 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Transfer of a Physics Foundation Model from Simulation to Laboratory Turbulence
May 31, 2026Whether physics foundation models can be usefully deployed on laboratory experiments remains an open question for scientific machine learning (ML). We test this question on the Rayleigh-Taylor instability (RTI), a ubiquitous and demanding fluid instability seen from tabletop flows to supernova explosions, in which small perturbations at a density interface grow into chaotic, multiscale mixing as a lighter fluid accelerates into a heavier one. Standard ML models struggle with RTI, and despite over a century of theoretical, numerical, and experimental work, it carries an unresolved discrepancy between simulation and experiment: the late-time mixing growth rate, $α$, measured in most laboratory experiments ($\sim$ 0.06-0.07), is roughly three times the value from idealized direct numerical simulations (DNS, $\sim$ 0.02). The gap's origin remains debated. These properties make RTI a stringent test for a question that matters well beyond RTI: can foundation models trained only on simulations generalise to sparse, messy, and noisy laboratory settings? We finetune Walrus, a foundation model for continuum dynamics, on three or fewer DNS realizations and recover key RTI physics over long rollouts. Applied zero-shot to sliding-barrier laboratory data, the finetuned model leaves the DNS-like regime and enters the observed growth band, having never seen a single experimental sample. These results provide independent, data-driven evidence that initial conditions play a crucial role in the longstanding sim-experiment gap in $α$. The model also generalises zero-shot to stable stratification, a buoyancy regime absent from training, correctly slowing mixing-layer growth. Together, our results show that foundation models can generalise well beyond their training data, predicting laboratory behavior and unseen physical regimes, opening new ways to probe longstanding simulation-experiment gaps.
MIMIC: A Generative Multimodal Foundation Model for Biomolecules
Apr 27, 2026Biological function emerges from coupled constraints across sequence, structure, regulation, evolution, and cellular context, yet most foundation models in biology are trained within one modality or for a fixed forward task. We present MIMIC, a generative multimodal foundation model trained on our newly curated and aligned dataset, LORE, linking nucleic acid, protein, evolutionary, structural, regulatory, and semantic/contextual modalities within partially observed biomolecular states. MIMIC uses a split-track encoder-decoder architecture to condition on arbitrary subsets of observed modalities and reconstruct or generate missing components of molecular state across the genome, transcriptome, and proteome. Multimodal conditioning consistently improves MIMIC's sequence reconstruction relative to sequence-only inputs, while its learned representations enable state-of-the-art performance on RNA and protein downstream tasks. MIMIC achieves state-of-the-art splicing prediction, and its joint generative formulation enables isoform-aware inference that further improves performance. Beyond prediction, the same generative framework supports constrained design. For RNA, MIMIC identifies corrective edits in a clinically relevant HBB splice-disrupting mutation without reverting it by using evolutionary and structural signals. For proteins, jointly conditioning on shape and surface chemistry of PD-L1 and hACE2 binding sites produces diverse, high-confidence sequences with strong in silico support for target binding. Finally, MIMIC uses experimental context as semantic conditioning to model assay-dependent RNA chemical probing, rather than treating context as a fixed output. Together, these results position MIMIC's aligned multimodal generative modeling as a strong foundation for unifying representation learning, conditional prediction, and constrained biomolecular design within a single model.
On the Limits of Selective AI Prediction: A Case Study in Clinical Decision Making
Aug 11, 2025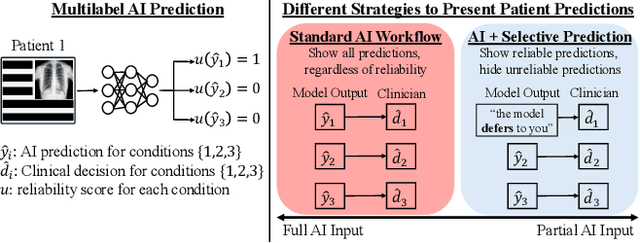
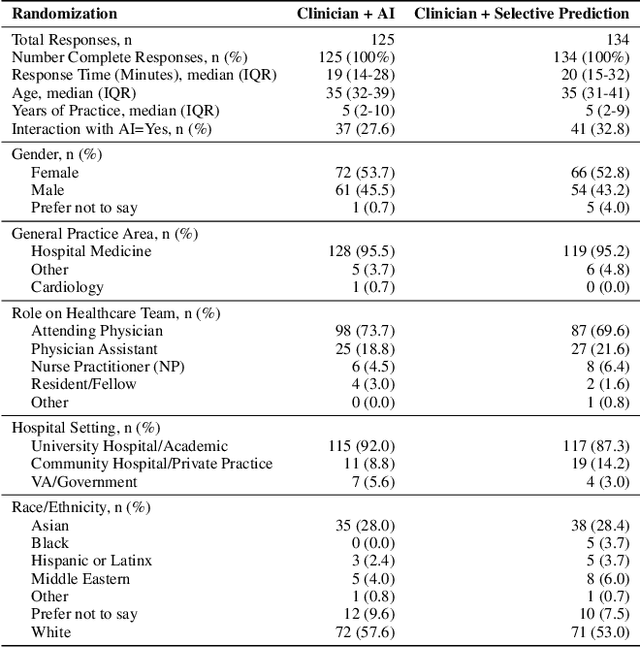
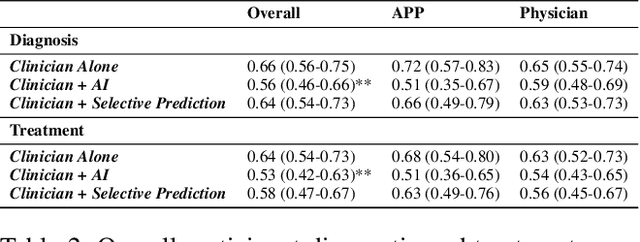
AI has the potential to augment human decision making. However, even high-performing models can produce inaccurate predictions when deployed. These inaccuracies, combined with automation bias, where humans overrely on AI predictions, can result in worse decisions. Selective prediction, in which potentially unreliable model predictions are hidden from users, has been proposed as a solution. This approach assumes that when AI abstains and informs the user so, humans make decisions as they would without AI involvement. To test this assumption, we study the effects of selective prediction on human decisions in a clinical context. We conducted a user study of 259 clinicians tasked with diagnosing and treating hospitalized patients. We compared their baseline performance without any AI involvement to their AI-assisted accuracy with and without selective prediction. Our findings indicate that selective prediction mitigates the negative effects of inaccurate AI in terms of decision accuracy. Compared to no AI assistance, clinician accuracy declined when shown inaccurate AI predictions (66% [95% CI: 56%-75%] vs. 56% [95% CI: 46%-66%]), but recovered under selective prediction (64% [95% CI: 54%-73%]). However, while selective prediction nearly maintains overall accuracy, our results suggest that it alters patterns of mistakes: when informed the AI abstains, clinicians underdiagnose (18% increase in missed diagnoses) and undertreat (35% increase in missed treatments) compared to no AI input at all. Our findings underscore the importance of empirically validating assumptions about how humans engage with AI within human-AI systems.
Slot-Level Robotic Placement via Visual Imitation from Single Human Video
Apr 02, 2025



The majority of modern robot learning methods focus on learning a set of pre-defined tasks with limited or no generalization to new tasks. Extending the robot skillset to novel tasks involves gathering an extensive amount of training data for additional tasks. In this paper, we address the problem of teaching new tasks to robots using human demonstration videos for repetitive tasks (e.g., packing). This task requires understanding the human video to identify which object is being manipulated (the pick object) and where it is being placed (the placement slot). In addition, it needs to re-identify the pick object and the placement slots during inference along with the relative poses to enable robot execution of the task. To tackle this, we propose SLeRP, a modular system that leverages several advanced visual foundation models and a novel slot-level placement detector Slot-Net, eliminating the need for expensive video demonstrations for training. We evaluate our system using a new benchmark of real-world videos. The evaluation results show that SLeRP outperforms several baselines and can be deployed on a real robot.
Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos
Dec 12, 2024Learning to understand dynamic 3D scenes from imagery is crucial for applications ranging from robotics to scene reconstruction. Yet, unlike other problems where large-scale supervised training has enabled rapid progress, directly supervising methods for recovering 3D motion remains challenging due to the fundamental difficulty of obtaining ground truth annotations. We present a system for mining high-quality 4D reconstructions from internet stereoscopic, wide-angle videos. Our system fuses and filters the outputs of camera pose estimation, stereo depth estimation, and temporal tracking methods into high-quality dynamic 3D reconstructions. We use this method to generate large-scale data in the form of world-consistent, pseudo-metric 3D point clouds with long-term motion trajectories. We demonstrate the utility of this data by training a variant of DUSt3R to predict structure and 3D motion from real-world image pairs, showing that training on our reconstructed data enables generalization to diverse real-world scenes. Project page: https://stereo4d.github.io
DEPICT: Diffusion-Enabled Permutation Importance for Image Classification Tasks
Jul 19, 2024



We propose a permutation-based explanation method for image classifiers. Current image-model explanations like activation maps are limited to instance-based explanations in the pixel space, making it difficult to understand global model behavior. In contrast, permutation based explanations for tabular data classifiers measure feature importance by comparing model performance on data before and after permuting a feature. We propose an explanation method for image-based models that permutes interpretable concepts across dataset images. Given a dataset of images labeled with specific concepts like captions, we permute a concept across examples in the text space and then generate images via a text-conditioned diffusion model. Feature importance is then reflected by the change in model performance relative to unpermuted data. When applied to a set of concepts, the method generates a ranking of feature importance. We show this approach recovers underlying model feature importance on synthetic and real-world image classification tasks.
3DFIRES: Few Image 3D REconstruction for Scenes with Hidden Surface
Mar 13, 2024This paper introduces 3DFIRES, a novel system for scene-level 3D reconstruction from posed images. Designed to work with as few as one view, 3DFIRES reconstructs the complete geometry of unseen scenes, including hidden surfaces. With multiple view inputs, our method produces full reconstruction within all camera frustums. A key feature of our approach is the fusion of multi-view information at the feature level, enabling the production of coherent and comprehensive 3D reconstruction. We train our system on non-watertight scans from large-scale real scene dataset. We show it matches the efficacy of single-view reconstruction methods with only one input and surpasses existing techniques in both quantitative and qualitative measures for sparse-view 3D reconstruction.
Reconstructing Hands in 3D with Transformers
Dec 08, 2023
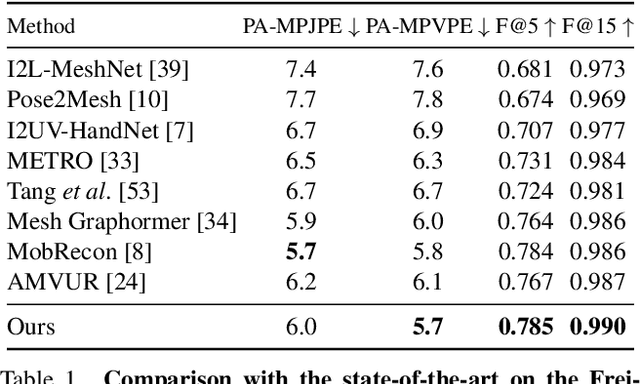
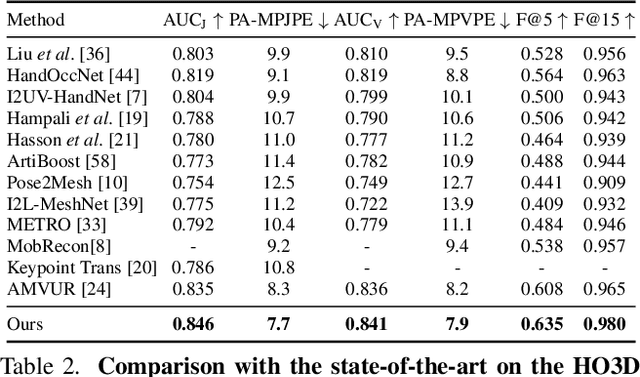
We present an approach that can reconstruct hands in 3D from monocular input. Our approach for Hand Mesh Recovery, HaMeR, follows a fully transformer-based architecture and can analyze hands with significantly increased accuracy and robustness compared to previous work. The key to HaMeR's success lies in scaling up both the data used for training and the capacity of the deep network for hand reconstruction. For training data, we combine multiple datasets that contain 2D or 3D hand annotations. For the deep model, we use a large scale Vision Transformer architecture. Our final model consistently outperforms the previous baselines on popular 3D hand pose benchmarks. To further evaluate the effect of our design in non-controlled settings, we annotate existing in-the-wild datasets with 2D hand keypoint annotations. On this newly collected dataset of annotations, HInt, we demonstrate significant improvements over existing baselines. We make our code, data and models available on the project website: https://geopavlakos.github.io/hamer/.
NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis
Jul 14, 2023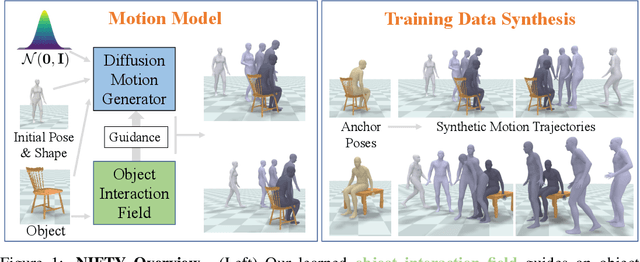

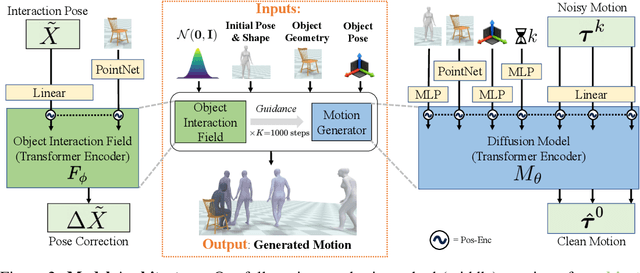
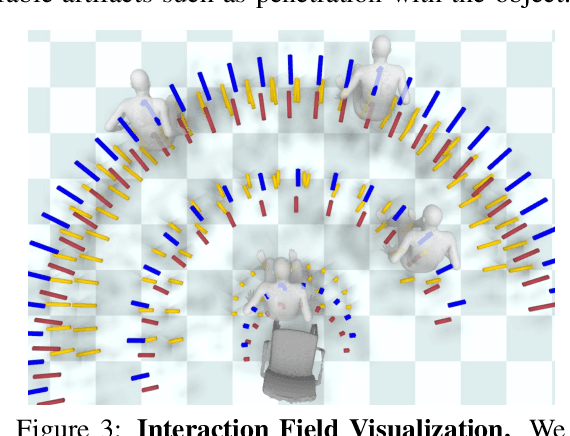
We address the problem of generating realistic 3D motions of humans interacting with objects in a scene. Our key idea is to create a neural interaction field attached to a specific object, which outputs the distance to the valid interaction manifold given a human pose as input. This interaction field guides the sampling of an object-conditioned human motion diffusion model, so as to encourage plausible contacts and affordance semantics. To support interactions with scarcely available data, we propose an automated synthetic data pipeline. For this, we seed a pre-trained motion model, which has priors for the basics of human movement, with interaction-specific anchor poses extracted from limited motion capture data. Using our guided diffusion model trained on generated synthetic data, we synthesize realistic motions for sitting and lifting with several objects, outperforming alternative approaches in terms of motion quality and successful action completion. We call our framework NIFTY: Neural Interaction Fields for Trajectory sYnthesis.
EPIC Fields: Marrying 3D Geometry and Video Understanding
Jun 14, 2023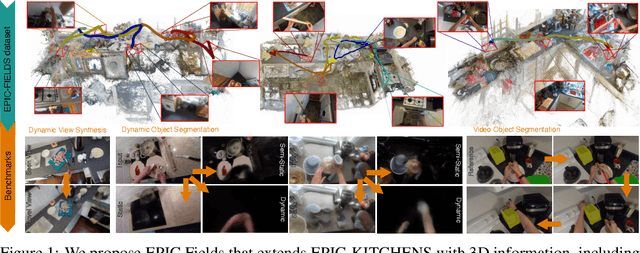

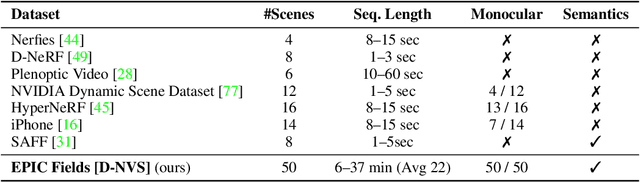

Neural rendering is fuelling a unification of learning, 3D geometry and video understanding that has been waiting for more than two decades. Progress, however, is still hampered by a lack of suitable datasets and benchmarks. To address this gap, we introduce EPIC Fields, an augmentation of EPIC-KITCHENS with 3D camera information. Like other datasets for neural rendering, EPIC Fields removes the complex and expensive step of reconstructing cameras using photogrammetry, and allows researchers to focus on modelling problems. We illustrate the challenge of photogrammetry in egocentric videos of dynamic actions and propose innovations to address them. Compared to other neural rendering datasets, EPIC Fields is better tailored to video understanding because it is paired with labelled action segments and the recent VISOR segment annotations. To further motivate the community, we also evaluate two benchmark tasks in neural rendering and segmenting dynamic objects, with strong baselines that showcase what is not possible today. We also highlight the advantage of geometry in semi-supervised video object segmentations on the VISOR annotations. EPIC Fields reconstructs 96% of videos in EPICKITCHENS, registering 19M frames in 99 hours recorded in 45 kitchens.