 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided Contrastive Audio-Visual Masked Autoencoder with Automatically Generated Audio-Visual-Text Triplets from Videos
Jul 16, 2025
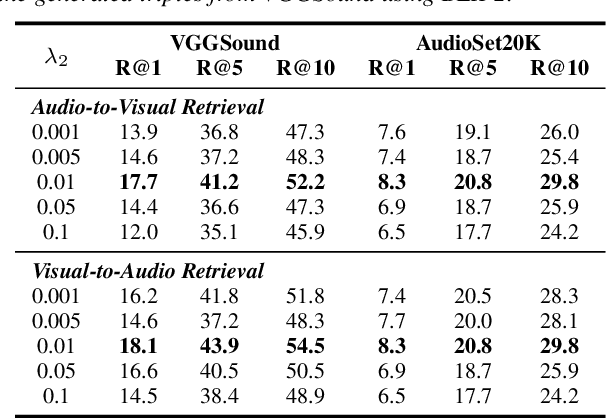

In this paper, we propose Language-Guided Contrastive Audio-Visual Masked Autoencoders (LG-CAV-MAE) to improve audio-visual representation learning. LG-CAV-MAE integrates a pretrained text encoder into contrastive audio-visual masked autoencoders, enabling the model to learn across audio, visual and text modalities. To train LG-CAV-MAE, we introduce an automatic method to generate audio-visual-text triplets from unlabeled videos. We first generate frame-level captions using an image captioning model and then apply CLAP-based filtering to ensure strong alignment between audio and captions. This approach yields high-quality audio-visual-text triplets without requiring manual annotations. We evaluate LG-CAV-MAE on audio-visual retrieval tasks, as well as an audio-visual classification task. Our method significantly outperforms existing approaches, achieving up to a 5.6% improvement in recall@10 for retrieval tasks and a 3.2% improvement for the classification task.
DETECLAP: Enhancing Audio-Visual Representation Learning with Object Information
Sep 18, 2024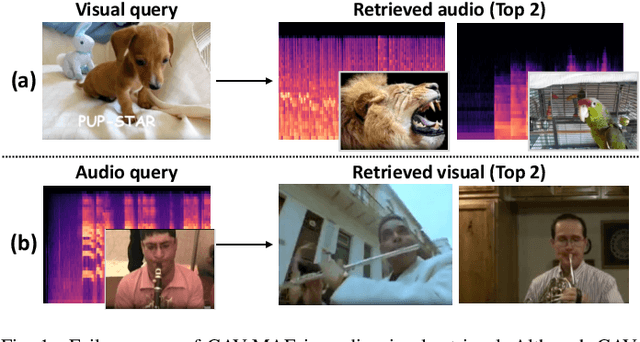
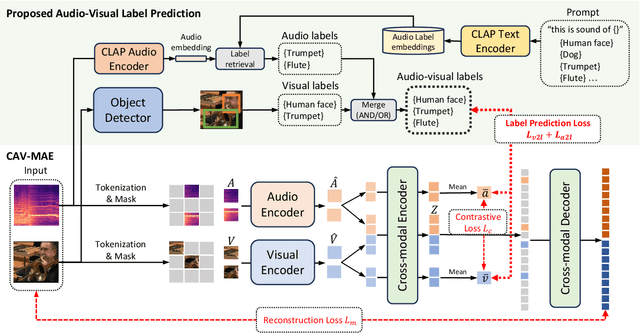
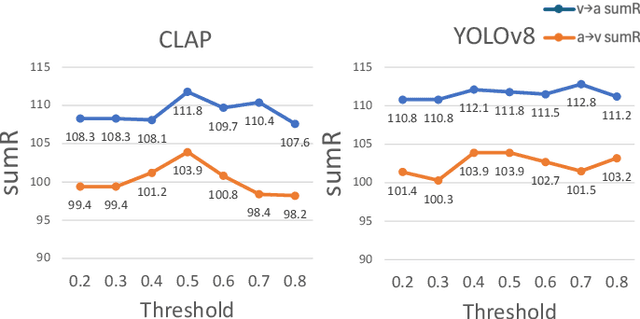

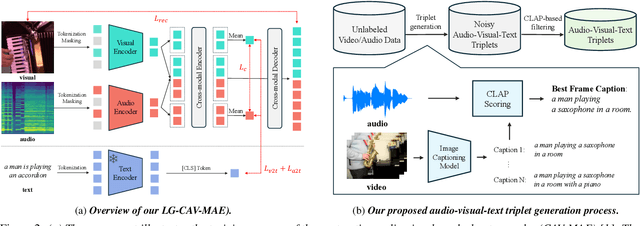
Current audio-visual representation learning can capture rough object categories (e.g., ``animals'' and ``instruments''), but it lacks the ability to recognize fine-grained details, such as specific categories like ``dogs'' and ``flutes'' within animals and instruments. To address this issue, we introduce DETECLAP, a method to enhance audio-visual representation learning with object information. Our key idea is to introduce an audio-visual label prediction loss to the existing Contrastive Audio-Visual Masked AutoEncoder to enhance its object awareness. To avoid costly manual annotations, we prepare object labels from both audio and visual inputs using state-of-the-art language-audio models and object detectors. We evaluate the method of audio-visual retrieval and classification using the VGGSound and AudioSet20K datasets. Our method achieves improvements in recall@10 of +1.5% and +1.2% for audio-to-visual and visual-to-audio retrieval, respectively, and an improvement in accuracy of +0.6% for audio-visual classification.
Lighthouse: A User-Friendly Library for Reproducible Video Moment Retrieval and Highlight Detection
Aug 06, 2024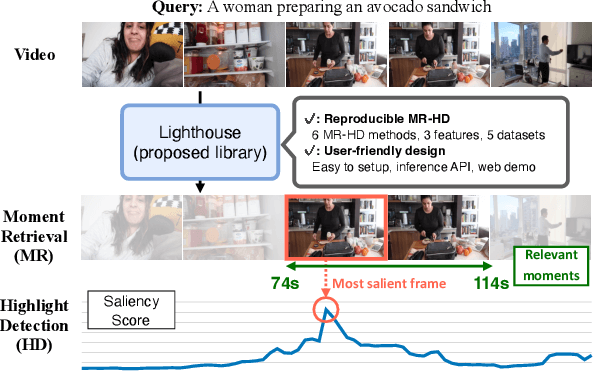


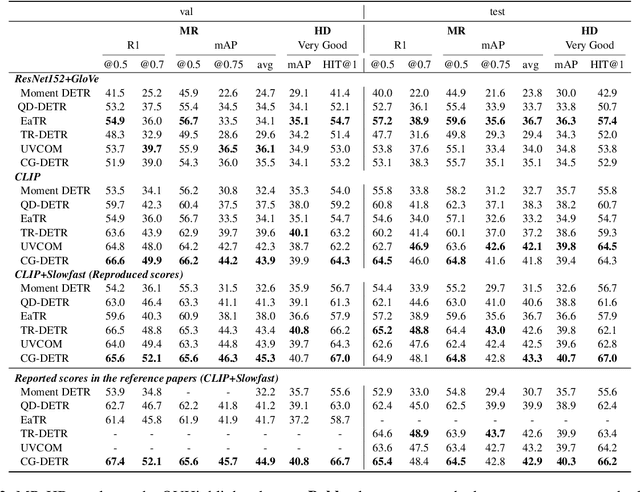
We propose Lighthouse, a user-friendly library for reproducible video moment retrieval and highlight detection (MR-HD). Although researchers proposed various MR-HD approaches, the research community holds two main issues. The first is a lack of comprehensive and reproducible experiments across various methods, datasets, and video-text features. This is because no unified training and evaluation codebase covers multiple settings. The second is user-unfriendly design. Because previous works use different libraries, researchers set up individual environments. In addition, most works release only the training codes, requiring users to implement the whole inference process of MR-HD. Lighthouse addresses these issues by implementing a unified reproducible codebase that includes six models, three features, and five datasets. In addition, it provides an inference API and web demo to make these methods easily accessible for researchers and developers. Our experiments demonstrate that Lighthouse generally reproduces the reported scores in the reference papers. The code is available at https://github.com/line/lighthouse.
On the Audio Hallucinations in Large Audio-Video Language Models
Jan 18, 2024Large audio-video language models can generate descriptions for both video and audio. However, they sometimes ignore audio content, producing audio descriptions solely reliant on visual information. This paper refers to this as audio hallucinations and analyzes them in large audio-video language models. We gather 1,000 sentences by inquiring about audio information and annotate them whether they contain hallucinations. If a sentence is hallucinated, we also categorize the type of hallucination. The results reveal that 332 sentences are hallucinated with distinct trends observed in nouns and verbs for each hallucination type. Based on this, we tackle a task of audio hallucination classification using pre-trained audio-text models in the zero-shot and fine-tuning settings. Our experimental results reveal that the zero-shot models achieve higher performance (52.2% in F1) than the random (40.3%) and the fine-tuning models achieve 87.9%, outperforming the zero-shot models.
Large-scale Vision-Language Models Learn Super Images for Efficient and High-Performance Partially Relevant Video Retrieval
Dec 01, 2023



In this paper, we propose an efficient and high-performance method for partially relevant video retrieval (PRVR), which aims to retrieve untrimmed long videos that contain at least one relevant moment to the input text query. In terms of both efficiency and performance, the overlooked bottleneck of previous studies is the visual encoding of dense frames. This guides researchers to choose lightweight visual backbones, yielding sub-optimal retrieval performance due to their limited capabilities of learned visual representations. However, it is undesirable to simply replace them with high-performance large-scale vision-and-language models (VLMs) due to their low efficiency. To address these issues, instead of dense frames, we focus on super images, which are created by rearranging the video frames in a $N \times N$ grid layout. This reduces the number of visual encodings to $\frac{1}{N^2}$ and compensates for the low efficiency of large-scale VLMs, allowing us to adopt them as powerful encoders. Surprisingly, we discover that with a simple query-image attention trick, VLMs generalize well to super images effectively and demonstrate promising zero-shot performance against SOTA methods efficiently. In addition, we propose a fine-tuning approach by incorporating a few trainable modules into the VLM backbones. The experimental results demonstrate that our approaches efficiently achieve the best performance on ActivityNet Captions and TVR.