 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAIST Simultaneous Speech Translation System for IWSLT 2024
Jun 30, 2024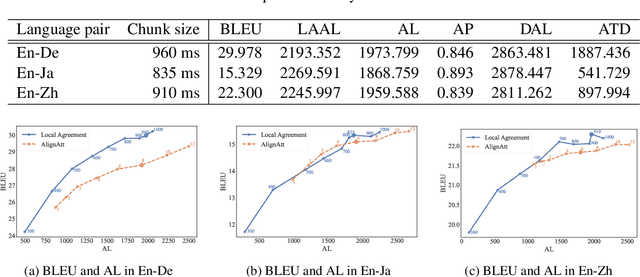


This paper describes NAIST's submission to the simultaneous track of the IWSLT 2024 Evaluation Campaign: English-to-{German, Japanese, Chinese} speech-to-text translation and English-to-Japanese speech-to-speech translation. We develop a multilingual end-to-end speech-to-text translation model combining two pre-trained language models, HuBERT and mBART. We trained this model with two decoding policies, Local Agreement (LA) and AlignAtt. The submitted models employ the LA policy because it outperformed the AlignAtt policy in previous models. Our speech-to-speech translation method is a cascade of the above speech-to-text model and an incremental text-to-speech (TTS) module that incorporates a phoneme estimation model, a parallel acoustic model, and a parallel WaveGAN vocoder. We improved our incremental TTS by applying the Transformer architecture with the AlignAtt policy for the estimation model. The results show that our upgraded TTS module contributed to improving the system performance.
Average Token Delay: A Duration-aware Latency Metric for Simultaneous Translation
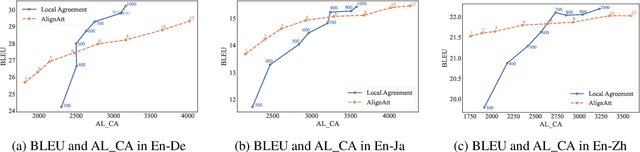
Nov 27, 2023Simultaneous translation is a task in which the translation begins before the end of an input speech segment. Its evaluation should be conducted based on latency in addition to quality, and for users, the smallest possible amount of latency is preferable. Most existing metrics measure latency based on the start timings of partial translations and ignore their duration. This means such metrics do not penalize the latency caused by long translation output, which delays the comprehension of users and subsequent translations. In this work, we propose a novel latency evaluation metric for simultaneous translation called \emph{Average Token Delay} (ATD) that focuses on the duration of partial translations. We demonstrate its effectiveness through analyses simulating user-side latency based on Ear-Voice Span (EVS). In our experiment, ATD had the highest correlation with EVS among baseline latency metrics under most conditions.
Tagged End-to-End Simultaneous Speech Translation Training using Simultaneous Interpretation Data
Jun 14, 2023



Simultaneous speech translation (SimulST) translates partial speech inputs incrementally. Although the monotonic correspondence between input and output is preferable for smaller latency, it is not the case for distant language pairs such as English and Japanese. A prospective approach to this problem is to mimic simultaneous interpretation (SI) using SI data to train a SimulST model. However, the size of such SI data is limited, so the SI data should be used together with ordinary bilingual data whose translations are given in offline. In this paper, we propose an effective way to train a SimulST model using mixed data of SI and offline. The proposed method trains a single model using the mixed data with style tags that tell the model to generate SI- or offline-style outputs. Experiment results show improvements of BLEURT in different latency ranges, and our analyses revealed the proposed model generates SI-style outputs more than the baseline.
Average Token Delay: A Latency Metric for Simultaneous Translation
Nov 22, 2022Simultaneous translation is a task in which translation begins before the speaker has finished speaking. In its evaluation, we have to consider the latency of the translation in addition to the quality. The latency is preferably as small as possible for users to comprehend what the speaker says with a small delay. Existing latency metrics focus on when the translation starts but do not consider adequately when the translation ends. This means such metrics do not penalize the latency caused by a long translation output, which actually delays users' comprehension. In this work, we propose a novel latency evaluation metric called Average Token Delay (ATD) that focuses on the end timings of partial translations in simultaneous translation. We discuss the advantage of ATD using simulated examples and also investigate the differences between ATD and Average Lagging with simultaneous translation experiments.
Simultaneous Neural Machine Translation with Constituent Label Prediction
Oct 26, 2021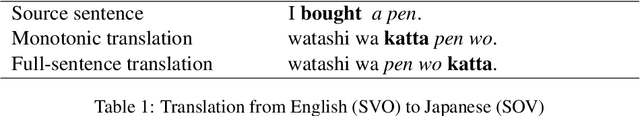
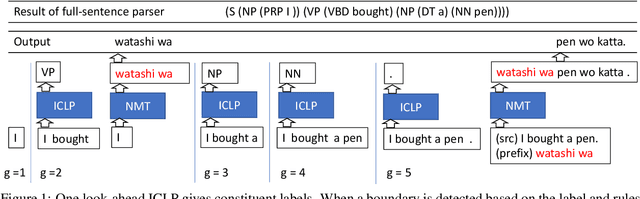
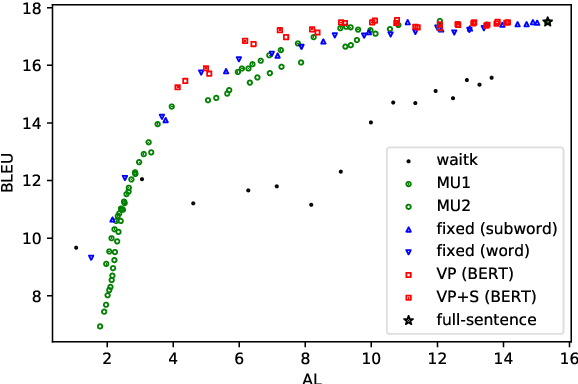

Simultaneous translation is a task in which translation begins before the speaker has finished speaking, so it is important to decide when to start the translation process. However, deciding whether to read more input words or start to translate is difficult for language pairs with different word orders such as English and Japanese. Motivated by the concept of pre-reordering, we propose a couple of simple decision rules using the label of the next constituent predicted by incremental constituent label prediction. In experiments on English-to-Japanese simultaneous translation, the proposed method outperformed baselines in the quality-latency trade-off.