 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Feature Fusion Fields: 3D Distillation of Self-Supervised 2D Image Representations
Paper and Code
Sep 07, 2022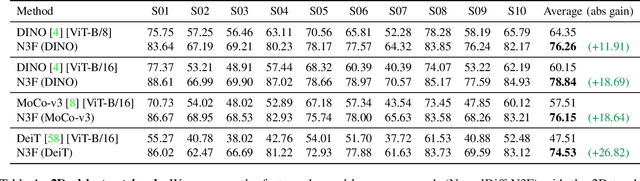
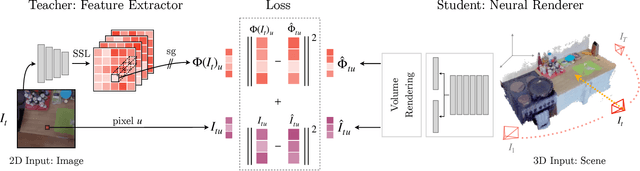

We present Neural Feature Fusion Fields (N3F), a method that improves dense 2D image feature extractors when the latter are applied to the analysis of multiple images reconstructible as a 3D scene. Given an image feature extractor, for example pre-trained using self-supervision, N3F uses it as a teacher to learn a student network defined in 3D space. The 3D student network is similar to a neural radiance field that distills said features and can be trained with the usual differentiable rendering machinery. As a consequence, N3F is readily applicable to most neural rendering formulations, including vanilla NeRF and its extensions to complex dynamic scenes. We show that our method not only enables semantic understanding in the context of scene-specific neural fields without the use of manual labels, but also consistently improves over the self-supervised 2D baselines. This is demonstrated by considering various tasks, such as 2D object retrieval, 3D segmentation, and scene editing, in diverse sequences, including long egocentric videos in the EPIC-KITCHENS benchmark.