 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Japanese Speech Recognition on ASR-LLM Setups with Multi-Pass Augmented Generative Error Correction
Aug 29, 2024



With the strong representational power of large language models (LLMs), generative error correction (GER) for automatic speech recognition (ASR) aims to provide semantic and phonetic refinements to address ASR errors. This work explores how LLM-based GER can enhance and expand the capabilities of Japanese language processing, presenting the first GER benchmark for Japanese ASR with 0.9-2.6k text utterances. We also introduce a new multi-pass augmented generative error correction (MPA GER) by integrating multiple system hypotheses on the input side with corrections from multiple LLMs on the output side and then merging them. To the best of our knowledge, this is the first investigation of the use of LLMs for Japanese GER, which involves second-pass language modeling on the output transcriptions generated by the ASR system (e.g., N-best hypotheses). Our experiments demonstrated performance improvement in the proposed methods of ASR quality and generalization both in SPREDS-U1-ja and CSJ data.
NAIST Simultaneous Speech Translation System for IWSLT 2024
Jun 30, 2024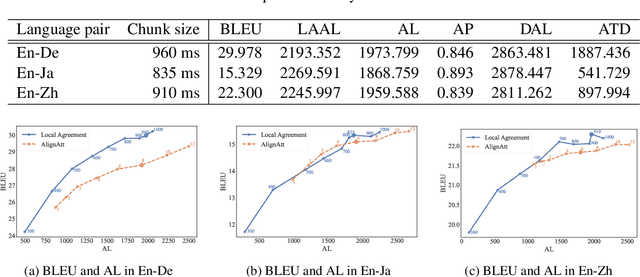
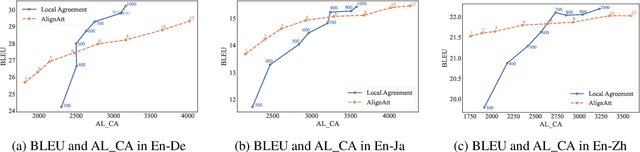


This paper describes NAIST's submission to the simultaneous track of the IWSLT 2024 Evaluation Campaign: English-to-{German, Japanese, Chinese} speech-to-text translation and English-to-Japanese speech-to-speech translation. We develop a multilingual end-to-end speech-to-text translation model combining two pre-trained language models, HuBERT and mBART. We trained this model with two decoding policies, Local Agreement (LA) and AlignAtt. The submitted models employ the LA policy because it outperformed the AlignAtt policy in previous models. Our speech-to-speech translation method is a cascade of the above speech-to-text model and an incremental text-to-speech (TTS) module that incorporates a phoneme estimation model, a parallel acoustic model, and a parallel WaveGAN vocoder. We improved our incremental TTS by applying the Transformer architecture with the AlignAtt policy for the estimation model. The results show that our upgraded TTS module contributed to improving the system performance.
Word Order in English-Japanese Simultaneous Interpretation: Analyses and Evaluation using Chunk-wise Monotonic Translation
Jun 13, 2024
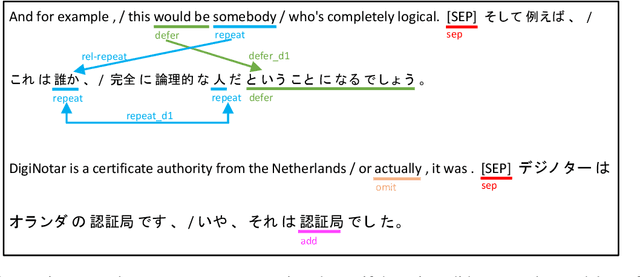
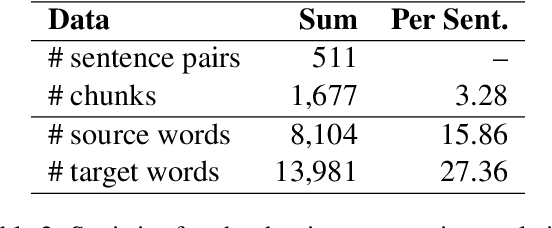

This paper analyzes the features of monotonic translations, which follow the word order of the source language, in simultaneous interpreting (SI). The word order differences are one of the biggest challenges in SI, especially for language pairs with significant structural differences like English and Japanese. We analyzed the characteristics of monotonic translations using the NAIST English-to-Japanese Chunk-wise Monotonic Translation Evaluation Dataset and found some grammatical structures that make monotonic translation difficult in English-Japanese SI. We further investigated the features of monotonic translations through evaluating the output from the existing speech translation (ST) and simultaneous speech translation (simulST) models on NAIST English-to-Japanese Chunk-wise Monotonic Translation Evaluation Dataset as well as on existing test sets. The results suggest that the existing SI-based test set underestimates the model performance. We also found that the monotonic-translation-based dataset would better evaluate simulST models, while using an offline-based test set for evaluating simulST models underestimates the model performance.
Tagged End-to-End Simultaneous Speech Translation Training using Simultaneous Interpretation Data
Jun 14, 2023



Simultaneous speech translation (SimulST) translates partial speech inputs incrementally. Although the monotonic correspondence between input and output is preferable for smaller latency, it is not the case for distant language pairs such as English and Japanese. A prospective approach to this problem is to mimic simultaneous interpretation (SI) using SI data to train a SimulST model. However, the size of such SI data is limited, so the SI data should be used together with ordinary bilingual data whose translations are given in offline. In this paper, we propose an effective way to train a SimulST model using mixed data of SI and offline. The proposed method trains a single model using the mixed data with style tags that tell the model to generate SI- or offline-style outputs. Experiment results show improvements of BLEURT in different latency ranges, and our analyses revealed the proposed model generates SI-style outputs more than the baseline.
NAIST-SIC-Aligned: Automatically-Aligned English-Japanese Simultaneous Interpretation Corpus
Apr 25, 2023It remains a question that how simultaneous interpretation (SI) data affects simultaneous machine translation (SiMT). Research has been limited due to the lack of a large-scale training corpus. In this work, we aim to fill in the gap by introducing NAIST-SIC-Aligned, which is an automatically-aligned parallel English-Japanese SI dataset. Starting with a non-aligned corpus NAIST-SIC, we propose a two-stage alignment approach to make the corpus parallel and thus suitable for model training. The first stage is coarse alignment where we perform a many-to-many mapping between source and target sentences, and the second stage is fine-grained alignment where we perform intra- and inter-sentence filtering to improve the quality of aligned pairs. To ensure the quality of the corpus, each step has been validated either quantitatively or qualitatively. This is the first open-sourced large-scale parallel SI dataset in the literature. We also manually curated a small test set for evaluation purposes. We hope our work advances research on SI corpora construction and SiMT. Please find our data at \url{https://github.com/mingzi151/AHC-SI}.