 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Model Performance in the Presence of an Intervention
Nov 14, 2025AI models are often evaluated based on their ability to predict the outcome of interest. However, in many AI for social impact applications, the presence of an intervention that affects the outcome can bias the evaluation. Randomized controlled trials (RCTs) randomly assign interventions, allowing data from the control group to be used for unbiased model evaluation. However, this approach is inefficient because it ignores data from the treatment group. Given the complexity and cost often associated with RCTs, making the most use of the data is essential. Thus, we investigate model evaluation strategies that leverage all data from an RCT. First, we theoretically quantify the estimation bias that arises from naïvely aggregating performance estimates from treatment and control groups and derive the condition under which this bias leads to incorrect model selection. Leveraging these theoretical insights, we propose nuisance parameter weighting (NPW), an unbiased model evaluation approach that reweights data from the treatment group to mimic the distributions of samples that would or would not experience the outcome under no intervention. Using synthetic and real-world datasets, we demonstrate that our proposed evaluation approach consistently yields better model selection than the standard approach, which ignores data from the treatment group, across various intervention effect and sample size settings. Our contribution represents a meaningful step towards more efficient model evaluation in real-world contexts.
On the Limits of Selective AI Prediction: A Case Study in Clinical Decision Making
Aug 11, 2025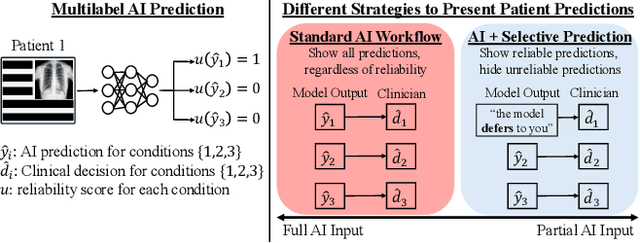
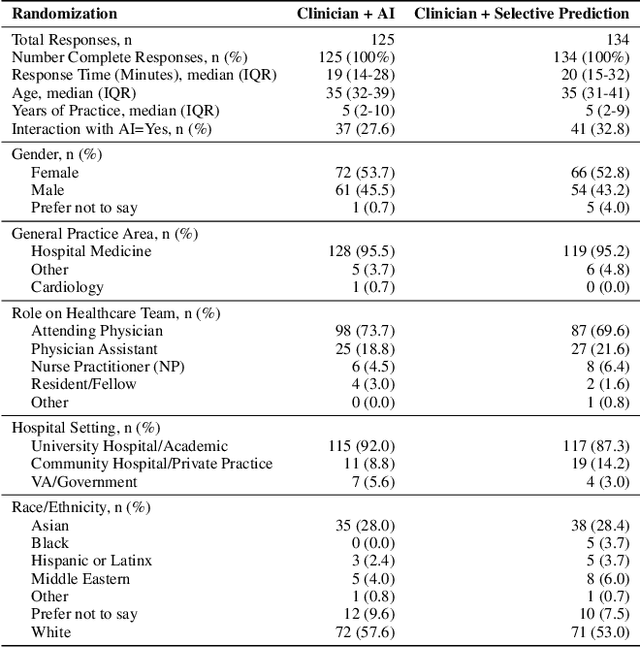
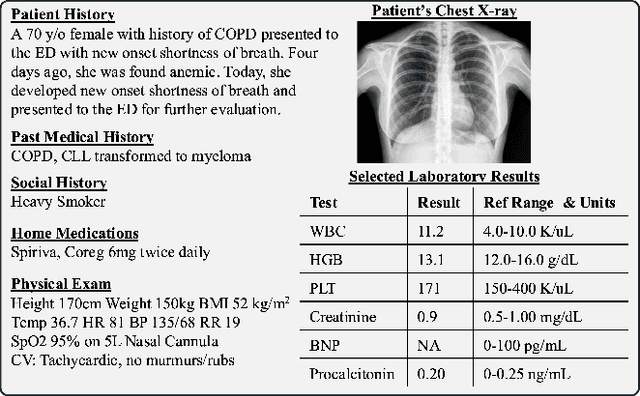
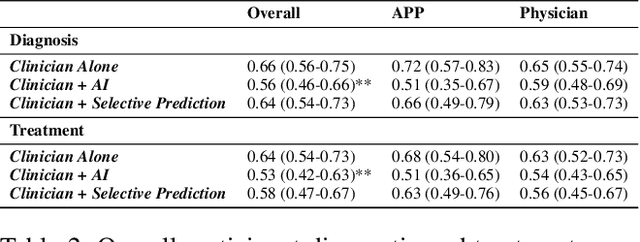
AI has the potential to augment human decision making. However, even high-performing models can produce inaccurate predictions when deployed. These inaccuracies, combined with automation bias, where humans overrely on AI predictions, can result in worse decisions. Selective prediction, in which potentially unreliable model predictions are hidden from users, has been proposed as a solution. This approach assumes that when AI abstains and informs the user so, humans make decisions as they would without AI involvement. To test this assumption, we study the effects of selective prediction on human decisions in a clinical context. We conducted a user study of 259 clinicians tasked with diagnosing and treating hospitalized patients. We compared their baseline performance without any AI involvement to their AI-assisted accuracy with and without selective prediction. Our findings indicate that selective prediction mitigates the negative effects of inaccurate AI in terms of decision accuracy. Compared to no AI assistance, clinician accuracy declined when shown inaccurate AI predictions (66% [95% CI: 56%-75%] vs. 56% [95% CI: 46%-66%]), but recovered under selective prediction (64% [95% CI: 54%-73%]). However, while selective prediction nearly maintains overall accuracy, our results suggest that it alters patterns of mistakes: when informed the AI abstains, clinicians underdiagnose (18% increase in missed diagnoses) and undertreat (35% increase in missed treatments) compared to no AI input at all. Our findings underscore the importance of empirically validating assumptions about how humans engage with AI within human-AI systems.
Leveraging Factored Action Spaces for Efficient Offline Reinforcement Learning in Healthcare
May 02, 2023Many reinforcement learning (RL) applications have combinatorial action spaces, where each action is a composition of sub-actions. A standard RL approach ignores this inherent factorization structure, resulting in a potential failure to make meaningful inferences about rarely observed sub-action combinations; this is particularly problematic for offline settings, where data may be limited. In this work, we propose a form of linear Q-function decomposition induced by factored action spaces. We study the theoretical properties of our approach, identifying scenarios where it is guaranteed to lead to zero bias when used to approximate the Q-function. Outside the regimes with theoretical guarantees, we show that our approach can still be useful because it leads to better sample efficiency without necessarily sacrificing policy optimality, allowing us to achieve a better bias-variance trade-off. Across several offline RL problems using simulators and real-world datasets motivated by healthcare, we demonstrate that incorporating factored action spaces into value-based RL can result in better-performing policies. Our approach can help an agent make more accurate inferences within underexplored regions of the state-action space when applying RL to observational datasets.
Disparate Censorship & Undertesting: A Source of Label Bias in Clinical Machine Learning
Aug 01, 2022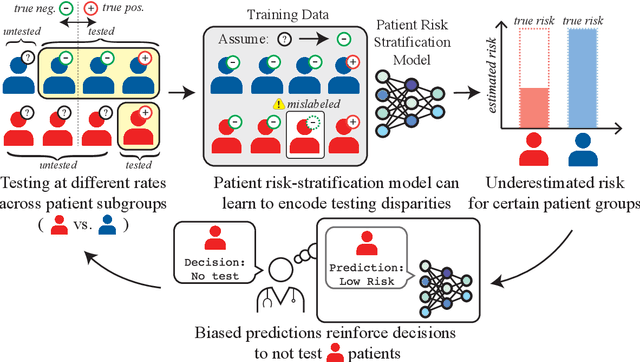
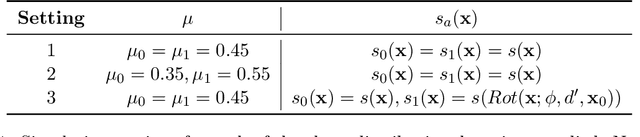
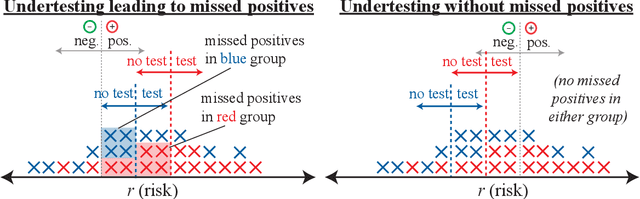
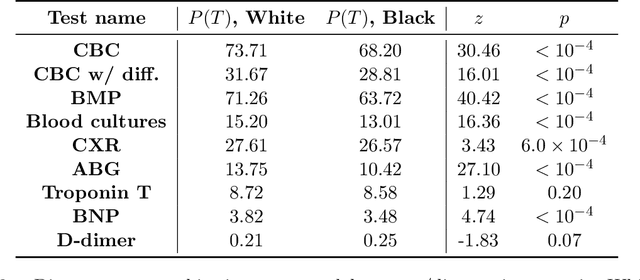
As machine learning (ML) models gain traction in clinical applications, understanding the impact of clinician and societal biases on ML models is increasingly important. While biases can arise in the labels used for model training, the many sources from which these biases arise are not yet well-studied. In this paper, we highlight disparate censorship (i.e., differences in testing rates across patient groups) as a source of label bias that clinical ML models may amplify, potentially causing harm. Many patient risk-stratification models are trained using the results of clinician-ordered diagnostic and laboratory tests of labels. Patients without test results are often assigned a negative label, which assumes that untested patients do not experience the outcome. Since orders are affected by clinical and resource considerations, testing may not be uniform in patient populations, giving rise to disparate censorship. Disparate censorship in patients of equivalent risk leads to undertesting in certain groups, and in turn, more biased labels for such groups. Using such biased labels in standard ML pipelines could contribute to gaps in model performance across patient groups. Here, we theoretically and empirically characterize conditions in which disparate censorship or undertesting affect model performance across subgroups. Our findings call attention to disparate censorship as a source of label bias in clinical ML models.
Deep Learning Applied to Chest X-Rays: Exploiting and Preventing Shortcuts
Sep 21, 2020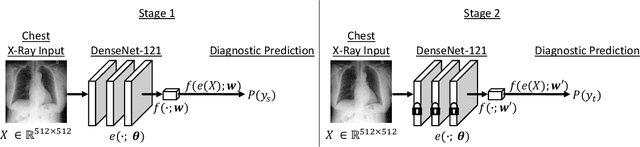
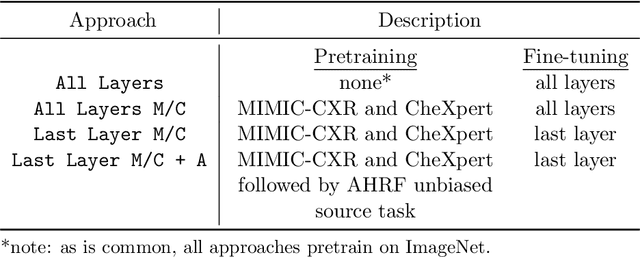
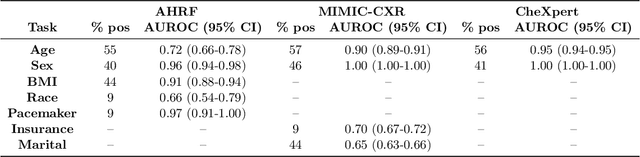
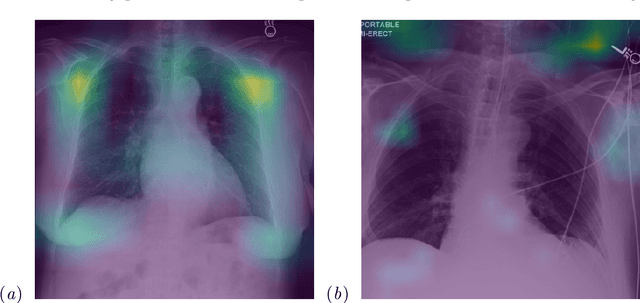
While deep learning has shown promise in improving the automated diagnosis of disease based on chest X-rays, deep networks may exhibit undesirable behavior related to shortcuts. This paper studies the case of spurious class skew in which patients with a particular attribute are spuriously more likely to have the outcome of interest. For instance, clinical protocols might lead to a dataset in which patients with pacemakers are disproportionately likely to have congestive heart failure. This skew can lead to models that take shortcuts by heavily relying on the biased attribute. We explore this problem across a number of attributes in the context of diagnosing the cause of acute hypoxemic respiratory failure. Applied to chest X-rays, we show that i) deep nets can accurately identify many patient attributes including sex (AUROC = 0.96) and age (AUROC >= 0.90), ii) they tend to exploit correlations between such attributes and the outcome label when learning to predict a diagnosis, leading to poor performance when such correlations do not hold in the test population (e.g., everyone in the test set is male), and iii) a simple transfer learning approach is surprisingly effective at preventing the shortcut and promoting good generalization performance. On the task of diagnosing congestive heart failure based on a set of chest X-rays skewed towards older patients (age >= 63), the proposed approach improves generalization over standard training from 0.66 (95% CI: 0.54-0.77) to 0.84 (95% CI: 0.73-0.92) AUROC. While simple, the proposed approach has the potential to improve the performance of models across populations by encouraging reliance on clinically relevant manifestations of disease, i.e., those that a clinician would use to make a diagnosis.
Clinician-in-the-Loop Decision Making: Reinforcement Learning with Near-Optimal Set-Valued Policies
Jul 24, 2020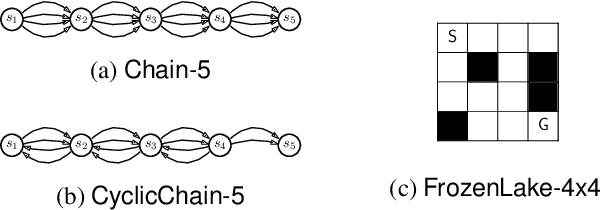

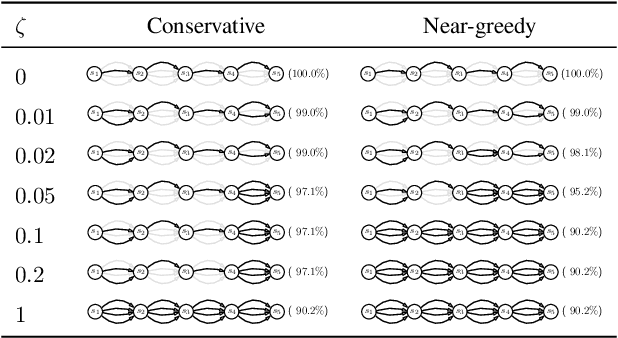
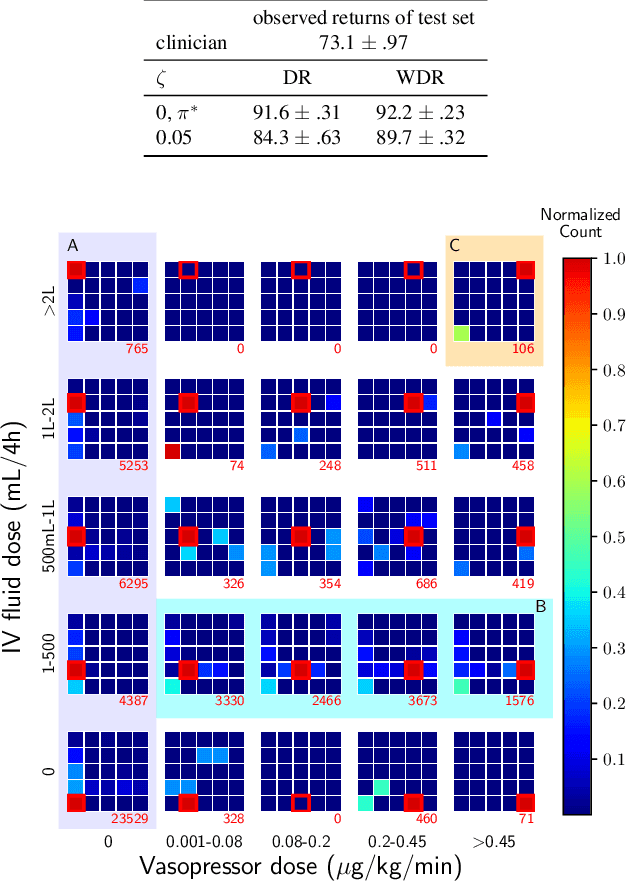
Standard reinforcement learning (RL) aims to find an optimal policy that identifies the best action for each state. However, in healthcare settings, many actions may be near-equivalent with respect to the reward (e.g., survival). We consider an alternative objective -- learning set-valued policies to capture near-equivalent actions that lead to similar cumulative rewards. We propose a model-free algorithm based on temporal difference learning and a near-greedy heuristic for action selection. We analyze the theoretical properties of the proposed algorithm, providing optimality guarantees and demonstrate our approach on simulated environments and a real clinical task. Empirically, the proposed algorithm exhibits good convergence properties and discovers meaningful near-equivalent actions. Our work provides theoretical, as well as practical, foundations for clinician/human-in-the-loop decision making, in which humans (e.g., clinicians, patients) can incorporate additional knowledge (e.g., side effects, patient preference) when selecting among near-equivalent actions.