 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered Motion Fusion: Lifting Motion Segmentation to 3D in Egocentric Videos
Jun 05, 2025Computer vision is largely based on 2D techniques, with 3D vision still relegated to a relatively narrow subset of applications. However, by building on recent advances in 3D models such as neural radiance fields, some authors have shown that 3D techniques can at last improve outputs extracted from independent 2D views, by fusing them into 3D and denoising them. This is particularly helpful in egocentric videos, where the camera motion is significant, but only under the assumption that the scene itself is static. In fact, as shown in the recent analysis conducted by EPIC Fields, 3D techniques are ineffective when it comes to studying dynamic phenomena, and, in particular, when segmenting moving objects. In this paper, we look into this issue in more detail. First, we propose to improve dynamic segmentation in 3D by fusing motion segmentation predictions from a 2D-based model into layered radiance fields (Layered Motion Fusion). However, the high complexity of long, dynamic videos makes it challenging to capture the underlying geometric structure, and, as a result, hinders the fusion of motion cues into the (incomplete) scene geometry. We address this issue through test-time refinement, which helps the model to focus on specific frames, thereby reducing the data complexity. This results in a synergy between motion fusion and the refinement, and in turn leads to segmentation predictions of the 3D model that surpass the 2D baseline by a large margin. This demonstrates that 3D techniques can enhance 2D analysis even for dynamic phenomena in a challenging and realistic setting.
3D-Aware Instance Segmentation and Tracking in Egocentric Videos
Aug 19, 2024



Egocentric videos present unique challenges for 3D scene understanding due to rapid camera motion, frequent object occlusions, and limited object visibility. This paper introduces a novel approach to instance segmentation and tracking in first-person video that leverages 3D awareness to overcome these obstacles. Our method integrates scene geometry, 3D object centroid tracking, and instance segmentation to create a robust framework for analyzing dynamic egocentric scenes. By incorporating spatial and temporal cues, we achieve superior performance compared to state-of-the-art 2D approaches. Extensive evaluations on the challenging EPIC Fields dataset demonstrate significant improvements across a range of tracking and segmentation consistency metrics. Specifically, our method outperforms the next best performing approach by $7$ points in Association Accuracy (AssA) and $4.5$ points in IDF1 score, while reducing the number of ID switches by $73\%$ to $80\%$ across various object categories. Leveraging our tracked instance segmentations, we showcase downstream applications in 3D object reconstruction and amodal video object segmentation in these egocentric settings.
EPIC Fields: Marrying 3D Geometry and Video Understanding
Jun 14, 2023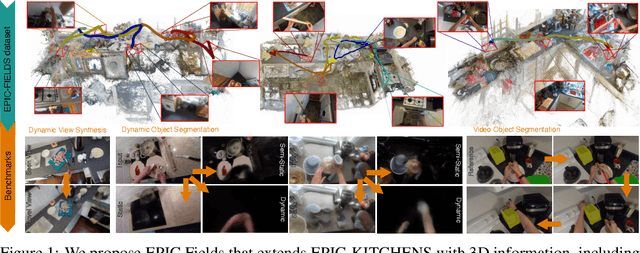


Neural rendering is fuelling a unification of learning, 3D geometry and video understanding that has been waiting for more than two decades. Progress, however, is still hampered by a lack of suitable datasets and benchmarks. To address this gap, we introduce EPIC Fields, an augmentation of EPIC-KITCHENS with 3D camera information. Like other datasets for neural rendering, EPIC Fields removes the complex and expensive step of reconstructing cameras using photogrammetry, and allows researchers to focus on modelling problems. We illustrate the challenge of photogrammetry in egocentric videos of dynamic actions and propose innovations to address them. Compared to other neural rendering datasets, EPIC Fields is better tailored to video understanding because it is paired with labelled action segments and the recent VISOR segment annotations. To further motivate the community, we also evaluate two benchmark tasks in neural rendering and segmenting dynamic objects, with strong baselines that showcase what is not possible today. We also highlight the advantage of geometry in semi-supervised video object segmentations on the VISOR annotations. EPIC Fields reconstructs 96% of videos in EPICKITCHENS, registering 19M frames in 99 hours recorded in 45 kitchens.
Neural Feature Fusion Fields: 3D Distillation of Self-Supervised 2D Image Representations
Sep 07, 2022
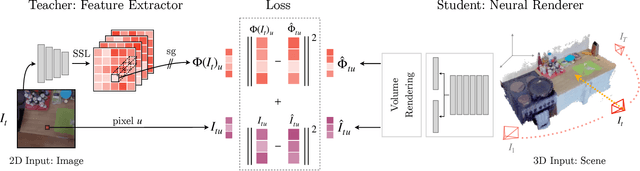

We present Neural Feature Fusion Fields (N3F), a method that improves dense 2D image feature extractors when the latter are applied to the analysis of multiple images reconstructible as a 3D scene. Given an image feature extractor, for example pre-trained using self-supervision, N3F uses it as a teacher to learn a student network defined in 3D space. The 3D student network is similar to a neural radiance field that distills said features and can be trained with the usual differentiable rendering machinery. As a consequence, N3F is readily applicable to most neural rendering formulations, including vanilla NeRF and its extensions to complex dynamic scenes. We show that our method not only enables semantic understanding in the context of scene-specific neural fields without the use of manual labels, but also consistently improves over the self-supervised 2D baselines. This is demonstrated by considering various tasks, such as 2D object retrieval, 3D segmentation, and scene editing, in diverse sequences, including long egocentric videos in the EPIC-KITCHENS benchmark.
NeuralDiff: Segmenting 3D objects that move in egocentric videos
Oct 19, 2021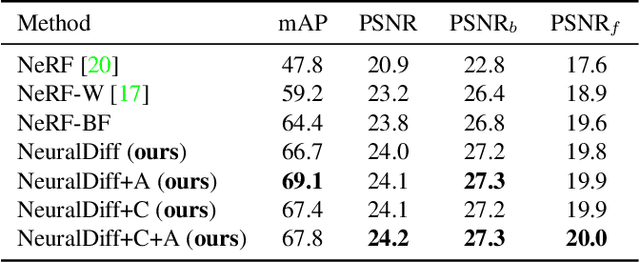
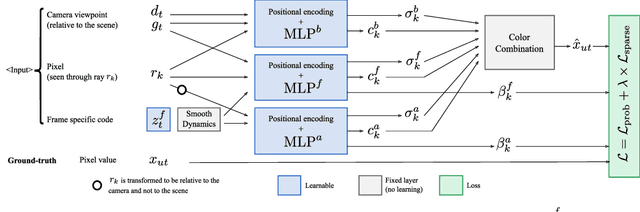


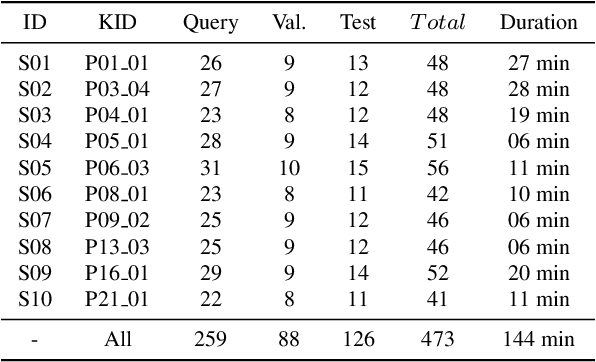
Given a raw video sequence taken from a freely-moving camera, we study the problem of decomposing the observed 3D scene into a static background and a dynamic foreground containing the objects that move in the video sequence. This task is reminiscent of the classic background subtraction problem, but is significantly harder because all parts of the scene, static and dynamic, generate a large apparent motion due to the camera large viewpoint change. In particular, we consider egocentric videos and further separate the dynamic component into objects and the actor that observes and moves them. We achieve this factorization by reconstructing the video via a triple-stream neural rendering network that explains the different motions based on corresponding inductive biases. We demonstrate that our method can successfully separate the different types of motion, outperforming recent neural rendering baselines at this task, and can accurately segment moving objects. We do so by assessing the method empirically on challenging videos from the EPIC-KITCHENS dataset which we augment with appropriate annotations to create a new benchmark for the task of dynamic object segmentation on unconstrained video sequences, for complex 3D environments.
Improving Deep Metric Learning by Divide and Conquer
Sep 09, 2021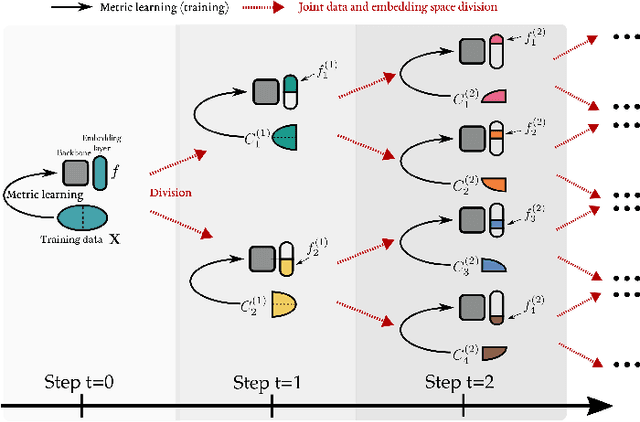



Deep metric learning (DML) is a cornerstone of many computer vision applications. It aims at learning a mapping from the input domain to an embedding space, where semantically similar objects are located nearby and dissimilar objects far from another. The target similarity on the training data is defined by user in form of ground-truth class labels. However, while the embedding space learns to mimic the user-provided similarity on the training data, it should also generalize to novel categories not seen during training. Besides user-provided groundtruth training labels, a lot of additional visual factors (such as viewpoint changes or shape peculiarities) exist and imply different notions of similarity between objects, affecting the generalization on the images unseen during training. However, existing approaches usually directly learn a single embedding space on all available training data, struggling to encode all different types of relationships, and do not generalize well. We propose to build a more expressive representation by jointly splitting the embedding space and the data hierarchically into smaller sub-parts. We successively focus on smaller subsets of the training data, reducing its variance and learning a different embedding subspace for each data subset. Moreover, the subspaces are learned jointly to cover not only the intricacies, but the breadth of the data as well. Only after that, we build the final embedding from the subspaces in the conquering stage. The proposed algorithm acts as a transparent wrapper that can be placed around arbitrary existing DML methods. Our approach significantly improves upon the state-of-the-art on image retrieval, clustering, and re-identification tasks evaluated using CUB200-2011, CARS196, Stanford Online Products, In-shop Clothes, and PKU VehicleID datasets.
Divide and Conquer the Embedding Space for Metric Learning
Jun 14, 2019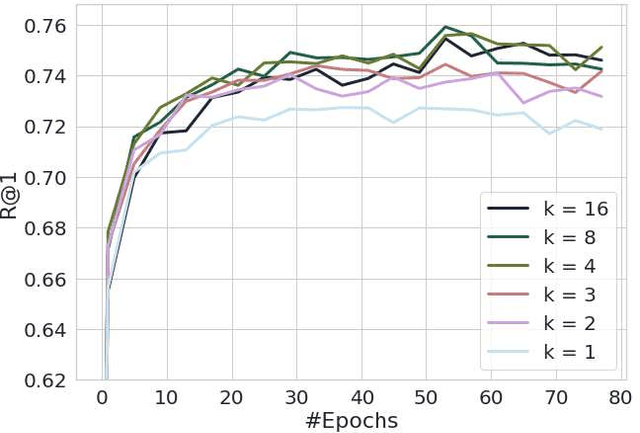
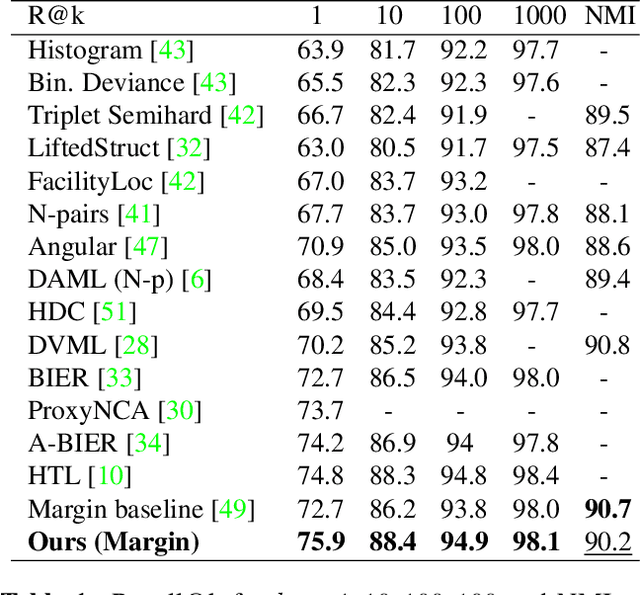
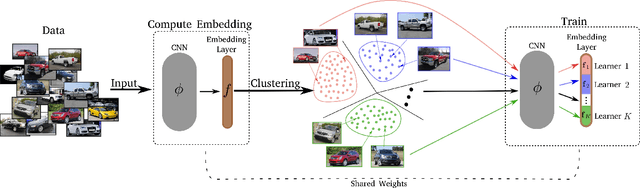
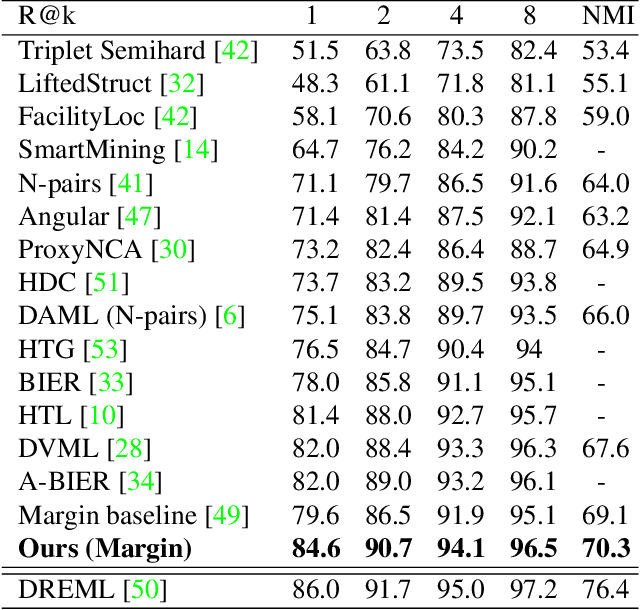
Learning the embedding space, where semantically similar objects are located close together and dissimilar objects far apart, is a cornerstone of many computer vision applications. Existing approaches usually learn a single metric in the embedding space for all available data points, which may have a very complex non-uniform distribution with different notions of similarity between objects, e.g. appearance, shape, color or semantic meaning. Approaches for learning a single distance metric often struggle to encode all different types of relationships and do not generalize well. In this work, we propose a novel easy-to-implement divide and conquer approach for deep metric learning, which significantly improves the state-of-the-art performance of metric learning. Our approach utilizes the embedding space more efficiently by jointly splitting the embedding space and data into $K$ smaller sub-problems. It divides both, the data and the embedding space into $K$ subsets and learns $K$ separate distance metrics in the non-overlapping subspaces of the embedding space, defined by groups of neurons in the embedding layer of the neural network. The proposed approach increases the convergence speed and improves generalization since the complexity of each sub-problem is reduced compared to the original one. We show that our approach outperforms the state-of-the-art by a large margin in retrieval, clustering and re-identification tasks on CUB200-2011, CARS196, Stanford Online Products, In-shop Clothes and PKU VehicleID datasets.
* Source code: https://github.com/CompVis/metric-learning-divide-and-conquer