 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulSense: Sense-Driven Interpreting for Efficient Simultaneous Speech Translation
Sep 26, 2025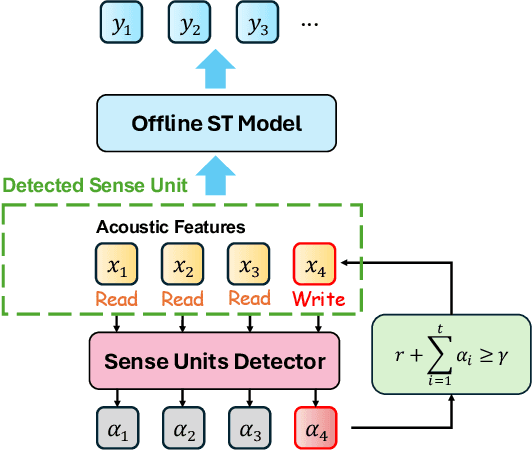

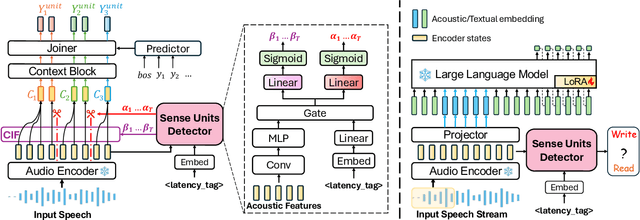
How to make human-interpreter-like read/write decisions for simultaneous speech translation (SimulST) systems? Current state-of-the-art systems formulate SimulST as a multi-turn dialogue task, requiring specialized interleaved training data and relying on computationally expensive large language model (LLM) inference for decision-making. In this paper, we propose SimulSense, a novel framework for SimulST that mimics human interpreters by continuously reading input speech and triggering write decisions to produce translation when a new sense unit is perceived. Experiments against two state-of-the-art baseline systems demonstrate that our proposed method achieves a superior quality-latency tradeoff and substantially improved real-time efficiency, where its decision-making is up to 9.6x faster than the baselines.
A High-Speed Time-Optimal Trajectory Generation Strategy via a Two-layer Planning Model
Mar 14, 2025Motion planning and trajectory generation are crucial technologies in various domains including the control of Unmanned Aerial Vehicles (UAV), manipulators, and rockets. However, optimization-based real-time motion planning becomes increasingly challenging due to the problem's probable non-convexity and the inherent limitations of Non-Linear Programming algorithms. Highly nonlinear dynamics, obstacle avoidance constraints, and non-convex inputs can exacerbate these difficulties. To address these hurdles, this paper proposes a two-layer optimization algorithm for 2D vehicles by dynamically reformulating small time horizon convex programming subproblems, aiming to provide real-time guarantees for trajectory optimization. Our approach involves breaking down the original problem into small horizon-based planning cycles with fixed final times, referred to as planning cycles. Each planning cycle is then solved within a series of restricted convex sets identified by our customized search algorithms incrementally. The key benefits of our proposed algorithm include fast computation speeds and lower task time. We demonstrate these advantages through mathematical proofs under some moderate preconditions and experimental results.
Contrastive Feedback Mechanism for Simultaneous Speech Translation
Jul 31, 2024Recent advances in simultaneous speech translation (SST) focus on the decision policies that enable the use of offline-trained ST models for simultaneous inference. These decision policies not only control the quality-latency trade-off in SST but also mitigate the impact of unstable predictions on translation quality by delaying translation for more context or discarding these predictions through stable hypothesis detection. However, these policies often overlook the potential benefits of utilizing unstable predictions. We introduce the contrastive feedback mechanism (CFM) for SST, a novel method that leverages these unstable predictions as feedback to improve translation quality. CFM guides the system to eliminate undesired model behaviors from these predictions through a contrastive objective. The experiments on 3 state-of-the-art decision policies across 8 languages in the MuST-C v1.0 dataset show that CFM effectively improves the performance of SST.
NAIST Simultaneous Speech Translation System for IWSLT 2024
Jun 30, 2024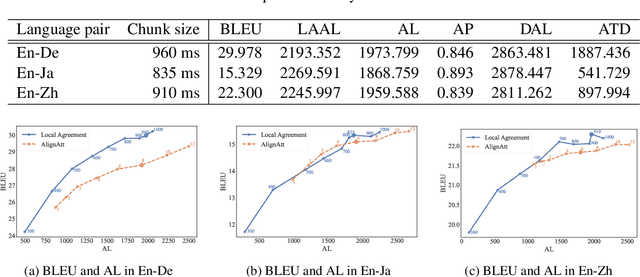
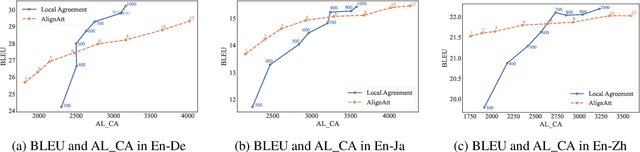


This paper describes NAIST's submission to the simultaneous track of the IWSLT 2024 Evaluation Campaign: English-to-{German, Japanese, Chinese} speech-to-text translation and English-to-Japanese speech-to-speech translation. We develop a multilingual end-to-end speech-to-text translation model combining two pre-trained language models, HuBERT and mBART. We trained this model with two decoding policies, Local Agreement (LA) and AlignAtt. The submitted models employ the LA policy because it outperformed the AlignAtt policy in previous models. Our speech-to-speech translation method is a cascade of the above speech-to-text model and an incremental text-to-speech (TTS) module that incorporates a phoneme estimation model, a parallel acoustic model, and a parallel WaveGAN vocoder. We improved our incremental TTS by applying the Transformer architecture with the AlignAtt policy for the estimation model. The results show that our upgraded TTS module contributed to improving the system performance.