 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDETECLAP: Enhancing Audio-Visual Representation Learning with Object Information
Paper and Code
Sep 18, 2024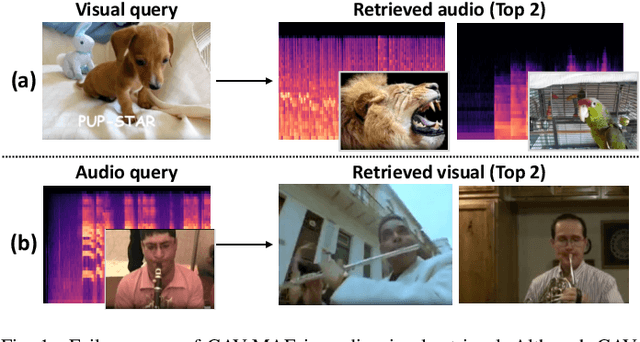
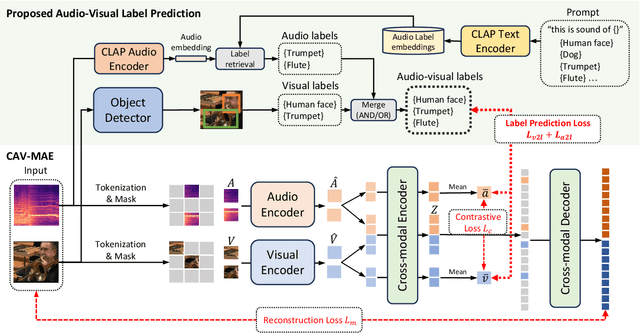
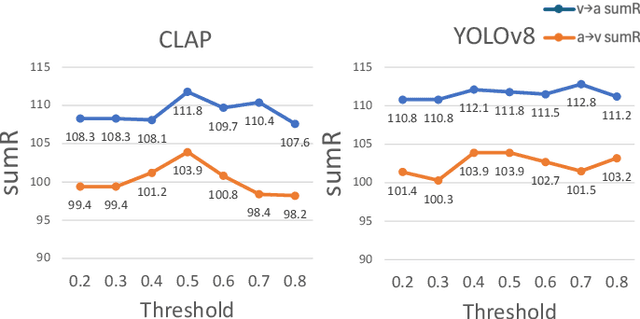

Current audio-visual representation learning can capture rough object categories (e.g., ``animals'' and ``instruments''), but it lacks the ability to recognize fine-grained details, such as specific categories like ``dogs'' and ``flutes'' within animals and instruments. To address this issue, we introduce DETECLAP, a method to enhance audio-visual representation learning with object information. Our key idea is to introduce an audio-visual label prediction loss to the existing Contrastive Audio-Visual Masked AutoEncoder to enhance its object awareness. To avoid costly manual annotations, we prepare object labels from both audio and visual inputs using state-of-the-art language-audio models and object detectors. We evaluate the method of audio-visual retrieval and classification using the VGGSound and AudioSet20K datasets. Our method achieves improvements in recall@10 of +1.5% and +1.2% for audio-to-visual and visual-to-audio retrieval, respectively, and an improvement in accuracy of +0.6% for audio-visual classification.