 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASTELLA: Long Audio Dataset with Captions and Temporal Boundaries
Nov 19, 2025We introduce CASTELLA, a human-annotated audio benchmark for the task of audio moment retrieval (AMR). Although AMR has various useful potential applications, there is still no established benchmark with real-world data. The early study of AMR trained the model with solely synthetic datasets. Moreover, the evaluation is based on annotated dataset of fewer than 100 samples. This resulted in less reliable reported performance. To ensure performance for applications in real-world environments, we present CASTELLA, a large-scale manually annotated AMR dataset. CASTELLA consists of 1,009, 213, and 640 audio recordings for train, valid, and test split, respectively, which is 24 times larger than the previous dataset. We also establish a baseline model for AMR using CASTELLA. Our experiments demonstrate that a model fine-tuned on CASTELLA after pre-training on the synthetic data outperformed a model trained solely on the synthetic data by 10.4 points in Recall1@0.7. CASTELLA is publicly available in https://h-munakata.github.io/CASTELLA-demo/.
Language-Guided Contrastive Audio-Visual Masked Autoencoder with Automatically Generated Audio-Visual-Text Triplets from Videos
Jul 16, 2025
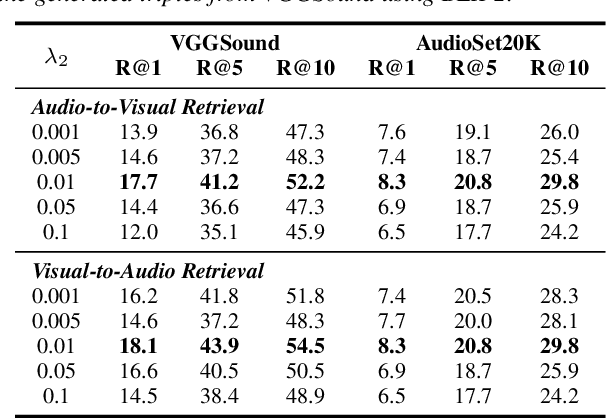
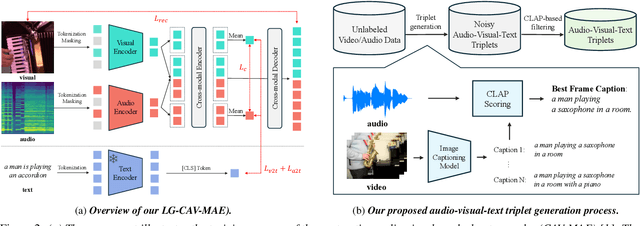

In this paper, we propose Language-Guided Contrastive Audio-Visual Masked Autoencoders (LG-CAV-MAE) to improve audio-visual representation learning. LG-CAV-MAE integrates a pretrained text encoder into contrastive audio-visual masked autoencoders, enabling the model to learn across audio, visual and text modalities. To train LG-CAV-MAE, we introduce an automatic method to generate audio-visual-text triplets from unlabeled videos. We first generate frame-level captions using an image captioning model and then apply CLAP-based filtering to ensure strong alignment between audio and captions. This approach yields high-quality audio-visual-text triplets without requiring manual annotations. We evaluate LG-CAV-MAE on audio-visual retrieval tasks, as well as an audio-visual classification task. Our method significantly outperforms existing approaches, achieving up to a 5.6% improvement in recall@10 for retrieval tasks and a 3.2% improvement for the classification task.
Self-supervised learning method using multiple sampling strategies for general-purpose audio representation
May 25, 2025


We propose a self-supervised learning method using multiple sampling strategies to obtain general-purpose audio representation. Multiple sampling strategies are used in the proposed method to construct contrastive losses from different perspectives and learn representations based on them. In this study, in addition to the widely used clip-level sampling strategy, we introduce two new strategies, a frame-level strategy and a task-specific strategy. The proposed multiple strategies improve the performance of frame-level classification and other tasks like pitch detection, which are not the focus of the conventional single clip-level sampling strategy. We pre-trained the method on a subset of Audioset and applied it to a downstream task with frozen weights. The proposed method improved clip classification, sound event detection, and pitch detection performance by 25%, 20%, and 3.6%.
Music Tagging with Classifier Group Chains
Jan 09, 2025



We propose music tagging with classifier chains that model the interplay of music tags. Most conventional methods estimate multiple tags independently by treating them as multiple independent binary classification problems. This treatment overlooks the conditional dependencies among music tags, leading to suboptimal tagging performance. Unlike most music taggers, the proposed method sequentially estimates each tag based on the idea of the classifier chains. Beyond the naive classifier chains, the proposed method groups the multiple tags by category, such as genre, and performs chains by unit of groups, which we call \textit{classifier group chains}. Our method allows the modeling of the dependence between tag groups. We evaluate the effectiveness of the proposed method for music tagging performance through music tagging experiments using the MTG-Jamendo dataset. Furthermore, we investigate the effective order of chains for music tagging.
Pre-training with Synthetic Patterns for Audio
Oct 01, 2024
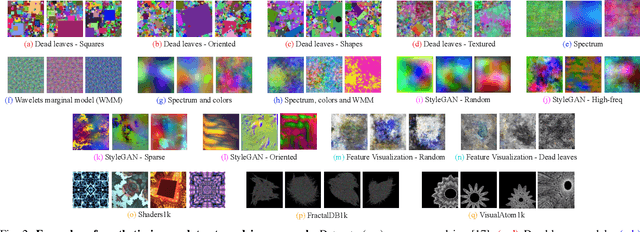

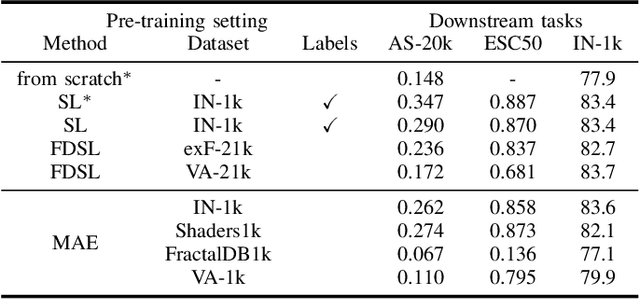
In this paper, we propose to pre-train audio encoders using synthetic patterns instead of real audio data. Our proposed framework consists of two key elements. The first one is Masked Autoencoder (MAE), a self-supervised learning framework that learns from reconstructing data from randomly masked counterparts. MAEs tend to focus on low-level information such as visual patterns and regularities within data. Therefore, it is unimportant what is portrayed in the input, whether it be images, audio mel-spectrograms, or even synthetic patterns. This leads to the second key element, which is synthetic data. Synthetic data, unlike real audio, is free from privacy and licensing infringement issues. By combining MAEs and synthetic patterns, our framework enables the model to learn generalized feature representations without real data, while addressing the issues related to real audio. To evaluate the efficacy of our framework, we conduct extensive experiments across a total of 13 audio tasks and 17 synthetic datasets. The experiments provide insights into which types of synthetic patterns are effective for audio. Our results demonstrate that our framework achieves performance comparable to models pre-trained on AudioSet-2M and partially outperforms image-based pre-training methods.
DETECLAP: Enhancing Audio-Visual Representation Learning with Object Information
Sep 18, 2024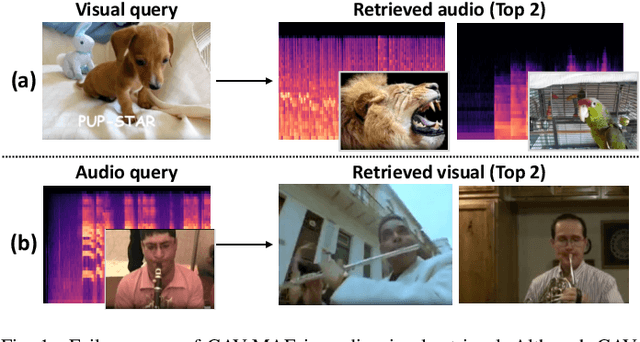
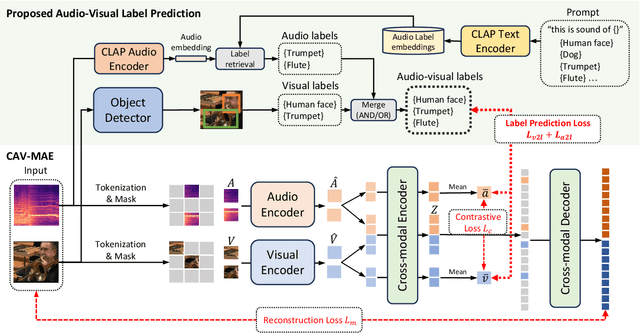
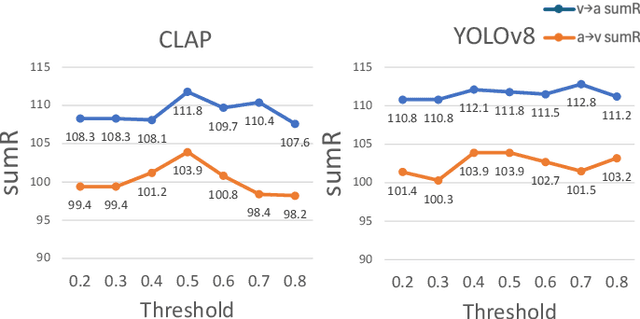

Current audio-visual representation learning can capture rough object categories (e.g., ``animals'' and ``instruments''), but it lacks the ability to recognize fine-grained details, such as specific categories like ``dogs'' and ``flutes'' within animals and instruments. To address this issue, we introduce DETECLAP, a method to enhance audio-visual representation learning with object information. Our key idea is to introduce an audio-visual label prediction loss to the existing Contrastive Audio-Visual Masked AutoEncoder to enhance its object awareness. To avoid costly manual annotations, we prepare object labels from both audio and visual inputs using state-of-the-art language-audio models and object detectors. We evaluate the method of audio-visual retrieval and classification using the VGGSound and AudioSet20K datasets. Our method achieves improvements in recall@10 of +1.5% and +1.2% for audio-to-visual and visual-to-audio retrieval, respectively, and an improvement in accuracy of +0.6% for audio-visual classification.
Lighthouse: A User-Friendly Library for Reproducible Video Moment Retrieval and Highlight Detection
Aug 06, 2024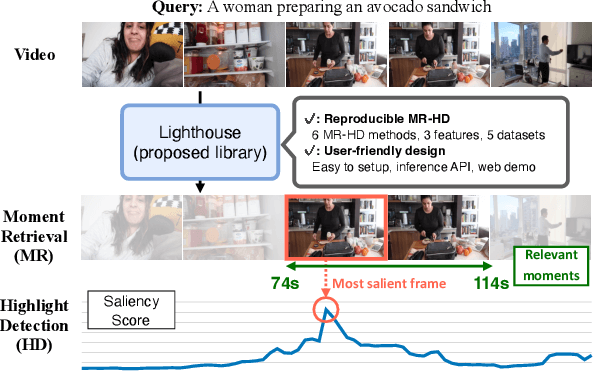


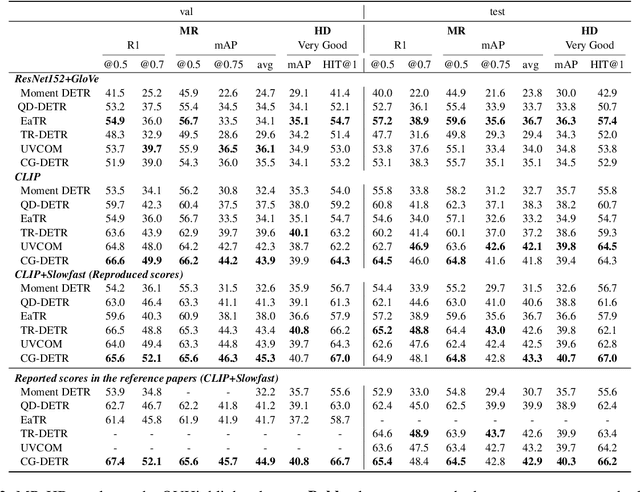
We propose Lighthouse, a user-friendly library for reproducible video moment retrieval and highlight detection (MR-HD). Although researchers proposed various MR-HD approaches, the research community holds two main issues. The first is a lack of comprehensive and reproducible experiments across various methods, datasets, and video-text features. This is because no unified training and evaluation codebase covers multiple settings. The second is user-unfriendly design. Because previous works use different libraries, researchers set up individual environments. In addition, most works release only the training codes, requiring users to implement the whole inference process of MR-HD. Lighthouse addresses these issues by implementing a unified reproducible codebase that includes six models, three features, and five datasets. In addition, it provides an inference API and web demo to make these methods easily accessible for researchers and developers. Our experiments demonstrate that Lighthouse generally reproduces the reported scores in the reference papers. The code is available at https://github.com/line/lighthouse.
Audio Fingerprinting with Holographic Reduced Representations
Jun 19, 2024



This paper proposes an audio fingerprinting model with holographic reduced representation (HRR). The proposed method reduces the number of stored fingerprints, whereas conventional neural audio fingerprinting requires many fingerprints for each audio track to achieve high accuracy and time resolution. We utilize HRR to aggregate multiple fingerprints into a composite fingerprint via circular convolution and summation, resulting in fewer fingerprints with the same dimensional space as the original. Our search method efficiently finds a combined fingerprint in which a query fingerprint exists. Using HRR's inverse operation, it can recover the relative position within a combined fingerprint, retaining the original time resolution. Experiments show that our method can reduce the number of fingerprints with modest accuracy degradation while maintaining the time resolution, outperforming simple decimation and summation-based aggregation methods.
Universal Score-based Speech Enhancement with High Content Preservation
Jun 18, 2024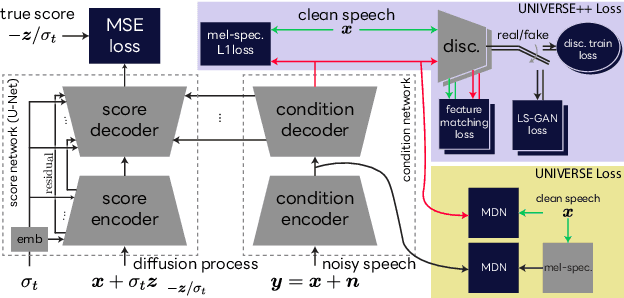
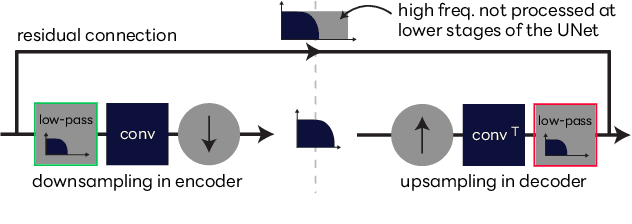
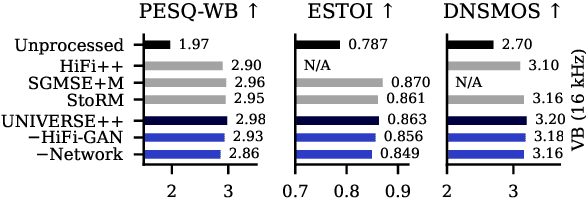
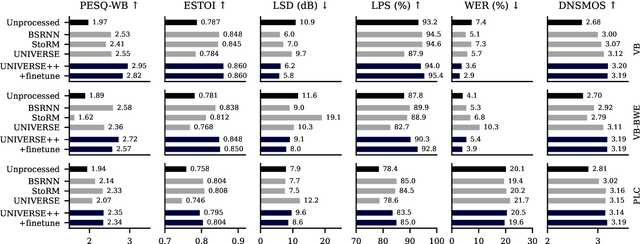
We propose UNIVERSE++, a universal speech enhancement method based on score-based diffusion and adversarial training. Specifically, we improve the existing UNIVERSE model that decouples clean speech feature extraction and diffusion. Our contributions are three-fold. First, we make several modifications to the network architecture, improving training stability and final performance. Second, we introduce an adversarial loss to promote learning high quality speech features. Third, we propose a low-rank adaptation scheme with a phoneme fidelity loss to improve content preservation in the enhanced speech. In the experiments, we train a universal enhancement model on a large scale dataset of speech degraded by noise, reverberation, and various distortions. The results on multiple public benchmark datasets demonstrate that UNIVERSE++ compares favorably to both discriminative and generative baselines for a wide range of qualitative and intelligibility metrics.
Keep Decoding Parallel with Effective Knowledge Distillation from Language Models to End-to-end Speech Recognisers
Jan 22, 2024



This study presents a novel approach for knowledge distillation (KD) from a BERT teacher model to an automatic speech recognition (ASR) model using intermediate layers. To distil the teacher's knowledge, we use an attention decoder that learns from BERT's token probabilities. Our method shows that language model (LM) information can be more effectively distilled into an ASR model using both the intermediate layers and the final layer. By using the intermediate layers as distillation target, we can more effectively distil LM knowledge into the lower network layers. Using our method, we achieve better recognition accuracy than with shallow fusion of an external LM, allowing us to maintain fast parallel decoding. Experiments on the LibriSpeech dataset demonstrate the effectiveness of our approach in enhancing greedy decoding with connectionist temporal classification (CTC).