 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive Machine Learning Triage Framework for Predicting Alzheimer's Disease Progression
Nov 10, 2025Accurate predictions of conversion from mild cognitive impairment (MCI) to Alzheimer's disease (AD) can enable effective personalized therapy. While cognitive tests and clinical data are routinely collected, they lack the predictive power of PET scans and CSF biomarker analysis, which are prohibitively expensive to obtain for every patient. To address this cost-accuracy dilemma, we design a two-stage machine learning framework that selectively obtains advanced, costly features based on their predicted "value of information". We apply our framework to predict AD progression for MCI patients using data from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Our framework reduces the need for advanced testing by 20% while achieving a test AUROC of 0.929, comparable to the model that uses both basic and advanced features (AUROC=0.915, p=0.1010). We also provide an example interpretability analysis showing how one may explain the triage decision. Our work presents an interpretable, data-driven framework that optimizes AD diagnostic pathways and balances accuracy with cost, representing a step towards making early, reliable AD prediction more accessible in real-world practice. Future work should consider multiple categories of advanced features and larger-scale validation.
CANDOR: Counterfactual ANnotated DOubly Robust Off-Policy Evaluation
Dec 11, 2024



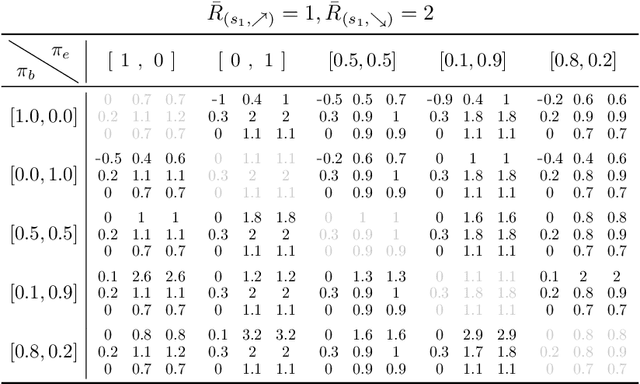
Off-policy evaluation (OPE) provides safety guarantees by estimating the performance of a policy before deployment. Recent work introduced IS+, an importance sampling (IS) estimator that uses expert-annotated counterfactual samples to improve behavior dataset coverage. However, IS estimators are known to have high variance; furthermore, the performance of IS+ deteriorates when annotations are imperfect. In this work, we propose a family of OPE estimators inspired by the doubly robust (DR) principle. A DR estimator combines IS with a reward model estimate, known as the direct method (DM), and offers favorable statistical guarantees. We propose three strategies for incorporating counterfactual annotations into a DR-inspired estimator and analyze their properties under various realistic settings. We prove that using imperfect annotations in the DM part of the estimator best leverages the annotations, as opposed to using them in the IS part. To support our theoretical findings, we evaluate the proposed estimators in three contextual bandit environments. Our empirical results show that when the reward model is misspecified and the annotations are imperfect, it is most beneficial to use the annotations only in the DM portion of a DR estimator. Based on these theoretical and empirical insights, we provide a practical guide for using counterfactual annotations in different realistic settings.
Machine Learning for Health symposium 2023 -- Findings track
Dec 01, 2023A collection of the accepted Findings papers that were presented at the 3rd Machine Learning for Health symposium (ML4H 2023), which was held on December 10, 2023, in New Orleans, Louisiana, USA. ML4H 2023 invited high-quality submissions on relevant problems in a variety of health-related disciplines including healthcare, biomedicine, and public health. Two submission tracks were offered: the archival Proceedings track, and the non-archival Findings track. Proceedings were targeted at mature work with strong technical sophistication and a high impact to health. The Findings track looked for new ideas that could spark insightful discussion, serve as valuable resources for the community, or could enable new collaborations. Submissions to the Proceedings track, if not accepted, were automatically considered for the Findings track. All the manuscripts submitted to ML4H Symposium underwent a double-blind peer-review process.
Counterfactual-Augmented Importance Sampling for Semi-Offline Policy Evaluation
Oct 26, 2023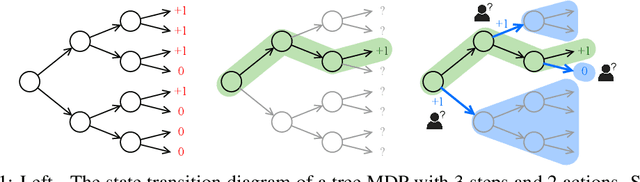

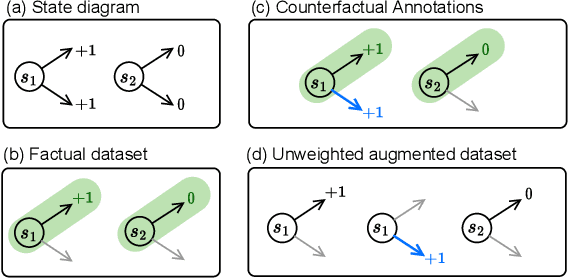
In applying reinforcement learning (RL) to high-stakes domains, quantitative and qualitative evaluation using observational data can help practitioners understand the generalization performance of new policies. However, this type of off-policy evaluation (OPE) is inherently limited since offline data may not reflect the distribution shifts resulting from the application of new policies. On the other hand, online evaluation by collecting rollouts according to the new policy is often infeasible, as deploying new policies in these domains can be unsafe. In this work, we propose a semi-offline evaluation framework as an intermediate step between offline and online evaluation, where human users provide annotations of unobserved counterfactual trajectories. While tempting to simply augment existing data with such annotations, we show that this naive approach can lead to biased results. Instead, we design a new family of OPE estimators based on importance sampling (IS) and a novel weighting scheme that incorporate counterfactual annotations without introducing additional bias. We analyze the theoretical properties of our approach, showing its potential to reduce both bias and variance compared to standard IS estimators. Our analyses reveal important practical considerations for handling biased, noisy, or missing annotations. In a series of proof-of-concept experiments involving bandits and a healthcare-inspired simulator, we demonstrate that our approach outperforms purely offline IS estimators and is robust to imperfect annotations. Our framework, combined with principled human-centered design of annotation solicitation, can enable the application of RL in high-stakes domains.
Leveraging Factored Action Spaces for Off-Policy Evaluation
Jul 13, 2023



Off-policy evaluation (OPE) aims to estimate the benefit of following a counterfactual sequence of actions, given data collected from executed sequences. However, existing OPE estimators often exhibit high bias and high variance in problems involving large, combinatorial action spaces. We investigate how to mitigate this issue using factored action spaces i.e. expressing each action as a combination of independent sub-actions from smaller action spaces. This approach facilitates a finer-grained analysis of how actions differ in their effects. In this work, we propose a new family of "decomposed" importance sampling (IS) estimators based on factored action spaces. Given certain assumptions on the underlying problem structure, we prove that the decomposed IS estimators have less variance than their original non-decomposed versions, while preserving the property of zero bias. Through simulations, we empirically verify our theoretical results, probing the validity of various assumptions. Provided with a technique that can derive the action space factorisation for a given problem, our work shows that OPE can be improved "for free" by utilising this inherent problem structure.
Leveraging Factored Action Spaces for Efficient Offline Reinforcement Learning in Healthcare
May 02, 2023Many reinforcement learning (RL) applications have combinatorial action spaces, where each action is a composition of sub-actions. A standard RL approach ignores this inherent factorization structure, resulting in a potential failure to make meaningful inferences about rarely observed sub-action combinations; this is particularly problematic for offline settings, where data may be limited. In this work, we propose a form of linear Q-function decomposition induced by factored action spaces. We study the theoretical properties of our approach, identifying scenarios where it is guaranteed to lead to zero bias when used to approximate the Q-function. Outside the regimes with theoretical guarantees, we show that our approach can still be useful because it leads to better sample efficiency without necessarily sacrificing policy optimality, allowing us to achieve a better bias-variance trade-off. Across several offline RL problems using simulators and real-world datasets motivated by healthcare, we demonstrate that incorporating factored action spaces into value-based RL can result in better-performing policies. Our approach can help an agent make more accurate inferences within underexplored regions of the state-action space when applying RL to observational datasets.
Machine Learning for Health symposium 2022 -- Extended Abstract track
Nov 28, 2022A collection of the extended abstracts that were presented at the 2nd Machine Learning for Health symposium (ML4H 2022), which was held both virtually and in person on November 28, 2022, in New Orleans, Louisiana, USA. Machine Learning for Health (ML4H) is a longstanding venue for research into machine learning for health, including both theoretical works and applied works. ML4H 2022 featured two submission tracks: a proceedings track, which encompassed full-length submissions of technically mature and rigorous work, and an extended abstract track, which would accept less mature, but innovative research for discussion. All the manuscripts submitted to ML4H Symposium underwent a double-blind peer-review process. Extended abstracts included in this collection describe innovative machine learning research focused on relevant problems in health and biomedicine.
Towards Data-Driven Offline Simulations for Online Reinforcement Learning
Nov 14, 2022



Modern decision-making systems, from robots to web recommendation engines, are expected to adapt: to user preferences, changing circumstances or even new tasks. Yet, it is still uncommon to deploy a dynamically learning agent (rather than a fixed policy) to a production system, as it's perceived as unsafe. Using historical data to reason about learning algorithms, similar to offline policy evaluation (OPE) applied to fixed policies, could help practitioners evaluate and ultimately deploy such adaptive agents to production. In this work, we formalize offline learner simulation (OLS) for reinforcement learning (RL) and propose a novel evaluation protocol that measures both fidelity and efficiency of the simulation. For environments with complex high-dimensional observations, we propose a semi-parametric approach that leverages recent advances in latent state discovery in order to achieve accurate and efficient offline simulations. In preliminary experiments, we show the advantage of our approach compared to fully non-parametric baselines. The code to reproduce these experiments will be made available at https://github.com/microsoft/rl-offline-simulation.
Model Selection for Offline Reinforcement Learning: Practical Considerations for Healthcare Settings
Jul 23, 2021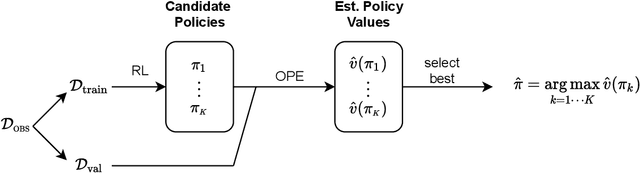

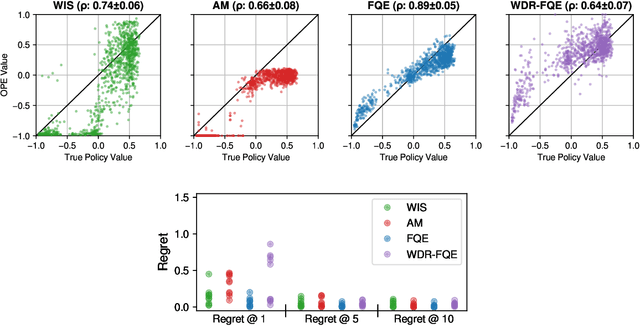
Reinforcement learning (RL) can be used to learn treatment policies and aid decision making in healthcare. However, given the need for generalization over complex state/action spaces, the incorporation of function approximators (e.g., deep neural networks) requires model selection to reduce overfitting and improve policy performance at deployment. Yet a standard validation pipeline for model selection requires running a learned policy in the actual environment, which is often infeasible in a healthcare setting. In this work, we investigate a model selection pipeline for offline RL that relies on off-policy evaluation (OPE) as a proxy for validation performance. We present an in-depth analysis of popular OPE methods, highlighting the additional hyperparameters and computational requirements (fitting/inference of auxiliary models) when used to rank a set of candidate policies. We compare the utility of different OPE methods as part of the model selection pipeline in the context of learning to treat patients with sepsis. Among all the OPE methods we considered, fitted Q evaluation (FQE) consistently leads to the best validation ranking, but at a high computational cost. To balance this trade-off between accuracy of ranking and computational efficiency, we propose a simple two-stage approach to accelerate model selection by avoiding potentially unnecessary computation. Our work serves as a practical guide for offline RL model selection and can help RL practitioners select policies using real-world datasets. To facilitate reproducibility and future extensions, the code accompanying this paper is available online at https://github.com/MLD3/OfflineRL_ModelSelection.
Clinician-in-the-Loop Decision Making: Reinforcement Learning with Near-Optimal Set-Valued Policies
Jul 24, 2020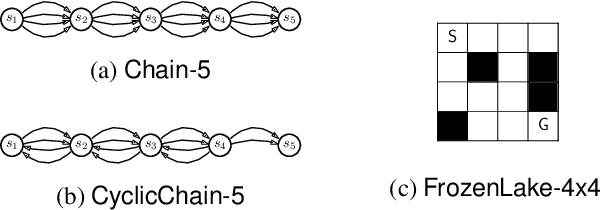

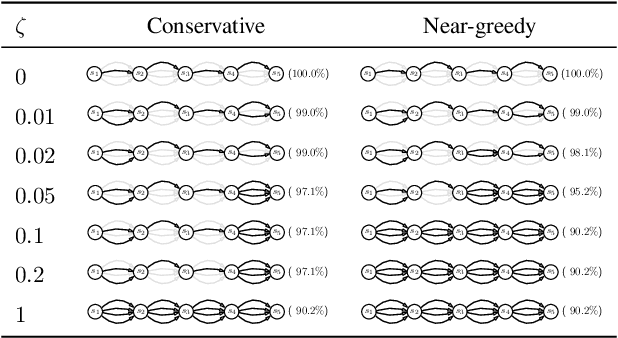
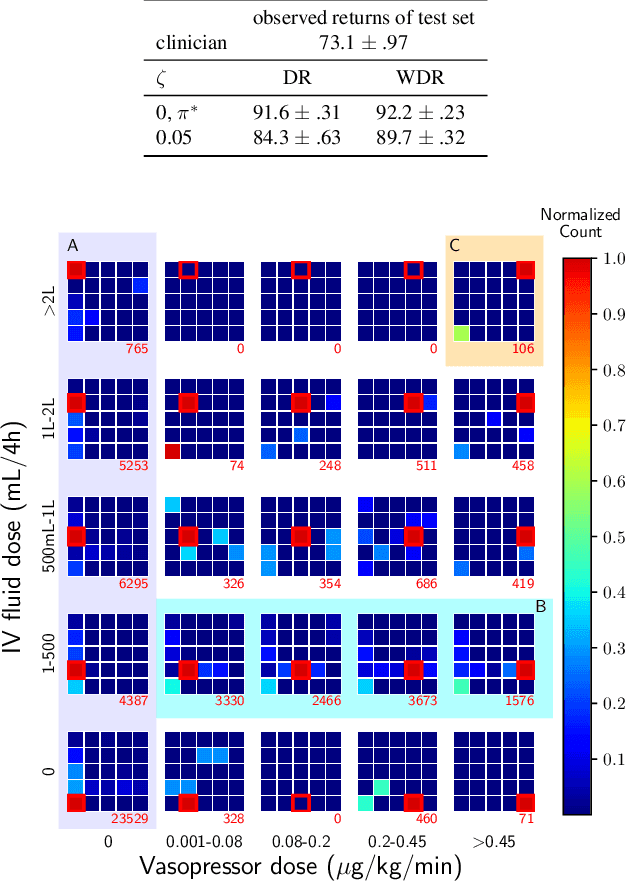
Standard reinforcement learning (RL) aims to find an optimal policy that identifies the best action for each state. However, in healthcare settings, many actions may be near-equivalent with respect to the reward (e.g., survival). We consider an alternative objective -- learning set-valued policies to capture near-equivalent actions that lead to similar cumulative rewards. We propose a model-free algorithm based on temporal difference learning and a near-greedy heuristic for action selection. We analyze the theoretical properties of the proposed algorithm, providing optimality guarantees and demonstrate our approach on simulated environments and a real clinical task. Empirically, the proposed algorithm exhibits good convergence properties and discovers meaningful near-equivalent actions. Our work provides theoretical, as well as practical, foundations for clinician/human-in-the-loop decision making, in which humans (e.g., clinicians, patients) can incorporate additional knowledge (e.g., side effects, patient preference) when selecting among near-equivalent actions.