 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relationship Between Double Descent of CNNs and Shape/Texture Bias Under Learning Process
Mar 04, 2025The double descent phenomenon, which deviates from the traditional bias-variance trade-off theory, attracts considerable research attention; however, the mechanism of its occurrence is not fully understood. On the other hand, in the study of convolutional neural networks (CNNs) for image recognition, methods are proposed to quantify the bias on shape features versus texture features in images, determining which features the CNN focuses on more. In this work, we hypothesize that there is a relationship between the shape/texture bias in the learning process of CNNs and epoch-wise double descent, and we conduct verification. As a result, we discover double descent/ascent of shape/texture bias synchronized with double descent of test error under conditions where epoch-wise double descent is observed. Quantitative evaluations confirm this correlation between the test errors and the bias values from the initial decrease to the full increase in test error. Interestingly, double descent/ascent of shape/texture bias is observed in some cases even in conditions without label noise, where double descent is thought not to occur. These experimental results are considered to contribute to the understanding of the mechanisms behind the double descent phenomenon and the learning process of CNNs in image recognition.
Scaling Backwards: Minimal Synthetic Pre-training?
Aug 03, 2024
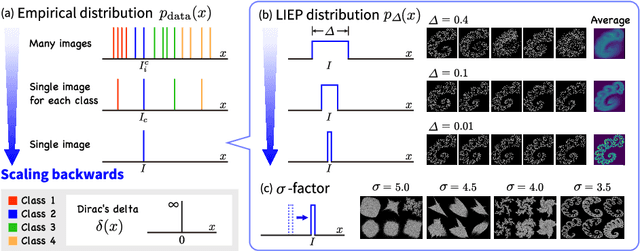

Pre-training and transfer learning are an important building block of current computer vision systems. While pre-training is usually performed on large real-world image datasets, in this paper we ask whether this is truly necessary. To this end, we search for a minimal, purely synthetic pre-training dataset that allows us to achieve performance similar to the 1 million images of ImageNet-1k. We construct such a dataset from a single fractal with perturbations. With this, we contribute three main findings. (i) We show that pre-training is effective even with minimal synthetic images, with performance on par with large-scale pre-training datasets like ImageNet-1k for full fine-tuning. (ii) We investigate the single parameter with which we construct artificial categories for our dataset. We find that while the shape differences can be indistinguishable to humans, they are crucial for obtaining strong performances. (iii) Finally, we investigate the minimal requirements for successful pre-training. Surprisingly, we find that a substantial reduction of synthetic images from 1k to 1 can even lead to an increase in pre-training performance, a motivation to further investigate ''scaling backwards''. Finally, we extend our method from synthetic images to real images to see if a single real image can show similar pre-training effect through shape augmentation. We find that the use of grayscale images and affine transformations allows even real images to ''scale backwards''.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Primitive Geometry Segment Pre-training for 3D Medical Image Segmentation
Jan 08, 2024



The construction of 3D medical image datasets presents several issues, including requiring significant financial costs in data collection and specialized expertise for annotation, as well as strict privacy concerns for patient confidentiality compared to natural image datasets. Therefore, it has become a pressing issue in 3D medical image segmentation to enable data-efficient learning with limited 3D medical data and supervision. A promising approach is pre-training, but improving its performance in 3D medical image segmentation is difficult due to the small size of existing 3D medical image datasets. We thus present the Primitive Geometry Segment Pre-training (PrimGeoSeg) method to enable the learning of 3D semantic features by pre-training segmentation tasks using only primitive geometric objects for 3D medical image segmentation. PrimGeoSeg performs more accurate and efficient 3D medical image segmentation without manual data collection and annotation. Further, experimental results show that PrimGeoSeg on SwinUNETR improves performance over learning from scratch on BTCV, MSD (Task06), and BraTS datasets by 3.7%, 4.4%, and 0.3%, respectively. Remarkably, the performance was equal to or better than state-of-the-art self-supervised learning despite the equal number of pre-training data. From experimental results, we conclude that effective pre-training can be achieved by looking at primitive geometric objects only. Code and dataset are available at https://github.com/SUPER-TADORY/PrimGeoSeg.
Traffic Incident Database with Multiple Labels Including Various Perspective Environmental Information
Dec 19, 2023



A large dataset of annotated traffic accidents is necessary to improve the accuracy of traffic accident recognition using deep learning models. Conventional traffic accident datasets provide annotations on traffic accidents and other teacher labels, improving traffic accident recognition performance. However, the labels annotated in conventional datasets need to be more comprehensive to describe traffic accidents in detail. Therefore, we propose V-TIDB, a large-scale traffic accident recognition dataset annotated with various environmental information as multi-labels. Our proposed dataset aims to improve the performance of traffic accident recognition by annotating ten types of environmental information as teacher labels in addition to the presence or absence of traffic accidents. V-TIDB is constructed by collecting many videos from the Internet and annotating them with appropriate environmental information. In our experiments, we compare the performance of traffic accident recognition when only labels related to the presence or absence of traffic accidents are trained and when environmental information is added as a multi-label. In the second experiment, we compare the performance of the training with only contact level, which represents the severity of the traffic accident, and the performance with environmental information added as a multi-label. The results showed that 6 out of 10 environmental information labels improved the performance of recognizing the presence or absence of traffic accidents. In the experiment on the degree of recognition of traffic accidents, the performance of recognition of car wrecks and contacts was improved for all environmental information. These experiments show that V-TIDB can be used to learn traffic accident recognition models that take environmental information into account in detail and can be used for appropriate traffic accident analysis.
Pre-training Vision Transformers with Very Limited Synthesized Images
Jul 31, 2023



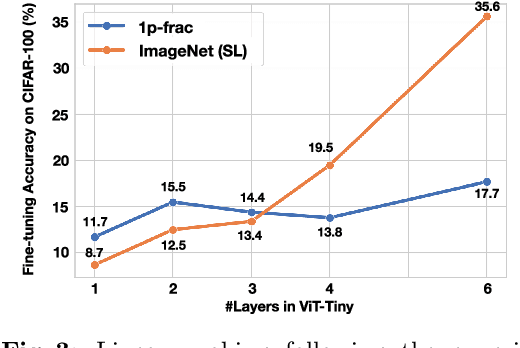
Formula-driven supervised learning (FDSL) is a pre-training method that relies on synthetic images generated from mathematical formulae such as fractals. Prior work on FDSL has shown that pre-training vision transformers on such synthetic datasets can yield competitive accuracy on a wide range of downstream tasks. These synthetic images are categorized according to the parameters in the mathematical formula that generate them. In the present work, we hypothesize that the process for generating different instances for the same category in FDSL, can be viewed as a form of data augmentation. We validate this hypothesis by replacing the instances with data augmentation, which means we only need a single image per category. Our experiments shows that this one-instance fractal database (OFDB) performs better than the original dataset where instances were explicitly generated. We further scale up OFDB to 21,000 categories and show that it matches, or even surpasses, the model pre-trained on ImageNet-21k in ImageNet-1k fine-tuning. The number of images in OFDB is 21k, whereas ImageNet-21k has 14M. This opens new possibilities for pre-training vision transformers with much smaller datasets.
mdx: A Cloud Platform for Supporting Data Science and Cross-Disciplinary Research Collaborations
Mar 27, 2022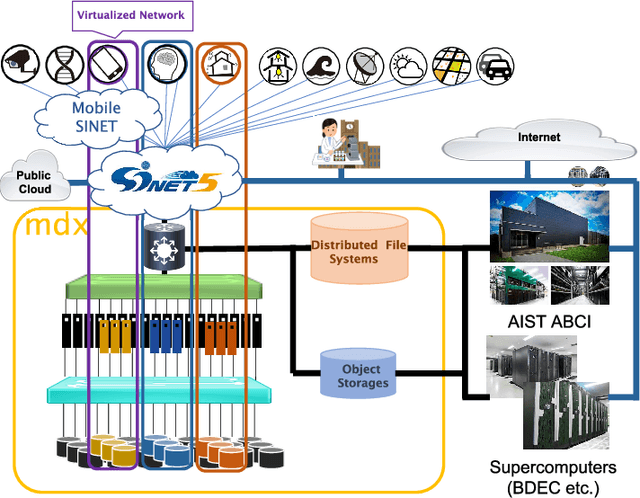
The growing amount of data and advances in data science have created a need for a new kind of cloud platform that provides users with flexibility, strong security, and the ability to couple with supercomputers and edge devices through high-performance networks. We have built such a nation-wide cloud platform, called "mdx" to meet this need. The mdx platform's virtualization service, jointly operated by 9 national universities and 2 national research institutes in Japan, launched in 2021, and more features are in development. Currently mdx is used by researchers in a wide variety of domains, including materials informatics, geo-spatial information science, life science, astronomical science, economics, social science, and computer science. This paper provides an the overview of the mdx platform, details the motivation for its development, reports its current status, and outlines its future plans.
Classifying DNS Servers based on Response Message Matrix using Machine Learning
Nov 09, 2021


Improperly configured domain name system (DNS) servers are sometimes used as packet reflectors as part of a DoS or DDoS attack. Detecting packets created as a result of this activity is logically possible by monitoring the DNS request and response traffic. Any response that does not have a corresponding request can be considered a reflected message; checking and tracking every DNS packet, however, is a non-trivial operation. In this paper, we propose a detection mechanism for DNS servers used as reflectors by using a DNS server feature matrix built from a small number of packets and a machine learning algorithm. The F1 score of bad DNS server detection was more than 0.9 when the test and training data are generated within the same day, and more than 0.7 for the data not used for the training and testing phase of the same day.
Another Diversity-Promoting Objective Function for Neural Dialogue Generation
Nov 21, 2018



Although generation-based dialogue systems have been widely researched, the response generations by most existing systems have very low diversities. The most likely reason for this problem is Maximum Likelihood Estimation (MLE) with Softmax Cross-Entropy (SCE) loss. MLE trains models to generate the most frequent responses from enormous generation candidates, although in actual dialogues there are various responses based on the context. In this paper, we propose a new objective function called Inverse Token Frequency (ITF) loss, which individually scales smaller loss for frequent token classes and larger loss for rare token classes. This function encourages the model to generate rare tokens rather than frequent tokens. It does not complicate the model and its training is stable because we only replace the objective function. On the OpenSubtitles dialogue dataset, our loss model establishes a state-of-the-art DIST-1 of 7.56, which is the unigram diversity score, while maintaining a good BLEU-1 score. On a Japanese Twitter replies dataset, our loss model achieves a DIST-1 score comparable to the ground truth.