 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Latency Real-Time Audio Game Commentary System via LLM-Based Parallel Text Generation
Jun 11, 2026We present a low-latency real-time audio game commentary system that generates spoken commentary directly from live gameplay video. In this end-to-end setting, a key bottleneck is accumulated waiting time; conventional pipelines capture frames, generate text, and synthesize speech sequentially for each utterance, and do not request the next generation until speech playback has completed. This strict sequentiality causes long and unnatural silence between utterances. To address this latency bottleneck, our system runs text generation in parallel with speech playback and buffers multiple candidate utterances ahead of time, enabling immediate synthesis at playback boundaries. Experiments on fast-paced game videos show that our parallel design reduces the mean inter-utterance silence from 9.6 seconds to 0.3 seconds compared to sequential baselines. It also improves similarity to professional speaking--silence timing patterns by over 40 %, and a user study with 120 experienced game players confirms significantly improved perceived speaking rhythm. Our demo video is available at: https://youtu.be/pmrRUlvav8M.
Top-down string-to-dependency Neural Machine Translation
Mar 30, 2026Most of modern neural machine translation (NMT) models are based on an encoder-decoder framework with an attention mechanism. While they perform well on standard datasets, they can have trouble in translation of long inputs that are rare or unseen during training. Incorporating target syntax is one approach to dealing with such length-related problems. We propose a novel syntactic decoder that generates a target-language dependency tree in a top-down, left-to-right order. Experiments show that the proposed top-down string-to-tree decoding generalizes better than conventional sequence-to-sequence decoding in translating long inputs that are not observed in the training data.
Real-Time Generation of Game Video Commentary with Multimodal LLMs: Pause-Aware Decoding Approaches
Mar 03, 2026Real-time video commentary generation provides textual descriptions of ongoing events in videos. It supports accessibility and engagement in domains such as sports, esports, and livestreaming. Commentary generation involves two essential decisions: what to say and when to say it. While recent prompting-based approaches using multimodal large language models (MLLMs) have shown strong performance in content generation, they largely ignore the timing aspect. We investigate whether in-context prompting alone can support real-time commentary generation that is both semantically relevant and well-timed. We propose two prompting-based decoding strategies: 1) a fixed-interval approach, and 2) a novel dynamic interval-based decoding approach that adjusts the next prediction timing based on the estimated duration of the previous utterance. Both methods enable pause-aware generation without any fine-tuning. Experiments on Japanese and English datasets of racing and fighting games show that the dynamic interval-based decoding can generate commentary more closely aligned with human utterance timing and content using prompting alone. We release a multilingual benchmark dataset, trained models, and implementations to support future research on real-time video commentary generation.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
A Word Order Synchronization Metric for Evaluating Simultaneous Interpretation and Translation
Jul 09, 2024



Simultaneous interpretation (SI), the translation of one language to another in real time, starts translation before the original speech has finished. Its evaluation needs to consider both latency and quality. This trade-off is challenging especially for distant word order language pairs such as English and Japanese. To handle this word order gap, interpreters maintain the word order of the source language as much as possible to keep up with original language to minimize its latency while maintaining its quality, whereas in translation reordering happens to keep fluency in the target language. This means outputs synchronized with the source language are desirable based on the real SI situation, and it's a key for further progress in computational SI and simultaneous machine translation (SiMT). In this work, we propose an automatic evaluation metric for SI and SiMT focusing on word order synchronization. Our evaluation metric is based on rank correlation coefficients, leveraging cross-lingual pre-trained language models. Our experimental results on NAIST-SIC-Aligned and JNPC showed our metrics' effectiveness to measure word order synchronization between source and target language.
NAIST Simultaneous Speech Translation System for IWSLT 2024
Jun 30, 2024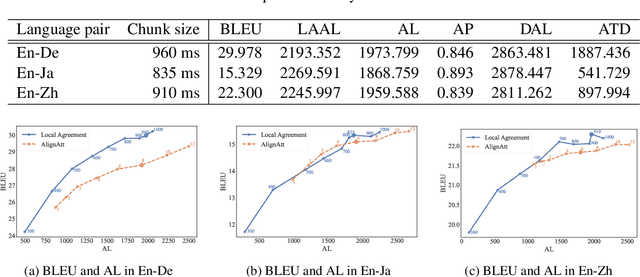
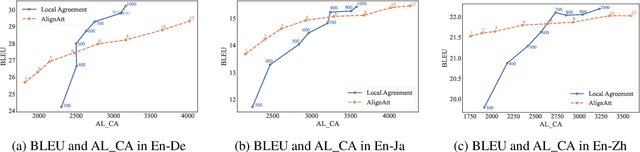


This paper describes NAIST's submission to the simultaneous track of the IWSLT 2024 Evaluation Campaign: English-to-{German, Japanese, Chinese} speech-to-text translation and English-to-Japanese speech-to-speech translation. We develop a multilingual end-to-end speech-to-text translation model combining two pre-trained language models, HuBERT and mBART. We trained this model with two decoding policies, Local Agreement (LA) and AlignAtt. The submitted models employ the LA policy because it outperformed the AlignAtt policy in previous models. Our speech-to-speech translation method is a cascade of the above speech-to-text model and an incremental text-to-speech (TTS) module that incorporates a phoneme estimation model, a parallel acoustic model, and a parallel WaveGAN vocoder. We improved our incremental TTS by applying the Transformer architecture with the AlignAtt policy for the estimation model. The results show that our upgraded TTS module contributed to improving the system performance.
LLMs Are Zero-Shot Context-Aware Simultaneous Translators
Jun 19, 2024



The advent of transformers has fueled progress in machine translation. More recently large language models (LLMs) have come to the spotlight thanks to their generality and strong performance in a wide range of language tasks, including translation. Here we show that open-source LLMs perform on par with or better than some state-of-the-art baselines in simultaneous machine translation (SiMT) tasks, zero-shot. We also demonstrate that injection of minimal background information, which is easy with an LLM, brings further performance gains, especially on challenging technical subject-matter. This highlights LLMs' potential for building next generation of massively multilingual, context-aware and terminologically accurate SiMT systems that require no resource-intensive training or fine-tuning.
Automated Essay Scoring Using Grammatical Variety and Errors with Multi-Task Learning and Item Response Theory
Jun 13, 2024


This study examines the effect of grammatical features in automatic essay scoring (AES). We use two kinds of grammatical features as input to an AES model: (1) grammatical items that writers used correctly in essays, and (2) the number of grammatical errors. Experimental results show that grammatical features improve the performance of AES models that predict the holistic scores of essays. Multi-task learning with the holistic and grammar scores, alongside using grammatical features, resulted in a larger improvement in model performance. We also show that a model using grammar abilities estimated using Item Response Theory (IRT) as the labels for the auxiliary task achieved comparable performance to when we used grammar scores assigned by human raters. In addition, we weight the grammatical features using IRT to consider the difficulty of grammatical items and writers' grammar abilities. We found that weighting grammatical features with the difficulty led to further improvement in performance.
Word Order in English-Japanese Simultaneous Interpretation: Analyses and Evaluation using Chunk-wise Monotonic Translation
Jun 13, 2024
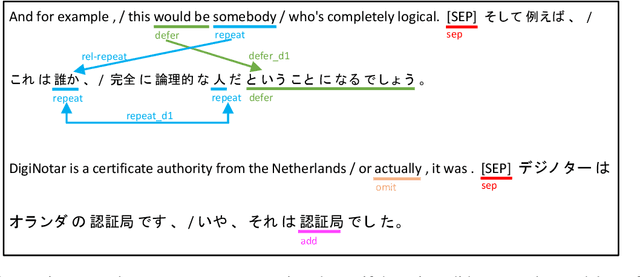
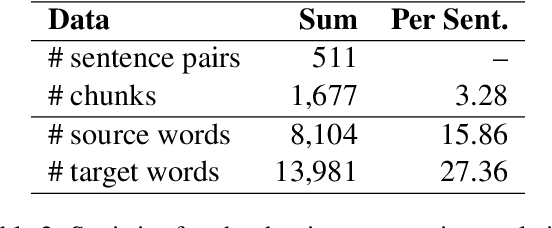

This paper analyzes the features of monotonic translations, which follow the word order of the source language, in simultaneous interpreting (SI). The word order differences are one of the biggest challenges in SI, especially for language pairs with significant structural differences like English and Japanese. We analyzed the characteristics of monotonic translations using the NAIST English-to-Japanese Chunk-wise Monotonic Translation Evaluation Dataset and found some grammatical structures that make monotonic translation difficult in English-Japanese SI. We further investigated the features of monotonic translations through evaluating the output from the existing speech translation (ST) and simultaneous speech translation (simulST) models on NAIST English-to-Japanese Chunk-wise Monotonic Translation Evaluation Dataset as well as on existing test sets. The results suggest that the existing SI-based test set underestimates the model performance. We also found that the monotonic-translation-based dataset would better evaluate simulST models, while using an offline-based test set for evaluating simulST models underestimates the model performance.
Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Jun 06, 2024
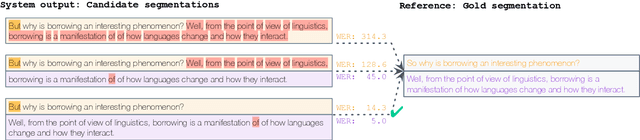

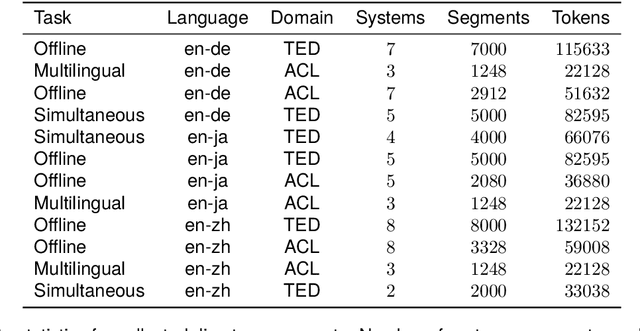
Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.
* LREC-COLING2024 publication (with corrections for Table 3)