 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAIST Simultaneous Speech Translation System for IWSLT 2024
Jun 30, 2024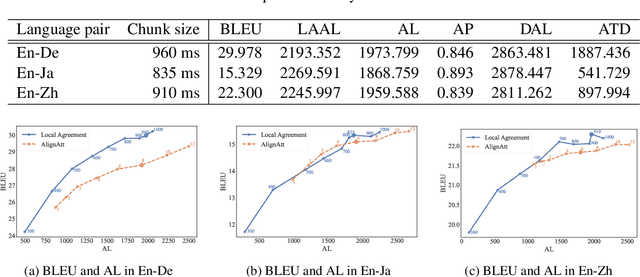
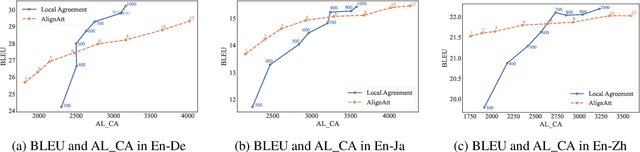


This paper describes NAIST's submission to the simultaneous track of the IWSLT 2024 Evaluation Campaign: English-to-{German, Japanese, Chinese} speech-to-text translation and English-to-Japanese speech-to-speech translation. We develop a multilingual end-to-end speech-to-text translation model combining two pre-trained language models, HuBERT and mBART. We trained this model with two decoding policies, Local Agreement (LA) and AlignAtt. The submitted models employ the LA policy because it outperformed the AlignAtt policy in previous models. Our speech-to-speech translation method is a cascade of the above speech-to-text model and an incremental text-to-speech (TTS) module that incorporates a phoneme estimation model, a parallel acoustic model, and a parallel WaveGAN vocoder. We improved our incremental TTS by applying the Transformer architecture with the AlignAtt policy for the estimation model. The results show that our upgraded TTS module contributed to improving the system performance.
Tagged End-to-End Simultaneous Speech Translation Training using Simultaneous Interpretation Data
Jun 14, 2023



Simultaneous speech translation (SimulST) translates partial speech inputs incrementally. Although the monotonic correspondence between input and output is preferable for smaller latency, it is not the case for distant language pairs such as English and Japanese. A prospective approach to this problem is to mimic simultaneous interpretation (SI) using SI data to train a SimulST model. However, the size of such SI data is limited, so the SI data should be used together with ordinary bilingual data whose translations are given in offline. In this paper, we propose an effective way to train a SimulST model using mixed data of SI and offline. The proposed method trains a single model using the mixed data with style tags that tell the model to generate SI- or offline-style outputs. Experiment results show improvements of BLEURT in different latency ranges, and our analyses revealed the proposed model generates SI-style outputs more than the baseline.
Improving Speech Translation Accuracy and Time Efficiency with Fine-tuned wav2vec 2.0-based Speech Segmentation
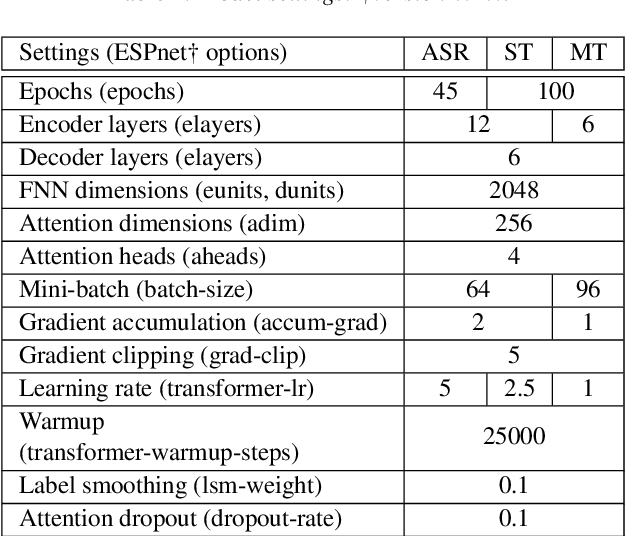
Apr 25, 2023Speech translation (ST) automatically converts utterances in a source language into text in another language. Splitting continuous speech into shorter segments, known as speech segmentation, plays an important role in ST. Recent segmentation methods trained to mimic the segmentation of ST corpora have surpassed traditional approaches. Tsiamas et al. proposed a segmentation frame classifier (SFC) based on a pre-trained speech encoder called wav2vec 2.0. Their method, named SHAS, retains 95-98% of the BLEU score for ST corpus segmentation. However, the segments generated by SHAS are very different from ST corpus segmentation and tend to be longer with multiple combined utterances. This is due to SHAS's reliance on length heuristics, i.e., it splits speech into segments of easily translatable length without fully considering the potential for ST improvement by splitting them into even shorter segments. Longer segments often degrade translation quality and ST's time efficiency. In this study, we extended SHAS to improve ST translation accuracy and efficiency by splitting speech into shorter segments that correspond to sentences. We introduced a simple segmentation algorithm using the moving average of SFC predictions without relying on length heuristics and explored wav2vec 2.0 fine-tuning for improved speech segmentation prediction. Our experimental results reveal that our speech segmentation method significantly improved the quality and the time efficiency of speech translation compared to SHAS.
NAIST-SIC-Aligned: Automatically-Aligned English-Japanese Simultaneous Interpretation Corpus
Apr 25, 2023

It remains a question that how simultaneous interpretation (SI) data affects simultaneous machine translation (SiMT). Research has been limited due to the lack of a large-scale training corpus. In this work, we aim to fill in the gap by introducing NAIST-SIC-Aligned, which is an automatically-aligned parallel English-Japanese SI dataset. Starting with a non-aligned corpus NAIST-SIC, we propose a two-stage alignment approach to make the corpus parallel and thus suitable for model training. The first stage is coarse alignment where we perform a many-to-many mapping between source and target sentences, and the second stage is fine-grained alignment where we perform intra- and inter-sentence filtering to improve the quality of aligned pairs. To ensure the quality of the corpus, each step has been validated either quantitatively or qualitatively. This is the first open-sourced large-scale parallel SI dataset in the literature. We also manually curated a small test set for evaluation purposes. We hope our work advances research on SI corpora construction and SiMT. Please find our data at \url{https://github.com/mingzi151/AHC-SI}.
Speech Segmentation Optimization using Segmented Bilingual Speech Corpus for End-to-end Speech Translation
Mar 29, 2022
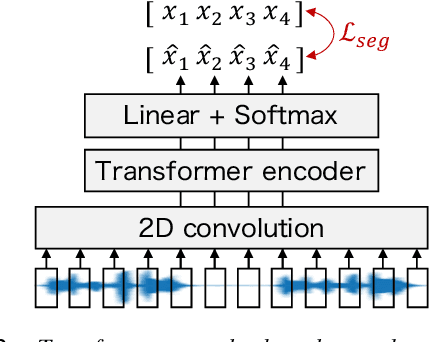
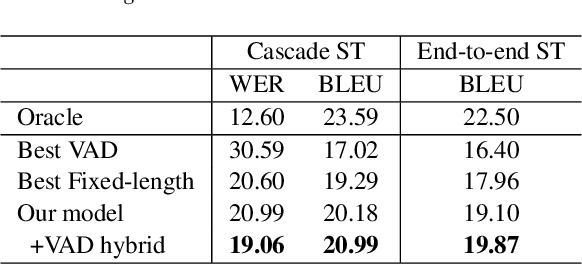
Speech segmentation, which splits long speech into short segments, is essential for speech translation (ST). Popular VAD tools like WebRTC VAD have generally relied on pause-based segmentation. Unfortunately, pauses in speech do not necessarily match sentence boundaries, and sentences can be connected by a very short pause that is difficult to detect by VAD. In this study, we propose a speech segmentation method using a binary classification model trained using a segmented bilingual speech corpus. We also propose a hybrid method that combines VAD and the above speech segmentation method. Experimental results revealed that the proposed method is more suitable for cascade and end-to-end ST systems than conventional segmentation methods. The hybrid approach further improved the translation performance.