 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Order in English-Japanese Simultaneous Interpretation: Analyses and Evaluation using Chunk-wise Monotonic Translation
Paper and Code
Jun 13, 2024
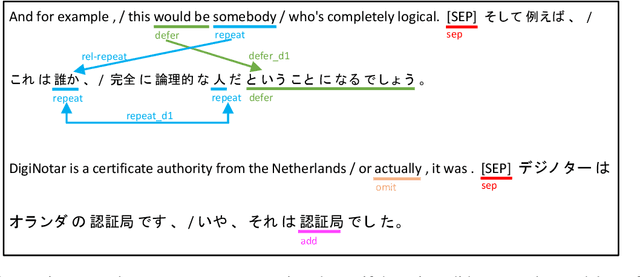
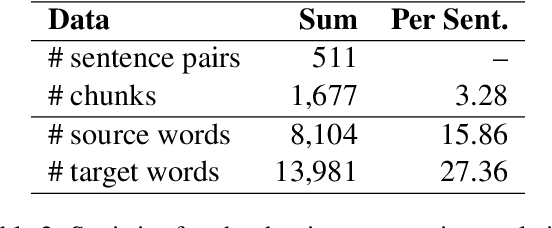

This paper analyzes the features of monotonic translations, which follow the word order of the source language, in simultaneous interpreting (SI). The word order differences are one of the biggest challenges in SI, especially for language pairs with significant structural differences like English and Japanese. We analyzed the characteristics of monotonic translations using the NAIST English-to-Japanese Chunk-wise Monotonic Translation Evaluation Dataset and found some grammatical structures that make monotonic translation difficult in English-Japanese SI. We further investigated the features of monotonic translations through evaluating the output from the existing speech translation (ST) and simultaneous speech translation (simulST) models on NAIST English-to-Japanese Chunk-wise Monotonic Translation Evaluation Dataset as well as on existing test sets. The results suggest that the existing SI-based test set underestimates the model performance. We also found that the monotonic-translation-based dataset would better evaluate simulST models, while using an offline-based test set for evaluating simulST models underestimates the model performance.