 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASTELLA: Long Audio Dataset with Captions and Temporal Boundaries
Nov 19, 2025We introduce CASTELLA, a human-annotated audio benchmark for the task of audio moment retrieval (AMR). Although AMR has various useful potential applications, there is still no established benchmark with real-world data. The early study of AMR trained the model with solely synthetic datasets. Moreover, the evaluation is based on annotated dataset of fewer than 100 samples. This resulted in less reliable reported performance. To ensure performance for applications in real-world environments, we present CASTELLA, a large-scale manually annotated AMR dataset. CASTELLA consists of 1,009, 213, and 640 audio recordings for train, valid, and test split, respectively, which is 24 times larger than the previous dataset. We also establish a baseline model for AMR using CASTELLA. Our experiments demonstrate that a model fine-tuned on CASTELLA after pre-training on the synthetic data outperformed a model trained solely on the synthetic data by 10.4 points in Recall1@0.7. CASTELLA is publicly available in https://h-munakata.github.io/CASTELLA-demo/.
Developing Vision-Language-Action Model from Egocentric Videos
Sep 26, 2025Egocentric videos capture how humans manipulate objects and tools, providing diverse motion cues for learning object manipulation. Unlike the costly, expert-driven manual teleoperation commonly used in training Vision-Language-Action models (VLAs), egocentric videos offer a scalable alternative. However, prior studies that leverage such videos for training robot policies typically rely on auxiliary annotations, such as detailed hand-pose recordings. Consequently, it remains unclear whether VLAs can be trained directly from raw egocentric videos. In this work, we address this challenge by leveraging EgoScaler, a framework that extracts 6DoF object manipulation trajectories from egocentric videos without requiring auxiliary recordings. We apply EgoScaler to four large-scale egocentric video datasets and automatically refine noisy or incomplete trajectories, thereby constructing a new large-scale dataset for VLA pre-training. Our experiments with a state-of-the-art $\pi_0$ architecture in both simulated and real-robot environments yield three key findings: (i) pre-training on our dataset improves task success rates by over 20\% compared to training from scratch, (ii) the performance is competitive with that achieved using real-robot datasets, and (iii) combining our dataset with real-robot data yields further improvements. These results demonstrate that egocentric videos constitute a promising and scalable resource for advancing VLA research.
EgoOops: A Dataset for Mistake Action Detection from Egocentric Videos with Procedural Texts
Oct 07, 2024


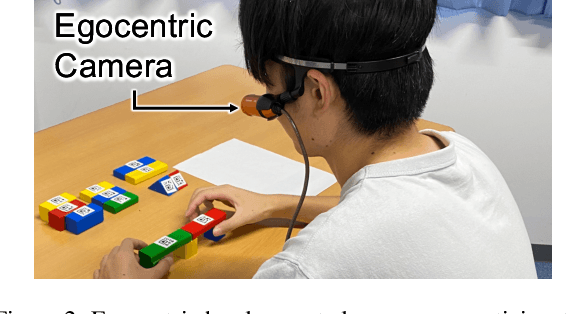
Mistake action detection from egocentric videos is crucial for developing intelligent archives that detect workers' errors and provide feedback. Previous studies have been limited to specific domains, focused on detecting mistakes from videos without procedural texts, and analyzed whether actions are mistakes. To address these limitations, in this paper, we propose the EgoOops dataset, which includes egocentric videos, procedural texts, and three types of annotations: video-text alignment, mistake labels, and descriptions for mistakes. EgoOops covers five procedural domains and includes 50 egocentric videos. The video-text alignment allows the model to detect mistakes based on both videos and procedural texts. The mistake labels and descriptions enable detailed analysis of real-world mistakes. Based on EgoOops, we tackle two tasks: video-text alignment and mistake detection. For video-text alignment, we enhance the recent StepFormer model with an additional loss for fine-tuning. Based on the alignment results, we propose a multi-modal classifier to predict mistake labels. In our experiments, the proposed methods achieve higher performance than the baselines. In addition, our ablation study demonstrates the effectiveness of combining videos and texts. We will release the dataset and codes upon publication.
DETECLAP: Enhancing Audio-Visual Representation Learning with Object Information
Sep 18, 2024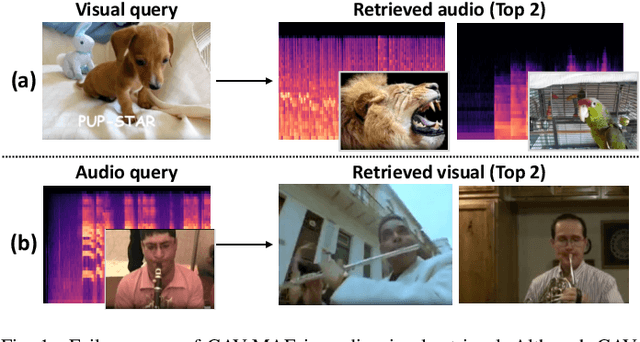
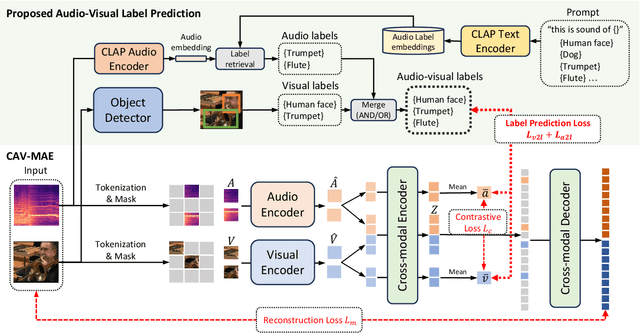
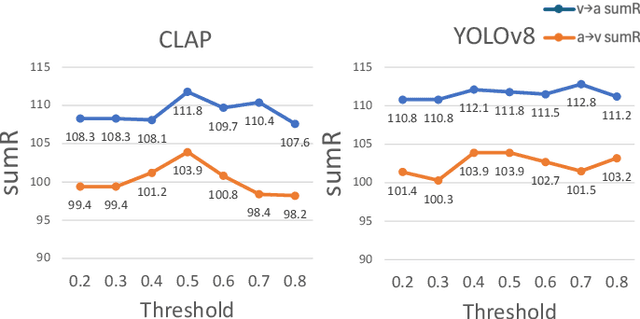

Current audio-visual representation learning can capture rough object categories (e.g., ``animals'' and ``instruments''), but it lacks the ability to recognize fine-grained details, such as specific categories like ``dogs'' and ``flutes'' within animals and instruments. To address this issue, we introduce DETECLAP, a method to enhance audio-visual representation learning with object information. Our key idea is to introduce an audio-visual label prediction loss to the existing Contrastive Audio-Visual Masked AutoEncoder to enhance its object awareness. To avoid costly manual annotations, we prepare object labels from both audio and visual inputs using state-of-the-art language-audio models and object detectors. We evaluate the method of audio-visual retrieval and classification using the VGGSound and AudioSet20K datasets. Our method achieves improvements in recall@10 of +1.5% and +1.2% for audio-to-visual and visual-to-audio retrieval, respectively, and an improvement in accuracy of +0.6% for audio-visual classification.
Lighthouse: A User-Friendly Library for Reproducible Video Moment Retrieval and Highlight Detection
Aug 06, 2024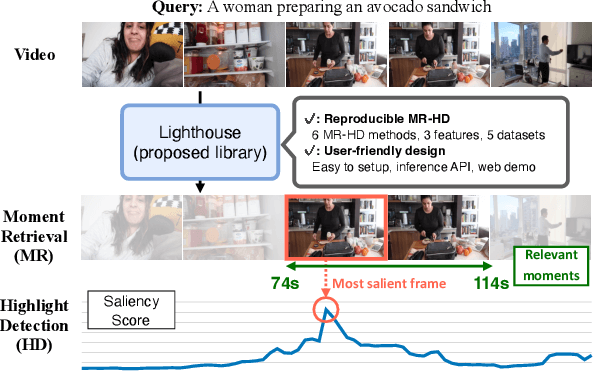


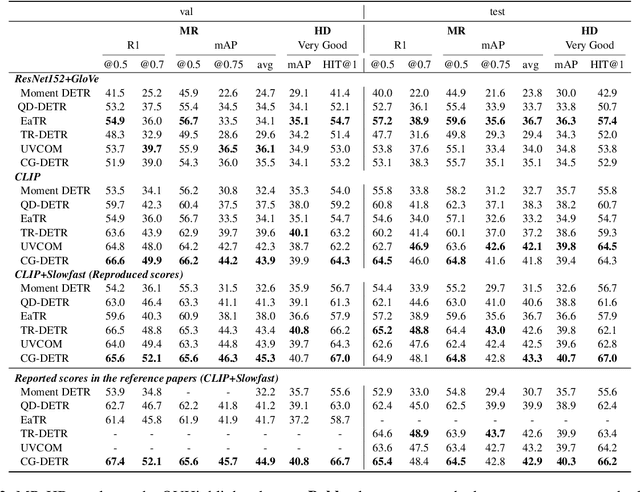
We propose Lighthouse, a user-friendly library for reproducible video moment retrieval and highlight detection (MR-HD). Although researchers proposed various MR-HD approaches, the research community holds two main issues. The first is a lack of comprehensive and reproducible experiments across various methods, datasets, and video-text features. This is because no unified training and evaluation codebase covers multiple settings. The second is user-unfriendly design. Because previous works use different libraries, researchers set up individual environments. In addition, most works release only the training codes, requiring users to implement the whole inference process of MR-HD. Lighthouse addresses these issues by implementing a unified reproducible codebase that includes six models, three features, and five datasets. In addition, it provides an inference API and web demo to make these methods easily accessible for researchers and developers. Our experiments demonstrate that Lighthouse generally reproduces the reported scores in the reference papers. The code is available at https://github.com/line/lighthouse.
BioVL-QR: Egocentric Biochemical Video-and-Language Dataset Using Micro QR Codes
Apr 04, 2024This paper introduces a biochemical vision-and-language dataset, which consists of 24 egocentric experiment videos, corresponding protocols, and video-and-language alignments. The key challenge in the wet-lab domain is detecting equipment, reagents, and containers is difficult because the lab environment is scattered by filling objects on the table and some objects are indistinguishable. Therefore, previous studies assume that objects are manually annotated and given for downstream tasks, but this is costly and time-consuming. To address this issue, this study focuses on Micro QR Codes to detect objects automatically. From our preliminary study, we found that detecting objects only using Micro QR Codes is still difficult because the researchers manipulate objects, causing blur and occlusion frequently. To address this, we also propose a novel object labeling method by combining a Micro QR Code detector and an off-the-shelf hand object detector. As one of the applications of our dataset, we conduct the task of generating protocols from experiment videos and find that our approach can generate accurate protocols.
Text-driven Affordance Learning from Egocentric Vision
Apr 03, 2024Visual affordance learning is a key component for robots to understand how to interact with objects. Conventional approaches in this field rely on pre-defined objects and actions, falling short of capturing diverse interactions in realworld scenarios. The key idea of our approach is employing textual instruction, targeting various affordances for a wide range of objects. This approach covers both hand-object and tool-object interactions. We introduce text-driven affordance learning, aiming to learn contact points and manipulation trajectories from an egocentric view following textual instruction. In our task, contact points are represented as heatmaps, and the manipulation trajectory as sequences of coordinates that incorporate both linear and rotational movements for various manipulations. However, when we gather data for this task, manual annotations of these diverse interactions are costly. To this end, we propose a pseudo dataset creation pipeline and build a large pseudo-training dataset: TextAFF80K, consisting of over 80K instances of the contact points, trajectories, images, and text tuples. We extend existing referring expression comprehension models for our task, and experimental results show that our approach robustly handles multiple affordances, serving as a new standard for affordance learning in real-world scenarios.
Automatic Construction of a Large-Scale Corpus for Geoparsing Using Wikipedia Hyperlinks
Mar 25, 2024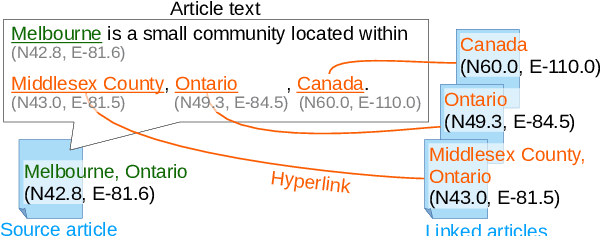
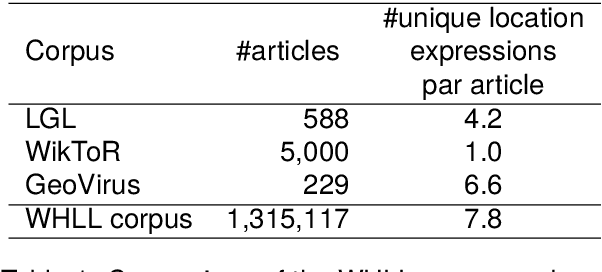

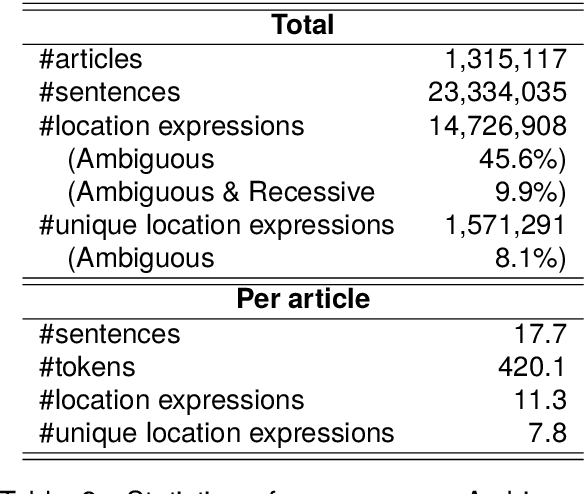
Geoparsing is the task of estimating the latitude and longitude (coordinates) of location expressions in texts. Geoparsing must deal with the ambiguity of the expressions that indicate multiple locations with the same notation. For evaluating geoparsing systems, several corpora have been proposed in previous work. However, these corpora are small-scale and suffer from the coverage of location expressions on general domains. In this paper, we propose Wikipedia Hyperlink-based Location Linking (WHLL), a novel method to construct a large-scale corpus for geoparsing from Wikipedia articles. WHLL leverages hyperlinks in Wikipedia to annotate multiple location expressions with coordinates. With this method, we constructed the WHLL corpus, a new large-scale corpus for geoparsing. The WHLL corpus consists of 1.3M articles, each containing about 7.8 unique location expressions. 45.6% of location expressions are ambiguous and refer to more than one location with the same notation. In each article, location expressions of the article title and those hyperlinks to other articles are assigned with coordinates. By utilizing hyperlinks, we can accurately assign location expressions with coordinates even with ambiguous location expressions in the texts. Experimental results show that there remains room for improvement by disambiguating location expressions.
On the Audio Hallucinations in Large Audio-Video Language Models
Jan 18, 2024Large audio-video language models can generate descriptions for both video and audio. However, they sometimes ignore audio content, producing audio descriptions solely reliant on visual information. This paper refers to this as audio hallucinations and analyzes them in large audio-video language models. We gather 1,000 sentences by inquiring about audio information and annotate them whether they contain hallucinations. If a sentence is hallucinated, we also categorize the type of hallucination. The results reveal that 332 sentences are hallucinated with distinct trends observed in nouns and verbs for each hallucination type. Based on this, we tackle a task of audio hallucination classification using pre-trained audio-text models in the zero-shot and fine-tuning settings. Our experimental results reveal that the zero-shot models achieve higher performance (52.2% in F1) than the random (40.3%) and the fine-tuning models achieve 87.9%, outperforming the zero-shot models.
Large-scale Vision-Language Models Learn Super Images for Efficient and High-Performance Partially Relevant Video Retrieval
Dec 01, 2023



In this paper, we propose an efficient and high-performance method for partially relevant video retrieval (PRVR), which aims to retrieve untrimmed long videos that contain at least one relevant moment to the input text query. In terms of both efficiency and performance, the overlooked bottleneck of previous studies is the visual encoding of dense frames. This guides researchers to choose lightweight visual backbones, yielding sub-optimal retrieval performance due to their limited capabilities of learned visual representations. However, it is undesirable to simply replace them with high-performance large-scale vision-and-language models (VLMs) due to their low efficiency. To address these issues, instead of dense frames, we focus on super images, which are created by rearranging the video frames in a $N \times N$ grid layout. This reduces the number of visual encodings to $\frac{1}{N^2}$ and compensates for the low efficiency of large-scale VLMs, allowing us to adopt them as powerful encoders. Surprisingly, we discover that with a simple query-image attention trick, VLMs generalize well to super images effectively and demonstrate promising zero-shot performance against SOTA methods efficiently. In addition, we propose a fine-tuning approach by incorporating a few trainable modules into the VLM backbones. The experimental results demonstrate that our approaches efficiently achieve the best performance on ActivityNet Captions and TVR.