This approach assumes that when AI abstains and informs the user so, humans make decisions as they would without AI involvement. To test this assumption, we study the effects of selective prediction on human decisions in a clinical context. We conducted a user study of 259 clinicians tasked with diagnosing and treating hospitalized patients. We compared their baseline performance without any AI involvement to their AI-assisted accuracy with and without selective prediction. Our findings indicate that selective prediction mitigates the negative effects of inaccurate AI in terms of decision accuracy. Compared to no AI assistance, clinician accuracy declined when shown inaccurate AI predictions (66% [95% CI: 56%-75%] vs. 56% [95% CI: 46%-66%]), but recovered under selective prediction (64% [95% CI: 54%-73%]). However, while selective prediction nearly maintains overall accuracy, our results suggest that it alters patterns of mistakes: when informed the AI abstains, clinicians underdiagnose (18% increase in missed diagnoses) and undertreat (35% increase in missed treatments) compared to no AI input at all. Our findings underscore the importance of empirically validating assumptions about how humans engage with AI within human-AI systems.
Estimating Misreporting in the Presence of Genuine Modification: A Causal Perspective
May 29, 2025

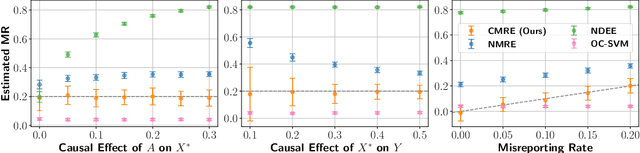
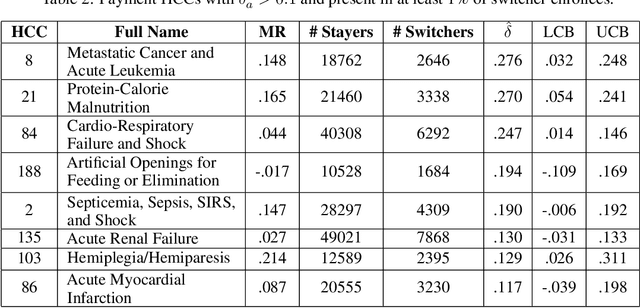
In settings where ML models are used to inform the allocation of resources, agents affected by the allocation decisions might have an incentive to strategically change their features to secure better outcomes. While prior work has studied strategic responses broadly, disentangling misreporting from genuine modification remains a fundamental challenge. In this paper, we propose a causally-motivated approach to identify and quantify how much an agent misreports on average by distinguishing deceptive changes in their features from genuine modification. Our key insight is that, unlike genuine modification, misreported features do not causally affect downstream variables (i.e., causal descendants). We exploit this asymmetry by comparing the causal effect of misreported features on their causal descendants as derived from manipulated datasets against those from unmanipulated datasets. We formally prove identifiability of the misreporting rate and characterize the variance of our estimator. We empirically validate our theoretical results using a semi-synthetic and real Medicare dataset with misreported data, demonstrating that our approach can be employed to identify misreporting in real-world scenarios.
A Course Correction in Steerability Evaluation: Revealing Miscalibration and Side Effects in LLMs
May 27, 2025


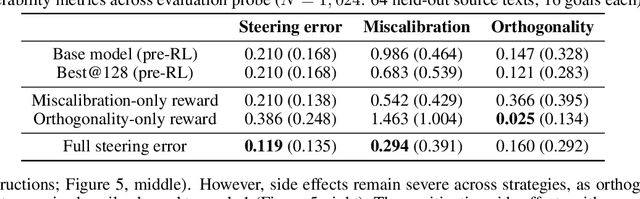
Despite advances in large language models (LLMs) on reasoning and instruction-following benchmarks, it remains unclear whether they can reliably produce outputs aligned with a broad variety of user goals, a concept we refer to as steerability. The abundance of methods proposed to modify LLM behavior makes it unclear whether current LLMs are already steerable, or require further intervention. In particular, LLMs may exhibit (i) poor coverage, where rare user goals are underrepresented; (ii) miscalibration, where models overshoot requests; and (iii) side effects, where changes to one dimension of text inadvertently affect others. To systematically evaluate these failures, we introduce a framework based on a multi-dimensional goal space that models user goals and LLM outputs as vectors with dimensions corresponding to text attributes (e.g., reading difficulty). Applied to a text-rewriting task, we find that current LLMs struggle with steerability, as side effects are persistent. Interventions to improve steerability, such as prompt engineering, best-of-$N$ sampling, and reinforcement learning fine-tuning, have varying effectiveness, yet side effects remain problematic. Our findings suggest that even strong LLMs struggle with steerability, and existing alignment strategies may be insufficient. We open-source our steerability evaluation framework at https://github.com/MLD3/steerability.
Conditional Front-door Adjustment for Heterogeneous Treatment Assignment Effect Estimation Under Non-adherence
May 08, 2025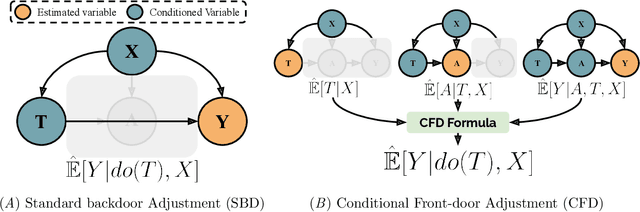
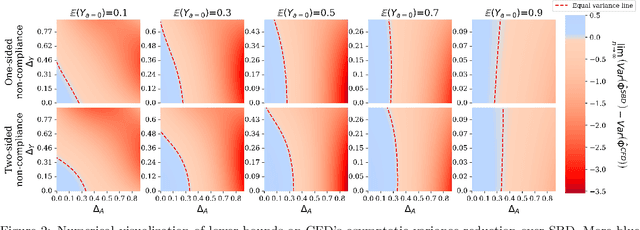
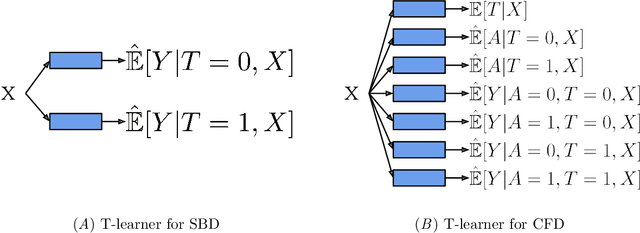
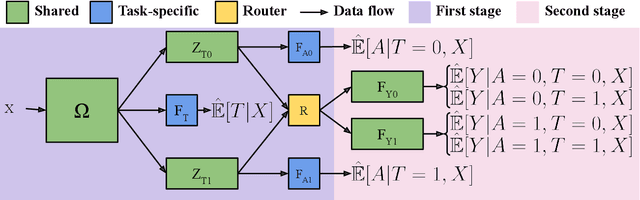
Estimates of heterogeneous treatment assignment effects can inform treatment decisions. Under the presence of non-adherence (e.g., patients do not adhere to their assigned treatment), both the standard backdoor adjustment (SBD) and the conditional front-door adjustment (CFD) can recover unbiased estimates of the treatment assignment effects. However, the estimation variance of these approaches may vary widely across settings, which remains underexplored in the literature. In this work, we demonstrate theoretically and empirically that CFD yields lower-variance estimates than SBD when the true effect of treatment assignment is small (i.e., assigning an intervention leads to small changes in patients' future outcome). Additionally, since CFD requires estimating multiple nuisance parameters, we introduce LobsterNet, a multi-task neural network that implements CFD with joint modeling of the nuisance parameters. Empirically, LobsterNet reduces estimation error across several semi-synthetic and real-world datasets compared to baselines. Our findings suggest CFD with shared nuisance parameter modeling can improve treatment assignment effect estimation under non-adherence.
Understanding GNNs and Homophily in Dynamic Node Classification
Apr 29, 2025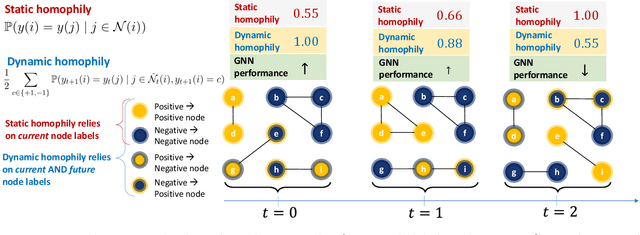

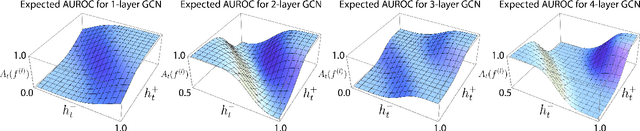

Homophily, as a measure, has been critical to increasing our understanding of graph neural networks (GNNs). However, to date this measure has only been analyzed in the context of static graphs. In our work, we explore homophily in dynamic settings. Focusing on graph convolutional networks (GCNs), we demonstrate theoretically that in dynamic settings, current GCN discriminative performance is characterized by the probability that a node's future label is the same as its neighbors' current labels. Based on this insight, we propose dynamic homophily, a new measure of homophily that applies in the dynamic setting. This new measure correlates with GNN discriminative performance and sheds light on how to potentially design more powerful GNNs for dynamic graphs. Leveraging a variety of dynamic node classification datasets, we demonstrate that popular GNNs are not robust to low dynamic homophily. Going forward, our work represents an important step towards understanding homophily and GNN performance in dynamic node classification.
Learning Laplacian Positional Encodings for Heterophilous Graphs
Apr 29, 2025In this work, we theoretically demonstrate that current graph positional encodings (PEs) are not beneficial and could potentially hurt performance in tasks involving heterophilous graphs, where nodes that are close tend to have different labels. This limitation is critical as many real-world networks exhibit heterophily, and even highly homophilous graphs can contain local regions of strong heterophily. To address this limitation, we propose Learnable Laplacian Positional Encodings (LLPE), a new PE that leverages the full spectrum of the graph Laplacian, enabling them to capture graph structure on both homophilous and heterophilous graphs. Theoretically, we prove LLPE's ability to approximate a general class of graph distances and demonstrate its generalization properties. Empirically, our evaluation on 12 benchmarks demonstrates that LLPE improves accuracy across a variety of GNNs, including graph transformers, by up to 35% and 14% on synthetic and real-world graphs, respectively. Going forward, our work represents a significant step towards developing PEs that effectively capture complex structures in heterophilous graphs.
Towards Fast Graph Generation via Autoregressive Noisy Filtration Modeling
Feb 04, 2025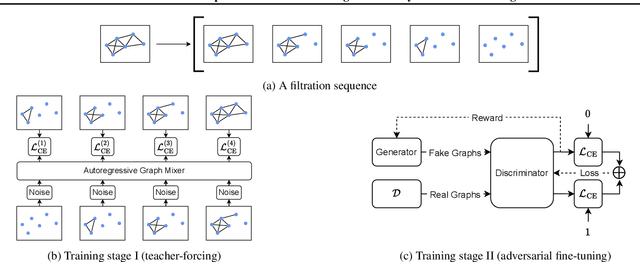


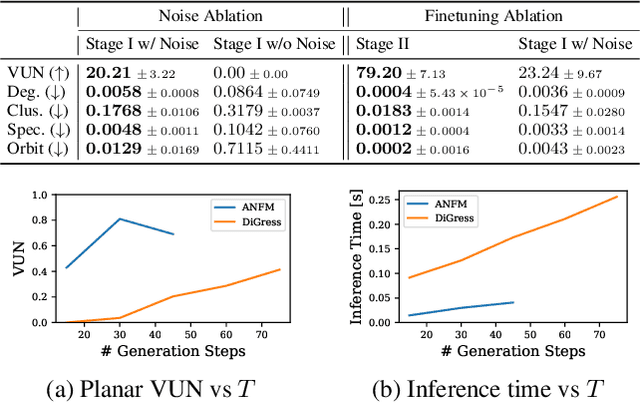
Graph generative models often face a critical trade-off between learning complex distributions and achieving fast generation speed. We introduce Autoregressive Noisy Filtration Modeling (ANFM), a novel approach that addresses both challenges. ANFM leverages filtration, a concept from topological data analysis, to transform graphs into short sequences of monotonically increasing subgraphs. This formulation extends the sequence families used in previous autoregressive models. To learn from these sequences, we propose a novel autoregressive graph mixer model. Our experiments suggest that exposure bias might represent a substantial hurdle in autoregressive graph generation and we introduce two mitigation strategies to address it: noise augmentation and a reinforcement learning approach. Incorporating these techniques leads to substantial performance gains, making ANFM competitive with state-of-the-art diffusion models across diverse synthetic and real-world datasets. Notably, ANFM produces remarkably short sequences, achieving a 100-fold speedup in generation time compared to diffusion models. This work marks a significant step toward high-throughput graph generation.
CANDOR: Counterfactual ANnotated DOubly Robust Off-Policy Evaluation
Dec 11, 2024



Off-policy evaluation (OPE) provides safety guarantees by estimating the performance of a policy before deployment. Recent work introduced IS+, an importance sampling (IS) estimator that uses expert-annotated counterfactual samples to improve behavior dataset coverage. However, IS estimators are known to have high variance; furthermore, the performance of IS+ deteriorates when annotations are imperfect. In this work, we propose a family of OPE estimators inspired by the doubly robust (DR) principle. A DR estimator combines IS with a reward model estimate, known as the direct method (DM), and offers favorable statistical guarantees. We propose three strategies for incorporating counterfactual annotations into a DR-inspired estimator and analyze their properties under various realistic settings. We prove that using imperfect annotations in the DM part of the estimator best leverages the annotations, as opposed to using them in the IS part. To support our theoretical findings, we evaluate the proposed estimators in three contextual bandit environments. Our empirical results show that when the reward model is misspecified and the annotations are imperfect, it is most beneficial to use the annotations only in the DM portion of a DR estimator. Based on these theoretical and empirical insights, we provide a practical guide for using counterfactual annotations in different realistic settings.