 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Word Order Synchronization Metric for Evaluating Simultaneous Interpretation and Translation
Jul 09, 2024



Simultaneous interpretation (SI), the translation of one language to another in real time, starts translation before the original speech has finished. Its evaluation needs to consider both latency and quality. This trade-off is challenging especially for distant word order language pairs such as English and Japanese. To handle this word order gap, interpreters maintain the word order of the source language as much as possible to keep up with original language to minimize its latency while maintaining its quality, whereas in translation reordering happens to keep fluency in the target language. This means outputs synchronized with the source language are desirable based on the real SI situation, and it's a key for further progress in computational SI and simultaneous machine translation (SiMT). In this work, we propose an automatic evaluation metric for SI and SiMT focusing on word order synchronization. Our evaluation metric is based on rank correlation coefficients, leveraging cross-lingual pre-trained language models. Our experimental results on NAIST-SIC-Aligned and JNPC showed our metrics' effectiveness to measure word order synchronization between source and target language.
NAIST Simultaneous Speech Translation System for IWSLT 2024
Jun 30, 2024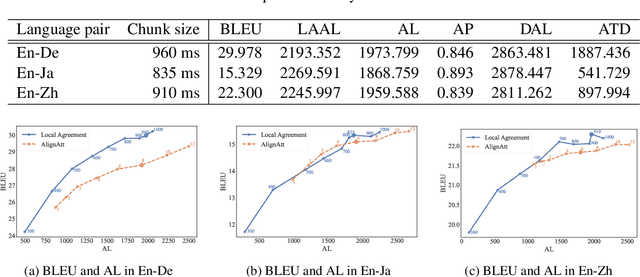
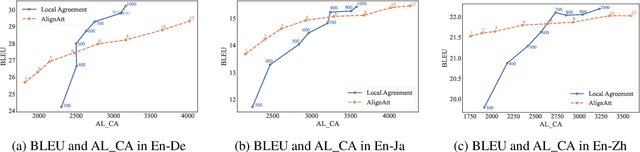


This paper describes NAIST's submission to the simultaneous track of the IWSLT 2024 Evaluation Campaign: English-to-{German, Japanese, Chinese} speech-to-text translation and English-to-Japanese speech-to-speech translation. We develop a multilingual end-to-end speech-to-text translation model combining two pre-trained language models, HuBERT and mBART. We trained this model with two decoding policies, Local Agreement (LA) and AlignAtt. The submitted models employ the LA policy because it outperformed the AlignAtt policy in previous models. Our speech-to-speech translation method is a cascade of the above speech-to-text model and an incremental text-to-speech (TTS) module that incorporates a phoneme estimation model, a parallel acoustic model, and a parallel WaveGAN vocoder. We improved our incremental TTS by applying the Transformer architecture with the AlignAtt policy for the estimation model. The results show that our upgraded TTS module contributed to improving the system performance.
Word Order in English-Japanese Simultaneous Interpretation: Analyses and Evaluation using Chunk-wise Monotonic Translation
Jun 13, 2024
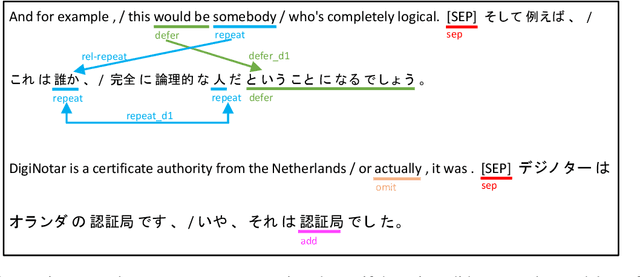
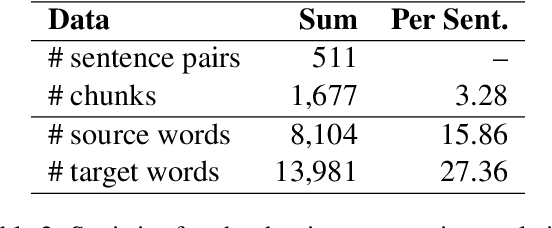

This paper analyzes the features of monotonic translations, which follow the word order of the source language, in simultaneous interpreting (SI). The word order differences are one of the biggest challenges in SI, especially for language pairs with significant structural differences like English and Japanese. We analyzed the characteristics of monotonic translations using the NAIST English-to-Japanese Chunk-wise Monotonic Translation Evaluation Dataset and found some grammatical structures that make monotonic translation difficult in English-Japanese SI. We further investigated the features of monotonic translations through evaluating the output from the existing speech translation (ST) and simultaneous speech translation (simulST) models on NAIST English-to-Japanese Chunk-wise Monotonic Translation Evaluation Dataset as well as on existing test sets. The results suggest that the existing SI-based test set underestimates the model performance. We also found that the monotonic-translation-based dataset would better evaluate simulST models, while using an offline-based test set for evaluating simulST models underestimates the model performance.
Simultaneous Interpretation Corpus Construction by Large Language Models in Distant Language Pair
Apr 18, 2024



In Simultaneous Machine Translation (SiMT) systems, training with a simultaneous interpretation (SI) corpus is an effective method for achieving high-quality yet low-latency systems. However, it is very challenging to curate such a corpus due to limitations in the abilities of annotators, and hence, existing SI corpora are limited. Therefore, we propose a method to convert existing speech translation corpora into interpretation-style data, maintaining the original word order and preserving the entire source content using Large Language Models (LLM-SI-Corpus). We demonstrate that fine-tuning SiMT models in text-to-text and speech-to-text settings with the LLM-SI-Corpus reduces latencies while maintaining the same level of quality as the models trained with offline datasets. The LLM-SI-Corpus is available at \url{https://github.com/yusuke1997/LLM-SI-Corpus}.