 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyn4D: A Multiview Synthetic 4D Dataset
May 06, 2026Dense 3D reconstruction and tracking of dynamic scenes from monocular video remains an important open challenge in computer vision. Progress in this area has been constrained by the scarcity of high-quality datasets with dense, complete, and accurate geometric annotations. To address this limitation, we introduce Syn4D, a multiview synthetic dataset of dynamic scenes that includes ground-truth camera motion, depth maps, dense tracking, and parametric human pose annotations. A key feature of Syn4D is the ability to unproject any pixel into 3D to any time and to any camera. We conduct extensive evaluations across multiple downstream tasks to demonstrate the utility and effectiveness of the proposed dataset, including 4D scene reconstruction, 3D point tracking, geometry-aware camera retargeting, and human pose estimation. The experimental results highlight Syn4D's potential to facilitate research in dynamic scene understanding and spatiotemporal modeling.
AnimalClue: Recognizing Animals by their Traces
Jul 27, 2025



Wildlife observation plays an important role in biodiversity conservation, necessitating robust methodologies for monitoring wildlife populations and interspecies interactions. Recent advances in computer vision have significantly contributed to automating fundamental wildlife observation tasks, such as animal detection and species identification. However, accurately identifying species from indirect evidence like footprints and feces remains relatively underexplored, despite its importance in contributing to wildlife monitoring. To bridge this gap, we introduce AnimalClue, the first large-scale dataset for species identification from images of indirect evidence. Our dataset consists of 159,605 bounding boxes encompassing five categories of indirect clues: footprints, feces, eggs, bones, and feathers. It covers 968 species, 200 families, and 65 orders. Each image is annotated with species-level labels, bounding boxes or segmentation masks, and fine-grained trait information, including activity patterns and habitat preferences. Unlike existing datasets primarily focused on direct visual features (e.g., animal appearances), AnimalClue presents unique challenges for classification, detection, and instance segmentation tasks due to the need for recognizing more detailed and subtle visual features. In our experiments, we extensively evaluate representative vision models and identify key challenges in animal identification from their traces. Our dataset and code are available at https://dahlian00.github.io/AnimalCluePage/
AutoPartGen: Autogressive 3D Part Generation and Discovery
Jul 17, 2025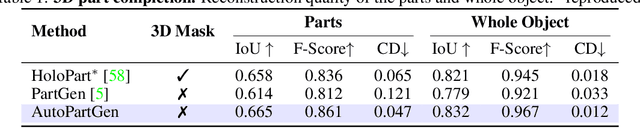
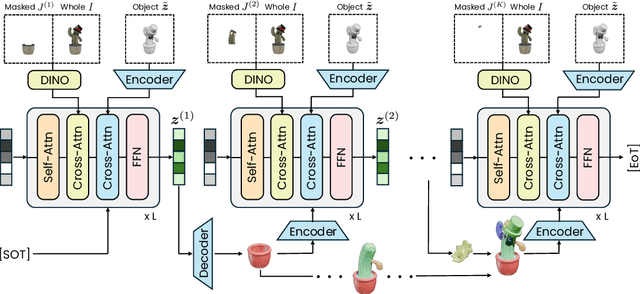

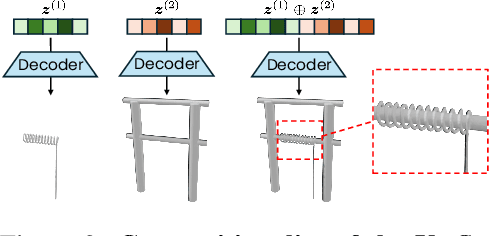
We introduce AutoPartGen, a model that generates objects composed of 3D parts in an autoregressive manner. This model can take as input an image of an object, 2D masks of the object's parts, or an existing 3D object, and generate a corresponding compositional 3D reconstruction. Our approach builds upon 3DShape2VecSet, a recent latent 3D representation with powerful geometric expressiveness. We observe that this latent space exhibits strong compositional properties, making it particularly well-suited for part-based generation tasks. Specifically, AutoPartGen generates object parts autoregressively, predicting one part at a time while conditioning on previously generated parts and additional inputs, such as 2D images, masks, or 3D objects. This process continues until the model decides that all parts have been generated, thus determining automatically the type and number of parts. The resulting parts can be seamlessly assembled into coherent objects or scenes without requiring additional optimization. We evaluate both the overall 3D generation capabilities and the part-level generation quality of AutoPartGen, demonstrating that it achieves state-of-the-art performance in 3D part generation.
Layered Motion Fusion: Lifting Motion Segmentation to 3D in Egocentric Videos
Jun 05, 2025Computer vision is largely based on 2D techniques, with 3D vision still relegated to a relatively narrow subset of applications. However, by building on recent advances in 3D models such as neural radiance fields, some authors have shown that 3D techniques can at last improve outputs extracted from independent 2D views, by fusing them into 3D and denoising them. This is particularly helpful in egocentric videos, where the camera motion is significant, but only under the assumption that the scene itself is static. In fact, as shown in the recent analysis conducted by EPIC Fields, 3D techniques are ineffective when it comes to studying dynamic phenomena, and, in particular, when segmenting moving objects. In this paper, we look into this issue in more detail. First, we propose to improve dynamic segmentation in 3D by fusing motion segmentation predictions from a 2D-based model into layered radiance fields (Layered Motion Fusion). However, the high complexity of long, dynamic videos makes it challenging to capture the underlying geometric structure, and, as a result, hinders the fusion of motion cues into the (incomplete) scene geometry. We address this issue through test-time refinement, which helps the model to focus on specific frames, thereby reducing the data complexity. This results in a synergy between motion fusion and the refinement, and in turn leads to segmentation predictions of the 3D model that surpass the 2D baseline by a large margin. This demonstrates that 3D techniques can enhance 2D analysis even for dynamic phenomena in a challenging and realistic setting.
Geo4D: Leveraging Video Generators for Geometric 4D Scene Reconstruction
Apr 10, 2025We introduce Geo4D, a method to repurpose video diffusion models for monocular 3D reconstruction of dynamic scenes. By leveraging the strong dynamic prior captured by such video models, Geo4D can be trained using only synthetic data while generalizing well to real data in a zero-shot manner. Geo4D predicts several complementary geometric modalities, namely point, depth, and ray maps. It uses a new multi-modal alignment algorithm to align and fuse these modalities, as well as multiple sliding windows, at inference time, thus obtaining robust and accurate 4D reconstruction of long videos. Extensive experiments across multiple benchmarks show that Geo4D significantly surpasses state-of-the-art video depth estimation methods, including recent methods such as MonST3R, which are also designed to handle dynamic scenes.
SynCity: Training-Free Generation of 3D Worlds
Mar 20, 2025We address the challenge of generating 3D worlds from textual descriptions. We propose SynCity, a training- and optimization-free approach, which leverages the geometric precision of pre-trained 3D generative models and the artistic versatility of 2D image generators to create large, high-quality 3D spaces. While most 3D generative models are object-centric and cannot generate large-scale worlds, we show how 3D and 2D generators can be combined to generate ever-expanding scenes. Through a tile-based approach, we allow fine-grained control over the layout and the appearance of scenes. The world is generated tile-by-tile, and each new tile is generated within its world-context and then fused with the scene. SynCity generates compelling and immersive scenes that are rich in detail and diversity.
Learning segmentation from point trajectories
Jan 21, 2025We consider the problem of segmenting objects in videos based on their motion and no other forms of supervision. Prior work has often approached this problem by using the principle of common fate, namely the fact that the motion of points that belong to the same object is strongly correlated. However, most authors have only considered instantaneous motion from optical flow. In this work, we present a way to train a segmentation network using long-term point trajectories as a supervisory signal to complement optical flow. The key difficulty is that long-term motion, unlike instantaneous motion, is difficult to model -- any parametric approximation is unlikely to capture complex motion patterns over long periods of time. We instead draw inspiration from subspace clustering approaches, proposing a loss function that seeks to group the trajectories into low-rank matrices where the motion of object points can be approximately explained as a linear combination of other point tracks. Our method outperforms the prior art on motion-based segmentation, which shows the utility of long-term motion and the effectiveness of our formulation.
PartGen: Part-level 3D Generation and Reconstruction with Multi-View Diffusion Models
Dec 24, 2024



Text- or image-to-3D generators and 3D scanners can now produce 3D assets with high-quality shapes and textures. These assets typically consist of a single, fused representation, like an implicit neural field, a Gaussian mixture, or a mesh, without any useful structure. However, most applications and creative workflows require assets to be made of several meaningful parts that can be manipulated independently. To address this gap, we introduce PartGen, a novel approach that generates 3D objects composed of meaningful parts starting from text, an image, or an unstructured 3D object. First, given multiple views of a 3D object, generated or rendered, a multi-view diffusion model extracts a set of plausible and view-consistent part segmentations, dividing the object into parts. Then, a second multi-view diffusion model takes each part separately, fills in the occlusions, and uses those completed views for 3D reconstruction by feeding them to a 3D reconstruction network. This completion process considers the context of the entire object to ensure that the parts integrate cohesively. The generative completion model can make up for the information missing due to occlusions; in extreme cases, it can hallucinate entirely invisible parts based on the input 3D asset. We evaluate our method on generated and real 3D assets and show that it outperforms segmentation and part-extraction baselines by a large margin. We also showcase downstream applications such as 3D part editing.
Rethinking Image Super-Resolution from Training Data Perspectives
Sep 01, 2024
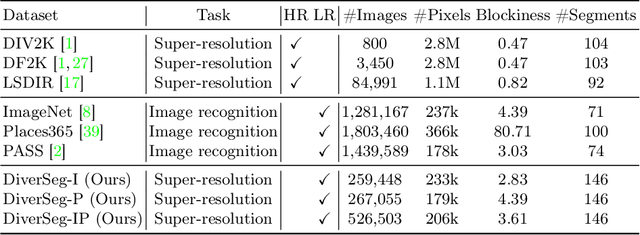

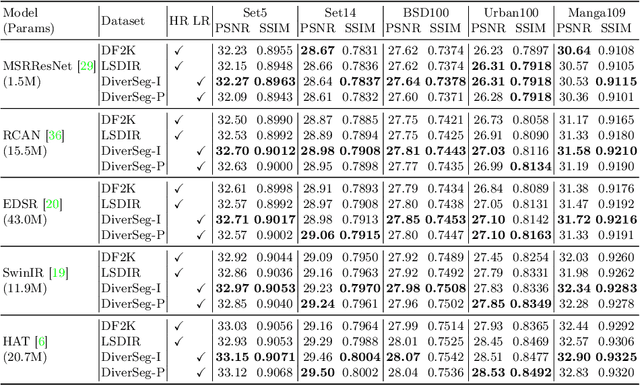
In this work, we investigate the understudied effect of the training data used for image super-resolution (SR). Most commonly, novel SR methods are developed and benchmarked on common training datasets such as DIV2K and DF2K. However, we investigate and rethink the training data from the perspectives of diversity and quality, {thereby addressing the question of ``How important is SR training for SR models?''}. To this end, we propose an automated image evaluation pipeline. With this, we stratify existing high-resolution image datasets and larger-scale image datasets such as ImageNet and PASS to compare their performances. We find that datasets with (i) low compression artifacts, (ii) high within-image diversity as judged by the number of different objects, and (iii) a large number of images from ImageNet or PASS all positively affect SR performance. We hope that the proposed simple-yet-effective dataset curation pipeline will inform the construction of SR datasets in the future and yield overall better models.
Splatt3R: Zero-shot Gaussian Splatting from Uncalibarated Image Pairs
Aug 25, 2024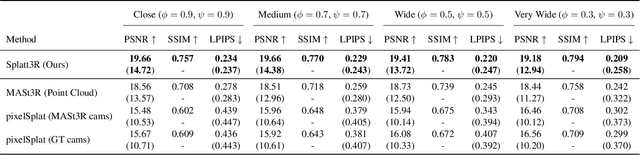
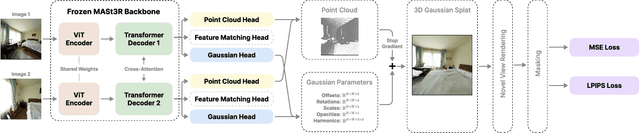
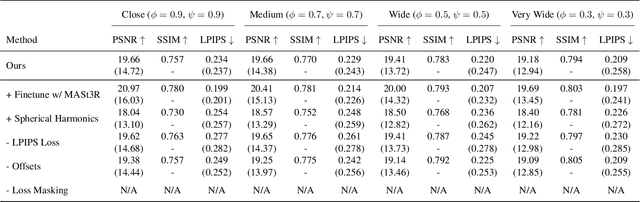
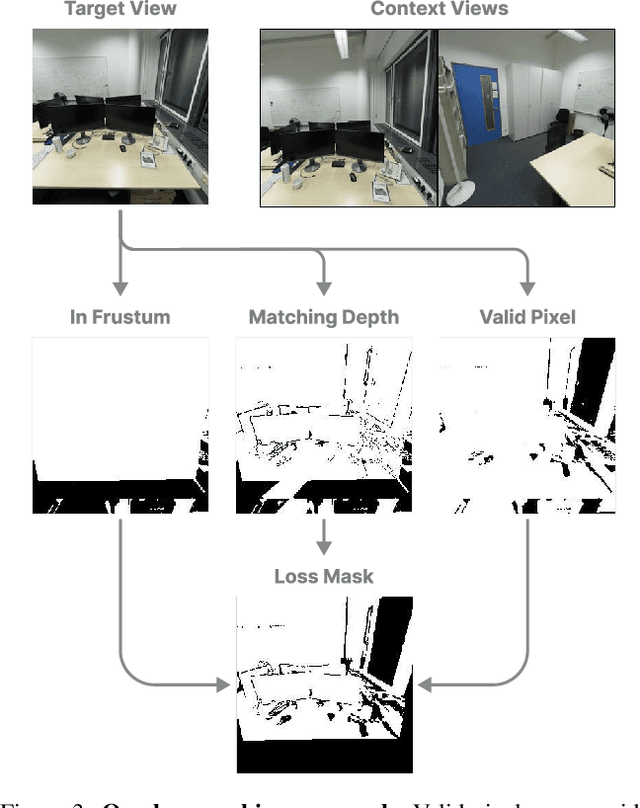
In this paper, we introduce Splatt3R, a pose-free, feed-forward method for in-the-wild 3D reconstruction and novel view synthesis from stereo pairs. Given uncalibrated natural images, Splatt3R can predict 3D Gaussian Splats without requiring any camera parameters or depth information. For generalizability, we start from a 'foundation' 3D geometry reconstruction method, MASt3R, and extend it to be a full 3D structure and appearance reconstructor. Specifically, unlike the original MASt3R which reconstructs only 3D point clouds, we predict the additional Gaussian attributes required to construct a Gaussian primitive for each point. Hence, unlike other novel view synthesis methods, Splatt3R is first trained by optimizing the 3D point cloud's geometry loss, and then a novel view synthesis objective. By doing this, we avoid the local minima present in training 3D Gaussian Splats from stereo views. We also propose a novel loss masking strategy that we empirically find is critical for strong performance on extrapolated viewpoints. We train Splatt3R on the ScanNet++ dataset and demonstrate excellent generalisation to uncalibrated, in-the-wild images. Splatt3R can reconstruct scenes at 4FPS at 512 x 512 resolution, and the resultant splats can be rendered in real-time.