 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAIST Simultaneous Speech Translation System for IWSLT 2024
Jun 30, 2024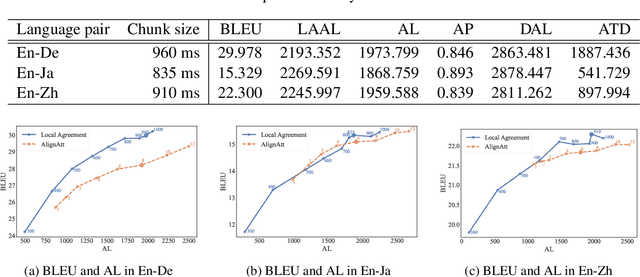
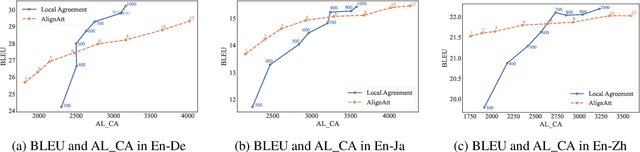


This paper describes NAIST's submission to the simultaneous track of the IWSLT 2024 Evaluation Campaign: English-to-{German, Japanese, Chinese} speech-to-text translation and English-to-Japanese speech-to-speech translation. We develop a multilingual end-to-end speech-to-text translation model combining two pre-trained language models, HuBERT and mBART. We trained this model with two decoding policies, Local Agreement (LA) and AlignAtt. The submitted models employ the LA policy because it outperformed the AlignAtt policy in previous models. Our speech-to-speech translation method is a cascade of the above speech-to-text model and an incremental text-to-speech (TTS) module that incorporates a phoneme estimation model, a parallel acoustic model, and a parallel WaveGAN vocoder. We improved our incremental TTS by applying the Transformer architecture with the AlignAtt policy for the estimation model. The results show that our upgraded TTS module contributed to improving the system performance.
Keep Decoding Parallel with Effective Knowledge Distillation from Language Models to End-to-end Speech Recognisers
Jan 22, 2024



This study presents a novel approach for knowledge distillation (KD) from a BERT teacher model to an automatic speech recognition (ASR) model using intermediate layers. To distil the teacher's knowledge, we use an attention decoder that learns from BERT's token probabilities. Our method shows that language model (LM) information can be more effectively distilled into an ASR model using both the intermediate layers and the final layer. By using the intermediate layers as distillation target, we can more effectively distil LM knowledge into the lower network layers. Using our method, we achieve better recognition accuracy than with shallow fusion of an external LM, allowing us to maintain fast parallel decoding. Experiments on the LibriSpeech dataset demonstrate the effectiveness of our approach in enhancing greedy decoding with connectionist temporal classification (CTC).
Tagged End-to-End Simultaneous Speech Translation Training using Simultaneous Interpretation Data
Jun 14, 2023



Simultaneous speech translation (SimulST) translates partial speech inputs incrementally. Although the monotonic correspondence between input and output is preferable for smaller latency, it is not the case for distant language pairs such as English and Japanese. A prospective approach to this problem is to mimic simultaneous interpretation (SI) using SI data to train a SimulST model. However, the size of such SI data is limited, so the SI data should be used together with ordinary bilingual data whose translations are given in offline. In this paper, we propose an effective way to train a SimulST model using mixed data of SI and offline. The proposed method trains a single model using the mixed data with style tags that tell the model to generate SI- or offline-style outputs. Experiment results show improvements of BLEURT in different latency ranges, and our analyses revealed the proposed model generates SI-style outputs more than the baseline.
Inter-connection: Effective Connection between Pre-trained Encoder and Decoder for Speech Translation
May 26, 2023In end-to-end speech translation, speech and text pre-trained models improve translation quality. Recently proposed models simply connect the pre-trained models of speech and text as encoder and decoder. Therefore, only the information from the final layer of encoders is input to the decoder. Since it is clear that the speech pre-trained model outputs different information from each layer, the simple connection method cannot fully utilize the information that the speech pre-trained model has. In this study, we propose an inter-connection mechanism that aggregates the information from each layer of the speech pre-trained model by weighted sums and inputs into the decoder. This mechanism increased BLEU by approximately 2 points in en-de, en-ja, and en-zh by increasing parameters by 2K when the speech pre-trained model was frozen. Furthermore, we investigated the contribution of each layer for each language by visualizing layer weights and found that the contributions were different.